From Charts to Code: A Hierarchical Benchmark for Multimodal Models
作者: Jiahao Tang, Henry Hengyuan Zhao, Lijian Wu, Yifei Tao, Dongxing Mao, Yang Wan, Jingru Tan, Min Zeng, Min Li, Alex Jinpeng Wang
分类: cs.SE, cs.AI
发布日期: 2025-10-20 (更新: 2026-01-21)
💡 一句话要点
提出Chart2Code分层基准,评估多模态模型在图表理解与代码生成能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 图表理解 代码生成 基准测试 分层任务 视觉保真度 长表转换 用户驱动设计
📋 核心要点
- 现有方法在图表理解和代码生成方面存在不足,缺乏系统性的评估基准来衡量多模态模型的能力。
- Chart2Code通过分层任务设计,从图表复现、编辑到长表生成,逐步增加难度,更贴近实际应用场景。
- 实验结果表明,即使是最先进的模型在Chart2Code基准上表现仍有提升空间,证明了该基准的挑战性。
📝 摘要(中文)
本文提出了Chart2Code,一个用于评估大型多模态模型(LMMs)图表理解和代码生成能力的新基准。Chart2Code从用户驱动的角度显式设计,捕捉了多样化的真实场景,并逐步增加任务难度。它包含三个层级:第一级(图表复现)从参考图和用户查询中复现图表;第二级(图表编辑)涉及复杂的修改,例如更改图表类型或添加元素;第三级(长表到图表生成)要求模型根据用户指令将信息密集的长表转换为忠实的图表。据我们所知,这是第一个反映实际chart2code使用情况并系统地扩展任务复杂性的分层基准。Chart2Code总共包含2,023个任务,涵盖22种图表类型,并配有多层次的评估指标,用于评估代码正确性和渲染图表的视觉保真度。我们对25个最先进的(SoTA)LMM进行了基准测试,包括专有模型和最新的开源模型,如GPT-5、Qwen2.5-VL、InternVL3/3.5、MiMo-VL和Seed-1.6-VL。实验结果表明,即使是SoTA模型GPT-5在基于代码的评估中平均只有0.57分,在图表质量评估中平均只有0.22分,这突显了Chart2Code的难度。我们预计这个基准将推动多模态推理的进步,并促进更强大和通用的LMM的开发。我们的代码和数据可在Chart2Code上找到。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型在图表理解和代码生成方面的评估问题。现有方法缺乏一个全面、分层且贴近实际应用的基准,难以有效衡量模型在不同复杂程度任务上的表现。现有基准可能无法充分反映真实世界中图表生成和编辑的需求,例如从长表中生成图表或进行复杂的图表修改。
核心思路:论文的核心思路是构建一个分层的基准测试集,该测试集从简单到复杂,逐步增加任务的难度。这种分层结构允许更细粒度的评估,并能更好地反映模型在不同能力水平上的表现。通过模拟真实世界的使用场景,例如图表复现、编辑和从长表中生成图表,该基准旨在更准确地评估模型的实际应用能力。
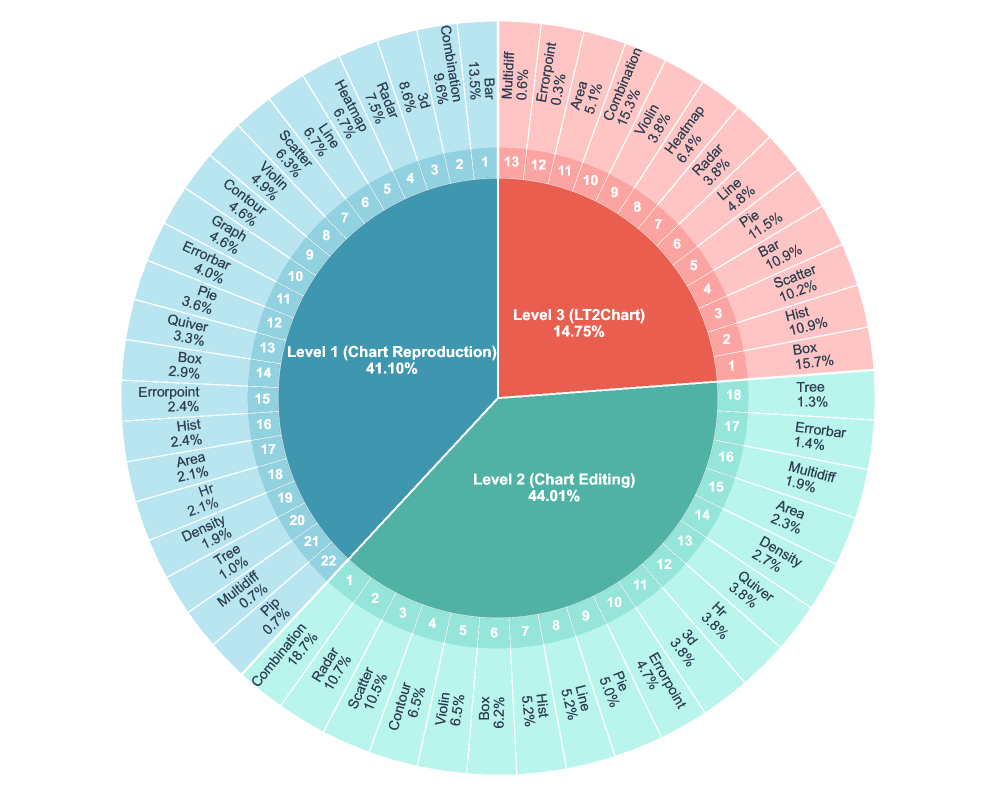
技术框架:Chart2Code基准包含三个主要层级:Level 1 (Chart Reproduction),Level 2 (Chart Editing),和 Level 3 (Long-Table to Chart Generation)。每个层级都包含多个任务,涵盖22种不同的图表类型。评估指标包括基于代码的评估(例如代码正确性)和基于图表质量的评估(例如视觉保真度)。该基准还提供了一套评估工具,用于自动评估模型的性能。
关键创新:Chart2Code的关键创新在于其分层结构和用户驱动的设计。与现有的基准相比,Chart2Code更注重模拟真实世界的使用场景,并提供更细粒度的评估。此外,该基准还包含了从长表中生成图表的任务,这在现有的基准中是比较少见的。
关键设计:Chart2Code的关键设计包括任务难度的分层设置、多样化的图表类型选择、以及多层次的评估指标。任务难度分层确保了基准能够评估模型在不同能力水平上的表现。多样化的图表类型覆盖了常见的图表应用场景。多层次的评估指标则从代码和图表两个方面综合评估模型的性能。具体的参数设置、损失函数和网络结构取决于被评估的模型,Chart2Code主要提供评估框架和数据集。
🖼️ 关键图片

📊 实验亮点
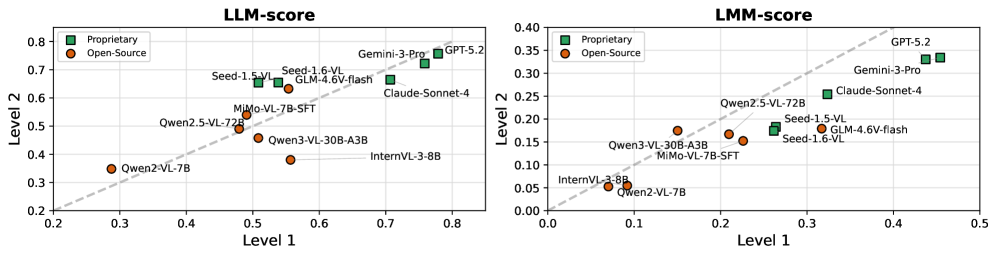
实验结果显示,即使是最先进的GPT-5模型在Chart2Code的图表编辑任务中,基于代码的评估得分仅为0.57,图表质量评估得分仅为0.22。这表明现有模型在处理复杂的图表理解和代码生成任务时仍面临挑战,突显了Chart2Code基准的难度和价值。其他开源模型如Qwen2.5-VL、InternVL3/3.5、MiMo-VL和Seed-1.6-VL也进行了基准测试,为后续研究提供了参考。
🎯 应用场景
Chart2Code基准的潜在应用领域包括数据可视化、商业智能、教育和科学研究。它可以用于评估和比较不同多模态模型在图表理解和代码生成方面的能力,从而促进相关技术的发展。此外,该基准还可以用于开发更智能的数据分析工具,帮助用户更有效地从数据中提取信息。
📄 摘要(原文)
We introduce Chart2Code, a new benchmark for evaluating the chart understanding and code generation capabilities of large multimodal models (LMMs). Chart2Code is explicitly designed from a user-driven perspective, capturing diverse real-world scenarios and progressively increasing task difficulty. It consists of three levels: Level 1 (Chart Reproduction) reproduces charts from a reference figure and user query; Level 2 (Chart Editing) involves complex modifications such as changing chart types or adding elements; and Level 3 (Long-Table to Chart Generation) requires models to transform long, information-dense tables into faithful charts following user instructions. To our knowledge, this is the first hierarchical benchmark that reflects practical chart2code usage while systematically scaling task complexity. In total, Chart2Code contains 2,023 tasks across 22 chart types, paired with multi-level evaluation metrics that assess both code correctness and the visual fidelity of rendered charts. We benchmark 25 state-of-the-art (SoTA) LMMs, including both proprietary and the latest open-source models such as GPT-5, Qwen2.5-VL, InternVL3/3.5, MiMo-VL, and Seed-1.6-VL. Experimental results demonstrate that even the SoTA model GPT-5 averages only 0.57 on code-based evaluation and 0.22 on chart-quality assessment across the editing tasks, underscoring the difficulty of Chart2Code. We anticipate this benchmark will drive advances in multimodal reasoning and foster the development of more robust and general-purpose LMMs. Our code and data are available on Chart2Code.