SpecAgent: A Speculative Retrieval and Forecasting Agent for Code Completion
作者: George Ma, Anurag Koul, Qi Chen, Yawen Wu, Sachit Kuhar, Yu Yu, Aritra Sengupta, Varun Kumar, Murali Krishna Ramanathan
分类: cs.SE, cs.AI
发布日期: 2025-10-20
💡 一句话要点
SpecAgent:一种用于代码补全的推测性检索和预测Agent,提升代码生成质量并降低延迟。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码补全 大型语言模型 检索增强 推测执行 软件仓库
📋 核心要点
- 现有代码补全方法在处理大型软件仓库时,由于项目API和跨文件依赖关系,面临检索质量和推理延迟的挑战。
- SpecAgent通过在索引阶段主动探索代码仓库,构建推测性上下文,预测未来编辑,从而提升代码生成质量并降低延迟。
- 实验表明,SpecAgent在代码补全任务中,相比现有最佳方法,性能提升9-11%,同时显著降低了推理延迟。
📝 摘要(中文)
大型语言模型(LLMs)在代码相关任务中表现出色,但通常在实际软件仓库中表现不佳,因为项目特定的API和跨文件依赖关系至关重要。检索增强方法通过在推理时注入仓库上下文来缓解这个问题。然而,低推理时延迟预算会影响检索质量,或者增加的延迟会对用户体验产生不利影响。我们提出了SpecAgent,它通过在索引期间主动探索仓库文件并构建推测性上下文来预测每个文件中未来的编辑,从而提高延迟和代码生成质量。这种索引时异步性允许彻底的上下文计算,掩盖延迟,并且上下文的推测性提高了代码生成质量。此外,我们发现现有基准测试中存在未来上下文泄露的问题,这可能会夸大报告的性能。为了解决这个问题,我们构建了一个合成的、无泄露的基准测试,可以更真实地评估我们的Agent与基线相比的性能。实验表明,与性能最佳的基线相比,SpecAgent始终实现9-11%的绝对收益(48-58%的相对收益),同时显着降低了推理延迟。
🔬 方法详解
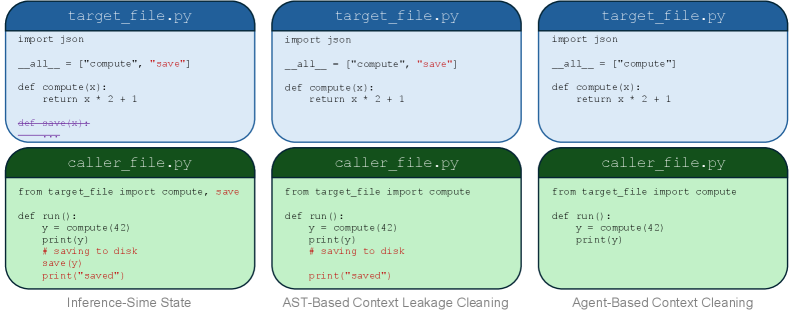
问题定义:现有代码补全方法,特别是基于大型语言模型的方法,在处理真实软件仓库时面临挑战。由于项目特定的API和跨文件依赖关系复杂,简单的检索增强方法要么牺牲检索质量以满足低延迟需求,要么引入过高的延迟影响用户体验。此外,现有基准测试可能存在未来上下文泄露的问题,导致评估结果不准确。
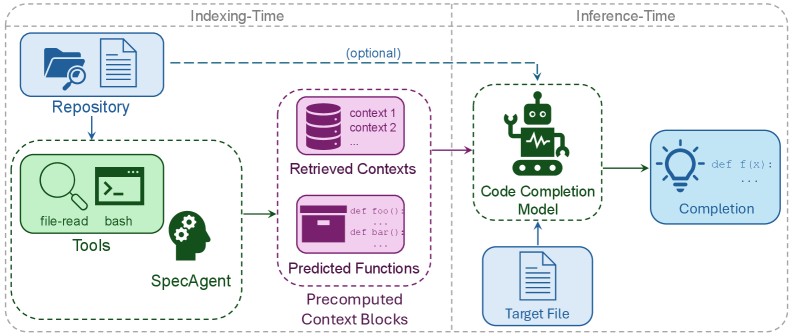
核心思路:SpecAgent的核心思路是在索引阶段进行主动和推测性的上下文构建,从而将耗时的上下文计算从推理阶段转移到索引阶段,实现异步处理。通过预测未来可能的代码编辑,构建推测性上下文,提高代码补全的准确性。这种设计旨在解决检索质量和推理延迟之间的trade-off,并提供更真实的评估基准。
技术框架:SpecAgent包含两个主要阶段:索引阶段和推理阶段。在索引阶段,SpecAgent主动探索代码仓库,分析文件之间的依赖关系,并构建推测性上下文。这些上下文被存储起来,以便在推理阶段快速检索。在推理阶段,SpecAgent根据当前的代码上下文,检索相关的推测性上下文,并将其输入到大型语言模型中进行代码补全。整体流程旨在通过预先计算和推测来减少推理延迟并提高代码生成质量。
关键创新:SpecAgent的关键创新在于其推测性上下文构建方法和索引时异步处理机制。传统的检索增强方法在推理时才进行上下文检索,而SpecAgent则在索引时预先计算并存储上下文,从而显著降低了推理延迟。此外,通过预测未来可能的代码编辑,SpecAgent构建的推测性上下文能够更好地捕捉代码的语义信息,提高代码补全的准确性。
关键设计:SpecAgent的具体技术细节包括:用于预测未来代码编辑的算法(具体算法未知),用于构建和存储推测性上下文的数据结构(具体数据结构未知),以及用于在推理阶段检索相关上下文的检索策略(具体策略未知)。此外,SpecAgent还引入了一种新的合成基准测试,用于评估代码补全模型在无未来上下文泄露情况下的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SpecAgent在代码补全任务中取得了显著的性能提升。与现有最佳基线方法相比,SpecAgent实现了9-11%的绝对收益(48-58%的相对收益),同时显著降低了推理延迟。这些结果表明,SpecAgent是一种有效的代码补全方法,具有很强的实用价值。
🎯 应用场景
SpecAgent可应用于各种代码补全场景,例如IDE插件、代码编辑器和自动化代码生成工具。通过提高代码补全的准确性和降低延迟,SpecAgent可以显著提高开发人员的生产力,并减少代码错误。该研究对于提升软件开发效率和质量具有重要的实际价值和潜在影响。
📄 摘要(原文)
Large Language Models (LLMs) excel at code-related tasks but often struggle in realistic software repositories, where project-specific APIs and cross-file dependencies are crucial. Retrieval-augmented methods mitigate this by injecting repository context at inference time. The low inference-time latency budget affects either retrieval quality or the added latency adversely impacts user experience. We address this limitation with SpecAgent, an agent that improves both latency and code-generation quality by proactively exploring repository files during indexing and constructing speculative context that anticipates future edits in each file. This indexing-time asynchrony allows thorough context computation, masking latency, and the speculative nature of the context improves code-generation quality. Additionally, we identify the problem of future context leakage in existing benchmarks, which can inflate reported performance. To address this, we construct a synthetic, leakage-free benchmark that enables a more realistic evaluation of our agent against baselines. Experiments show that SpecAgent consistently achieves absolute gains of 9-11% (48-58% relative) compared to the best-performing baselines, while significantly reducing inference latency.