Contextual Attention Modulation: Towards Efficient Multi-Task Adaptation in Large Language Models
作者: Dayan Pan, Zhaoyang Fu, Jingyuan Wang, Xiao Han, Yue Zhu, Xiangyu Zhao
分类: cs.AI, cs.CL
发布日期: 2025-10-20
备注: Accepted by CIKM' 25
🔗 代码/项目: GITHUB
💡 一句话要点
提出上下文注意力调制(CAM)机制,高效解决大语言模型中的多任务适应问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多任务学习 上下文注意力调制 参数高效微调 知识保留
📋 核心要点
- 现有大语言模型在多任务学习中面临灾难性遗忘和资源消耗过大的挑战。
- 提出上下文注意力调制(CAM)机制,动态调整自注意力模块,平衡知识保留和任务特化。
- 实验表明,HyCAM框架在问答、代码生成和逻辑推理等任务上显著优于现有方法,平均提升3.65%。
📝 摘要(中文)
大型语言模型(LLM)具有卓越的泛化能力,但在多任务适应方面表现不佳,尤其是在知识保留与任务特定专业化之间取得平衡。传统的微调方法存在灾难性遗忘和大量资源消耗的问题,而现有的参数高效方法在复杂的多任务场景中表现欠佳。为了解决这个问题,我们提出了一种新的机制——上下文注意力调制(CAM),它可以动态地调制LLM中自注意力模块的表示。CAM增强了任务特定的特征,同时保留了一般知识,从而促进了更有效和高效的适应。为了实现有效的多任务适应,CAM被集成到我们的混合上下文注意力调制(HyCAM)框架中,该框架结合了一个共享的、全参数的CAM模块和多个专门的、轻量级的CAM模块,并通过动态路由策略进行增强,以实现自适应的知识融合。在异构任务(包括问答、代码生成和逻辑推理)上的大量实验表明,我们的方法明显优于现有方法,平均性能提高了3.65%。已实现的代码和数据可在https://github.com/Applied-Machine-Learning-Lab/HyCAM上获取,以方便重现。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在多任务学习中遇到的知识遗忘和效率低下的问题。现有微调方法容易导致灾难性遗忘,而参数高效方法在复杂多任务场景下表现不佳。因此,如何让LLM在适应新任务的同时,保持原有知识,并降低计算成本,是本文要解决的核心问题。
核心思路:论文的核心思路是通过上下文注意力调制(CAM)机制,动态地调整LLM中自注意力模块的表示。CAM的设计目标是增强任务特定特征,同时保留通用知识。通过这种方式,模型可以更有效地适应新任务,而不会忘记已有的知识。
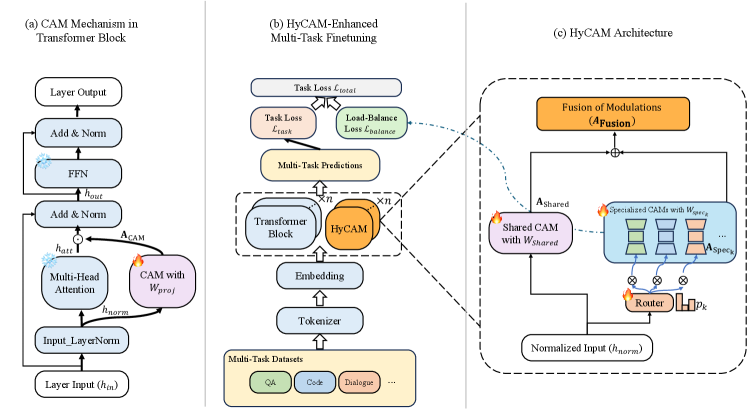
技术框架:论文提出了混合上下文注意力调制(HyCAM)框架。该框架包含一个共享的、全参数的CAM模块,以及多个专门的、轻量级的CAM模块。共享CAM模块负责保留通用知识,而专用CAM模块负责学习任务特定知识。此外,框架还包含一个动态路由策略,用于自适应地融合来自不同CAM模块的知识。整体流程是:输入数据首先经过共享CAM模块,然后经过动态路由策略,选择合适的专用CAM模块进行处理,最后将结果融合。
关键创新:论文的关键创新在于CAM机制和HyCAM框架的结合。CAM机制能够动态地调制自注意力模块的表示,从而实现任务特定特征的增强和通用知识的保留。HyCAM框架通过共享和专用CAM模块的结合,以及动态路由策略,实现了更高效的多任务学习。与现有方法相比,CAM机制更加灵活,能够更好地适应不同的任务。
关键设计:CAM模块的具体实现细节未知,论文中可能未详细描述其内部结构和参数设置。动态路由策略的具体实现方式也未知,可能涉及到注意力机制或其他选择机制。损失函数的设计可能包括任务特定的损失函数和正则化项,以防止过拟合和灾难性遗忘。网络结构方面,HyCAM框架可以灵活地应用于各种基于Transformer的LLM。
🖼️ 关键图片
📊 实验亮点
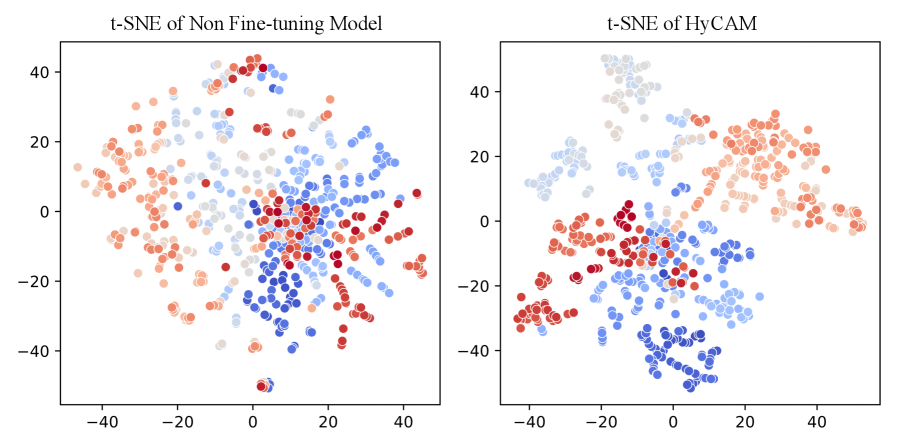
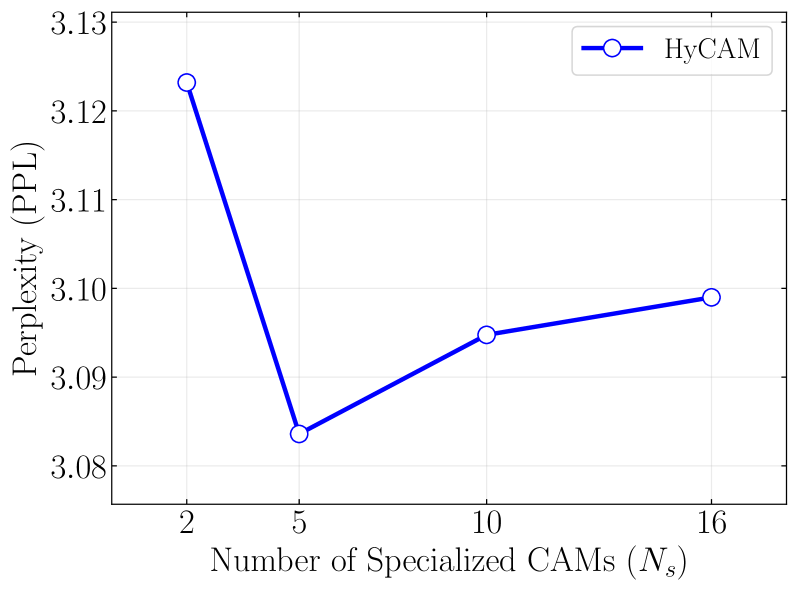
实验结果表明,HyCAM框架在问答、代码生成和逻辑推理等异构任务上显著优于现有方法,平均性能提升了3.65%。这一结果验证了CAM机制和HyCAM框架的有效性,表明该方法能够在多任务学习中实现更好的知识保留和任务适应。
🎯 应用场景
该研究成果可应用于各种需要多任务学习的大语言模型应用场景,例如智能客服、多语言翻译、代码生成等。通过高效地适应不同任务,可以提升模型的通用性和实用性,降低模型部署和维护的成本。未来,该方法有望推广到更多模态和更复杂的任务中,推动通用人工智能的发展。
📄 摘要(原文)
Large Language Models (LLMs) possess remarkable generalization capabilities but struggle with multi-task adaptation, particularly in balancing knowledge retention with task-specific specialization. Conventional fine-tuning methods suffer from catastrophic forgetting and substantial resource consumption, while existing parameter-efficient methods perform suboptimally in complex multi-task scenarios. To address this, we propose Contextual Attention Modulation (CAM), a novel mechanism that dynamically modulates the representations of self-attention modules in LLMs. CAM enhances task-specific features while preserving general knowledge, thereby facilitating more effective and efficient adaptation. For effective multi-task adaptation, CAM is integrated into our Hybrid Contextual Attention Modulation (HyCAM) framework, which combines a shared, full-parameter CAM module with multiple specialized, lightweight CAM modules, enhanced by a dynamic routing strategy for adaptive knowledge fusion. Extensive experiments on heterogeneous tasks, including question answering, code generation, and logical reasoning, demonstrate that our approach significantly outperforms existing approaches, achieving an average performance improvement of 3.65%. The implemented code and data are available to ease reproducibility at https://github.com/Applied-Machine-Learning-Lab/HyCAM.