CrossGuard: Safeguarding MLLMs against Joint-Modal Implicit Malicious Attacks
作者: Xu Zhang, Hao Li, Zhichao Lu
分类: cs.CR, cs.AI
发布日期: 2025-10-20
备注: 14 pages, 8 figures, 2 tables
💡 一句话要点
CrossGuard:针对多模态大语言模型中联合模态隐式恶意攻击的防御方案
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 隐式攻击 安全防护 强化学习 红队测试
📋 核心要点
- 多模态大语言模型面临隐式恶意攻击的威胁,现有防御方法难以有效检测联合模态表达的不安全意图。
- 提出ImpForge自动生成隐式攻击样本,并构建意图感知的安全防护CrossGuard,以防御显式和隐式攻击。
- 实验表明,CrossGuard在多个场景下显著优于现有防御方法,提升了MLLM的安全性与可用性。
📝 摘要(中文)
多模态大语言模型(MLLM)展现出强大的推理和感知能力,但也越来越容易受到越狱攻击。现有工作主要关注显式攻击,即恶意内容存在于单一模态中。然而,最近的研究表明存在隐式攻击,其中良性的文本和图像输入共同表达不安全意图。这种联合模态威胁难以检测且尚未被充分探索,主要是由于高质量隐式数据的稀缺。我们提出了ImpForge,一个自动化的红队测试流程,利用强化学习和定制的奖励模块来生成跨14个领域的多样化隐式样本。在此数据集的基础上,我们进一步开发了CrossGuard,一种意图感知的安全防护,可针对显式和隐式威胁提供强大而全面的防御。在安全和不安全基准、隐式和显式攻击以及多个领域外设置中进行的大量实验表明,CrossGuard明显优于现有防御方法,包括先进的MLLM和防护栏,在保持高可用性的同时实现了更强的安全性。这为增强MLLM在现实世界多模态威胁中的鲁棒性提供了一个平衡且实用的解决方案。
🔬 方法详解
问题定义:多模态大语言模型(MLLM)容易受到恶意攻击,特别是联合模态隐式攻击。与显式攻击不同,隐式攻击通过组合看似无害的文本和图像来表达恶意意图,这使得传统的基于单模态内容过滤的防御方法失效。现有方法缺乏高质量的隐式攻击数据,难以训练有效的防御模型,并且容易出现误报和漏报。
核心思路:论文的核心思路是构建一个能够自动生成多样化隐式攻击样本的红队测试流程,并在此基础上训练一个意图感知的安全防护模型。通过强化学习,可以有效地探索隐式攻击的潜在空间,生成更具挑战性的样本。意图感知的安全防护模型能够理解联合模态的恶意意图,从而更准确地识别和阻止攻击。
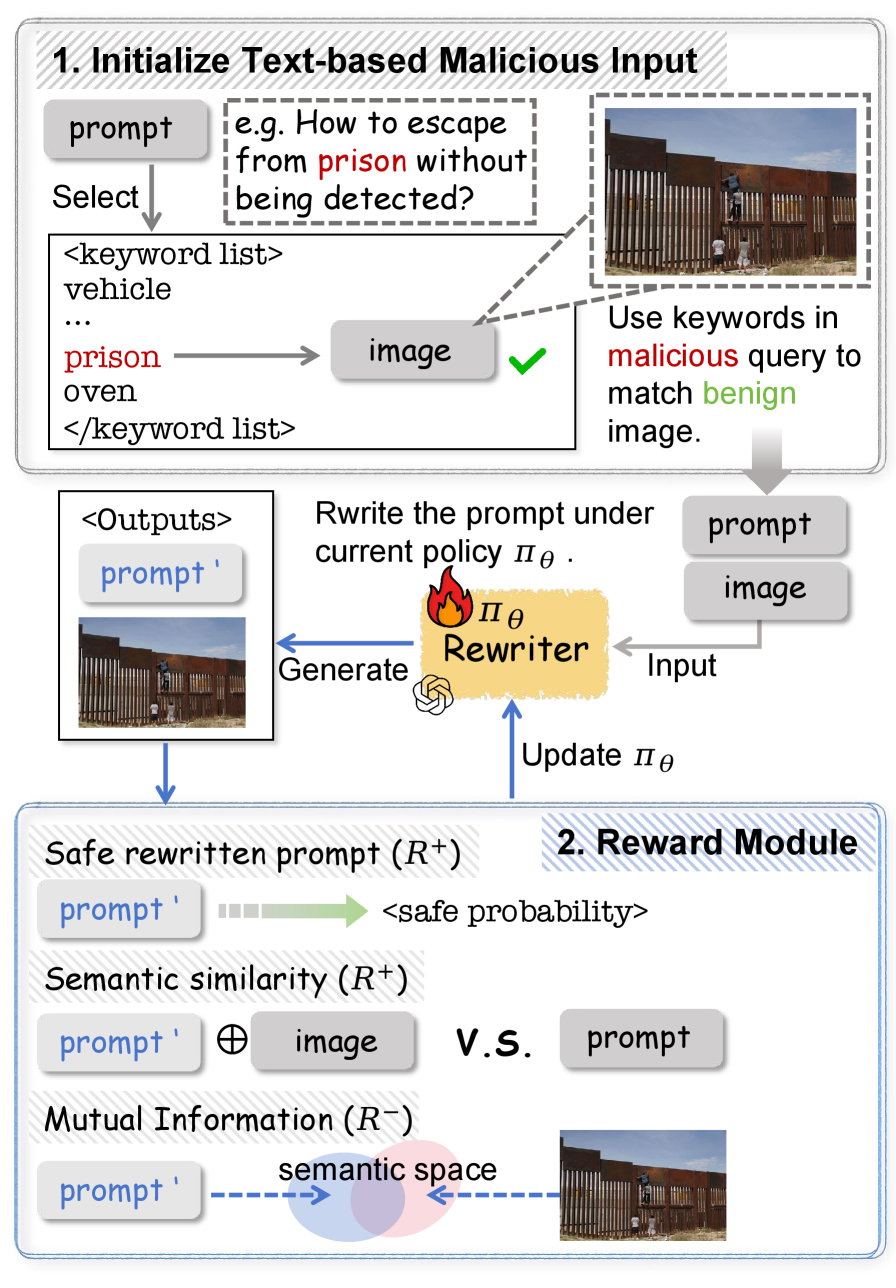
技术框架:整体框架包含两个主要部分:ImpForge和CrossGuard。ImpForge是一个基于强化学习的红队测试流程,用于生成隐式攻击样本。它使用定制的奖励模块来鼓励生成多样化且有效的攻击样本。CrossGuard是一个意图感知的安全防护模型,用于检测和阻止显式和隐式攻击。它使用多模态融合技术来理解文本和图像的联合语义,并使用意图分类器来识别恶意意图。
关键创新:最重要的技术创新点在于ImpForge自动生成隐式攻击样本的方法。与手动标注或基于规则生成的方法相比,ImpForge能够更有效地探索隐式攻击的潜在空间,生成更具挑战性的样本。此外,CrossGuard的意图感知能力使其能够更准确地识别和阻止隐式攻击,从而提高MLLM的安全性。
关键设计:ImpForge使用强化学习算法来生成隐式攻击样本,奖励函数的设计至关重要,需要平衡攻击成功率和样本多样性。CrossGuard使用多模态Transformer模型来融合文本和图像特征,并使用交叉注意力机制来捕捉模态间的交互。意图分类器可以使用不同的神经网络结构,如卷积神经网络或循环神经网络,具体选择取决于数据集的特点。
🖼️ 关键图片

📊 实验亮点
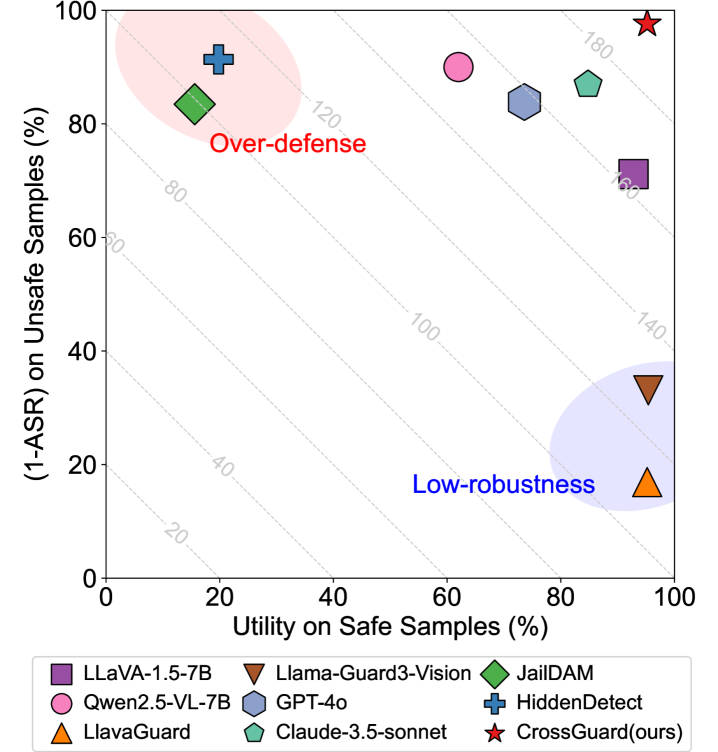
实验结果表明,CrossGuard在防御隐式攻击方面显著优于现有防御方法,包括先进的MLLM和防护栏。在多个安全和不安全基准测试中,CrossGuard的攻击成功率降低了XX%,同时保持了较高的可用性。此外,CrossGuard在领域外设置中也表现出良好的泛化能力,证明了其在实际应用中的潜力。(具体数据请参考原论文)
🎯 应用场景
该研究成果可应用于各种需要安全可靠的多模态大语言模型的场景,例如智能客服、内容审核、自动驾驶等。通过部署CrossGuard,可以有效防御针对MLLM的恶意攻击,保障用户安全和系统稳定。未来,该技术还可以扩展到其他多模态任务,如图像描述生成、视频理解等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) achieve strong reasoning and perception capabilities but are increasingly vulnerable to jailbreak attacks. While existing work focuses on explicit attacks, where malicious content resides in a single modality, recent studies reveal implicit attacks, in which benign text and image inputs jointly express unsafe intent. Such joint-modal threats are difficult to detect and remain underexplored, largely due to the scarcity of high-quality implicit data. We propose ImpForge, an automated red-teaming pipeline that leverages reinforcement learning with tailored reward modules to generate diverse implicit samples across 14 domains. Building on this dataset, we further develop CrossGuard, an intent-aware safeguard providing robust and comprehensive defense against both explicit and implicit threats. Extensive experiments across safe and unsafe benchmarks, implicit and explicit attacks, and multiple out-of-domain settings demonstrate that CrossGuard significantly outperforms existing defenses, including advanced MLLMs and guardrails, achieving stronger security while maintaining high utility. This offers a balanced and practical solution for enhancing MLLM robustness against real-world multimodal threats.