LLM-as-a-Prophet: Understanding Predictive Intelligence with Prophet Arena
作者: Qingchuan Yang, Simon Mahns, Sida Li, Anri Gu, Jibang Wu, Haifeng Xu
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-10-20 (更新: 2025-12-21)
备注: https://www.prophetarena.co/
💡 一句话要点
构建Prophet Arena基准,探索LLM作为预言机在预测智能方面的潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预测智能 基准测试 Prophet Arena 事件预测
📋 核心要点
- 现有预测方法难以有效利用互联网规模数据,缺乏对复杂社会经济事件的预测能力。
- 提出“LLM-as-a-Prophet”范式,利用LLM的知识和推理能力进行未来事件预测。
- 构建Prophet Arena基准,通过大规模实验评估LLM在预测任务中的性能,并识别关键瓶颈。
📝 摘要(中文)
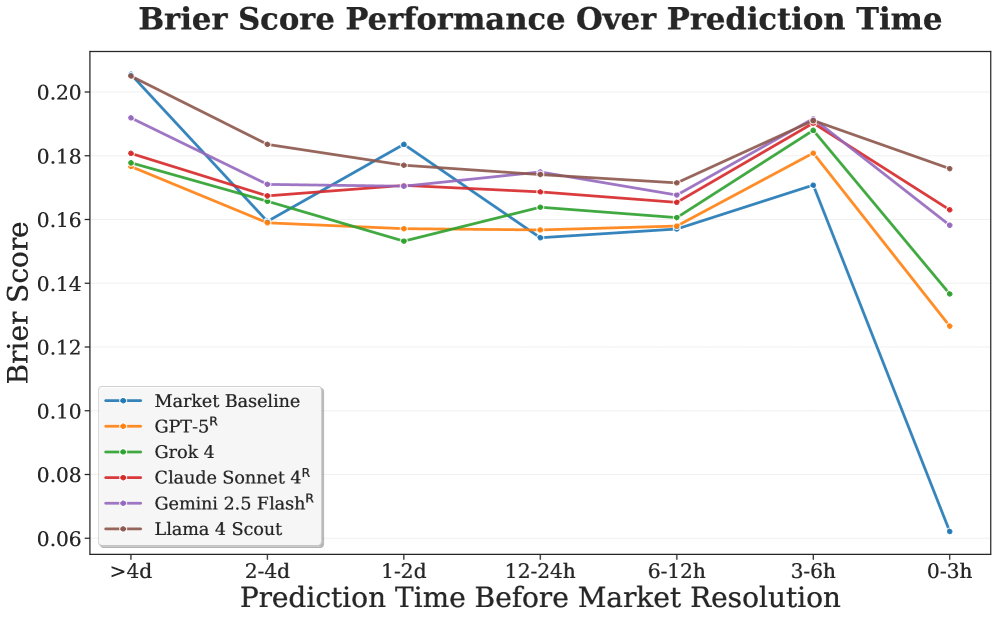
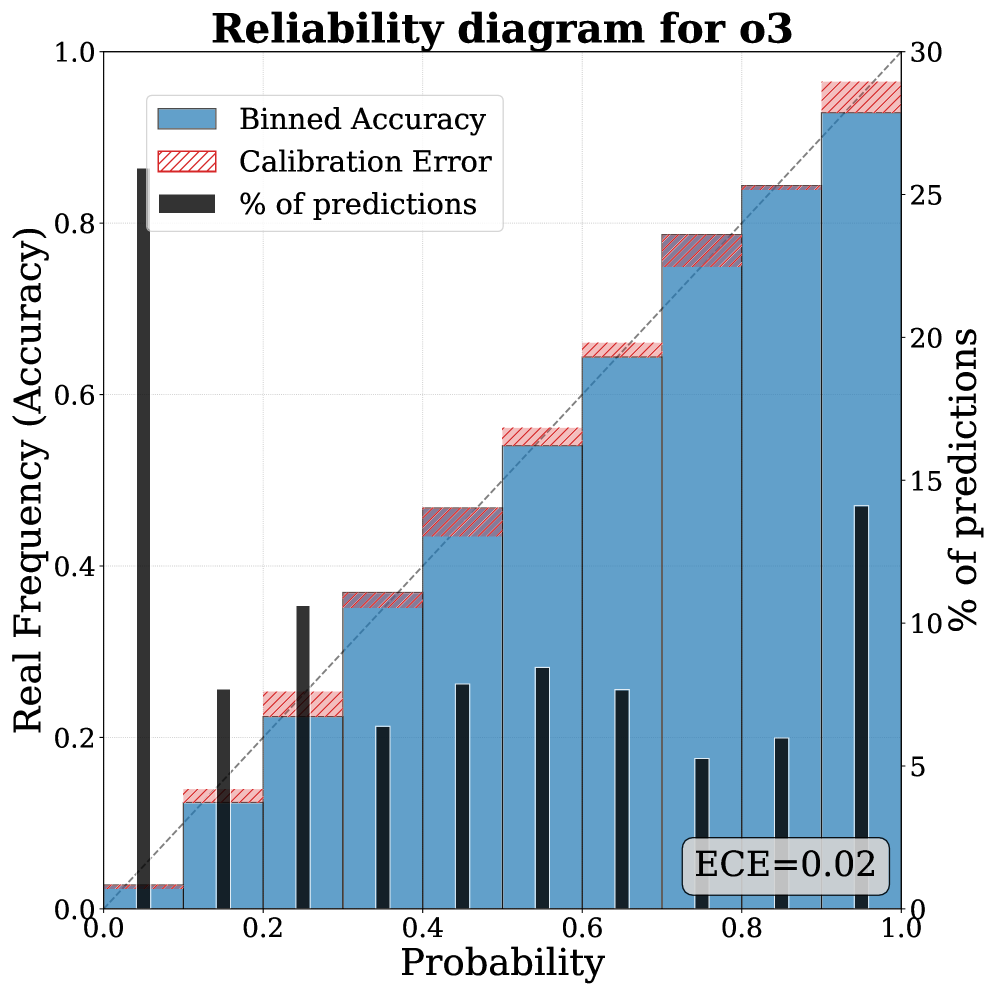
预测不仅是重要的学术研究,对金融和经济等社会系统也至关重要。随着在互联网规模数据上训练的大型语言模型(LLM)的快速发展,利用LLM预测现实世界未来事件成为可能,我们称之为“LLM-as-a-Prophet”的新范式。本文系统地研究了LLM的这种预测智能。为此,我们构建了Prophet Arena,这是一个通用的评估基准,持续收集实时的预测任务,并将每个任务分解为不同的pipeline阶段,以支持我们可控的大规模实验。我们的综合评估表明,许多LLM已经表现出令人印象深刻的预测能力,例如,它们具有较小的校准误差、一致的预测置信度和有希望的市场回报。然而,我们也发现了通过LLM-as-a-Prophet实现卓越预测智能的关键瓶颈,例如LLM不准确的事件召回、对数据源的误解以及与市场相比在临近结果时信息聚合速度较慢。
🔬 方法详解
问题定义:论文旨在评估和理解大型语言模型(LLM)在预测未来事件方面的能力,即“LLM-as-a-Prophet”范式。现有方法的痛点在于缺乏一个系统性的评估框架,难以量化LLM在预测任务中的表现,并识别其优势和局限性。
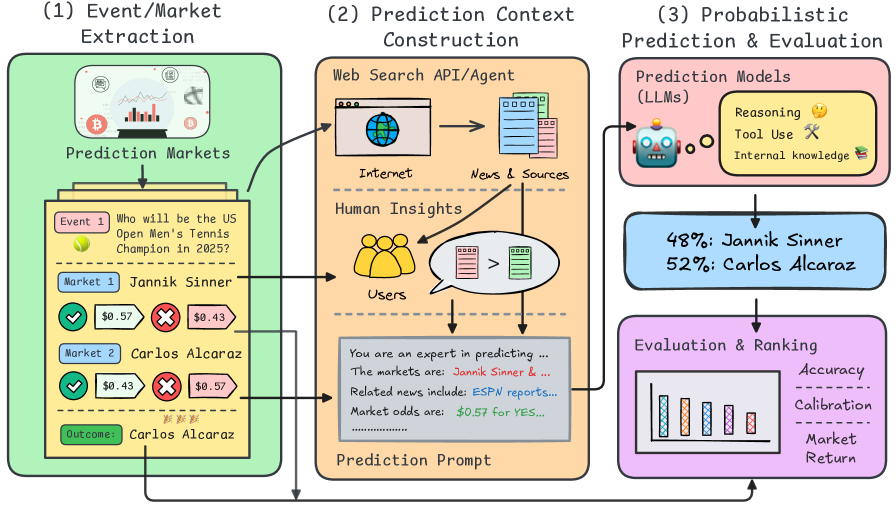
核心思路:论文的核心思路是构建一个名为Prophet Arena的通用评估基准,该基准能够持续收集实时的预测任务,并将每个任务分解为不同的pipeline阶段,从而实现对LLM预测能力的受控和大规模实验。通过分析LLM在不同阶段的表现,可以深入了解其预测智能的机制和瓶颈。
技术框架:Prophet Arena的整体框架包含以下几个主要模块:1) 任务收集模块:负责从各种来源收集实时的预测任务,例如金融市场、新闻事件等。2) 任务分解模块:将每个预测任务分解为不同的pipeline阶段,例如事件识别、信息提取、预测生成、结果评估等。3) LLM集成模块:提供一个统一的接口,方便集成不同的LLM进行预测。4) 评估模块:根据预定义的指标评估LLM的预测性能,例如校准误差、预测置信度、市场回报等。
关键创新:论文最重要的技术创新在于提出了Prophet Arena基准,这是一个专门用于评估LLM预测能力的通用平台。与现有方法相比,Prophet Arena具有以下优势:1) 实时性:持续收集实时的预测任务,能够反映LLM在真实世界场景中的表现。2) 可控性:将预测任务分解为不同的pipeline阶段,方便对LLM的各个模块进行评估和调试。3) 可扩展性:提供一个统一的接口,方便集成不同的LLM和评估指标。
关键设计:Prophet Arena的关键设计包括:1) 任务分解策略:采用一种灵活的任务分解策略,能够适应不同类型的预测任务。2) 评估指标选择:选择了一系列能够全面反映LLM预测性能的指标,例如校准误差、预测置信度、市场回报等。3) 数据源选择:选择了多个具有代表性的数据源,例如金融市场、新闻事件等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,许多LLM已经表现出令人印象深刻的预测能力,例如,它们具有较小的校准误差、一致的预测置信度和有希望的市场回报。然而,研究也揭示了LLM在预测方面的一些瓶颈,例如不准确的事件召回和对数据源的误解。这些发现为未来改进LLM的预测能力提供了重要的指导。
🎯 应用场景
该研究成果可应用于金融预测、经济预测、风险管理、舆情分析等领域。通过利用LLM的预测能力,可以帮助决策者更好地理解未来趋势,制定更有效的策略。未来,该研究有望推动LLM在预测领域的更广泛应用,并促进相关技术的发展。
📄 摘要(原文)
Forecasting is not only a fundamental intellectual pursuit but also is of significant importance to societal systems such as finance and economics. With the rapid advances of large language models (LLMs) trained on Internet-scale data, it raises the promise of employing LLMs to forecast real-world future events, an emerging paradigm we call "LLM-as-a-Prophet". This paper systematically investigates such predictive intelligence of LLMs. To this end, we build Prophet Arena, a general evaluation benchmark that continuously collects live forecasting tasks and decomposes each task into distinct pipeline stages, in order to support our controlled and large-scale experimentation. Our comprehensive evaluation reveals that many LLMs already exhibit impressive forecasting capabilities, reflected in, e.g., their small calibration errors, consistent prediction confidence and promising market returns. However, we also uncover key bottlenecks towards achieving superior predictive intelligence via LLM-as-a-Prophet, such as LLMs' inaccurate event recalls, misunderstanding of data sources and slower information aggregation compared to markets when resolution nears.