Reasoning Distillation and Structural Alignment for Improved Code Generation
作者: Amir Jalilifard, Anderson de Rezende Rocha, Marcos Medeiros Raimundo
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-10-20
💡 一句话要点
提出基于推理蒸馏和结构对齐的代码生成方法,提升小模型的代码生成能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 语言模型 知识蒸馏 结构对齐 推理能力
📋 核心要点
- 代码生成任务需要模型理解问题意图和生成具备推理能力的代码,现有小模型缺乏足够的推理能力。
- 通过推理蒸馏,将大型语言模型的推理能力迁移到小模型,并引入结构感知损失优化,提升模型对问题结构的理解。
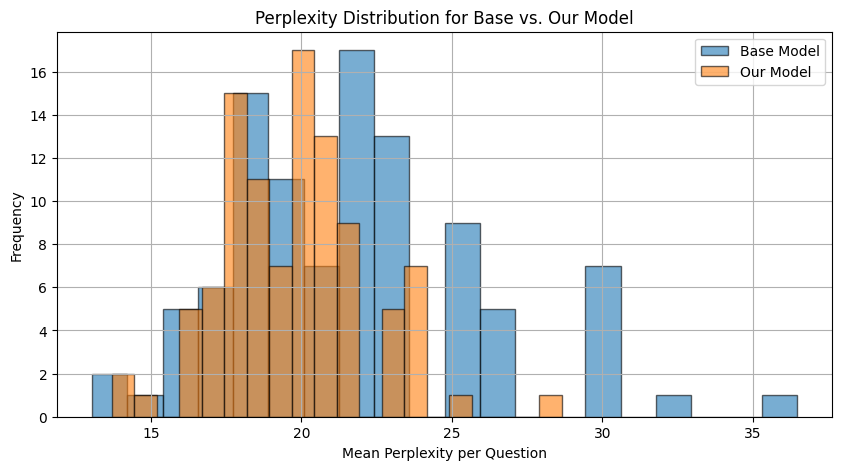
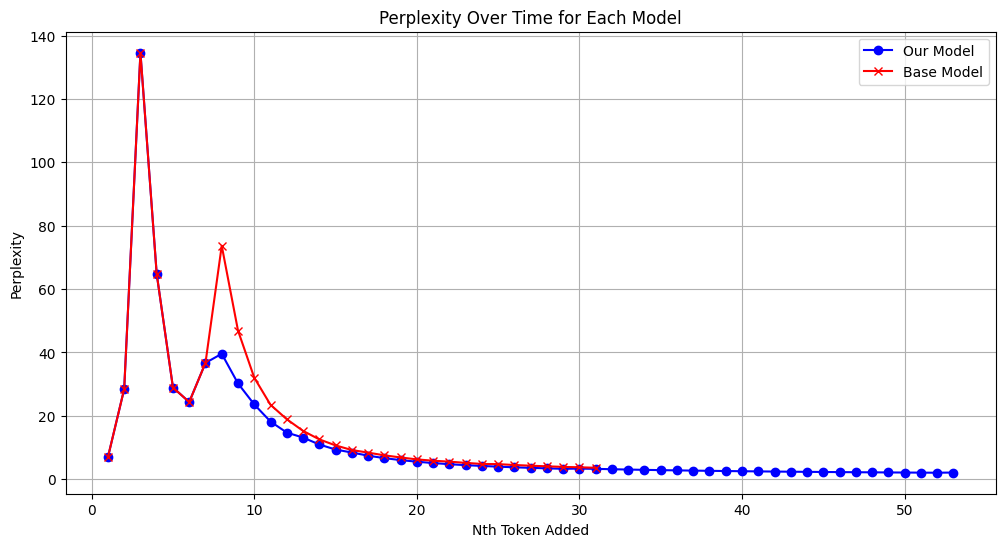
- 实验表明,该方法在MBPP等基准测试中显著提升了代码生成性能,包括pass@1、平均数据流和平均语法匹配指标。
📝 摘要(中文)
本文提出了一种通过推理蒸馏提升代码生成语言模型性能的方法。该方法旨在将大型语言模型(VLLM)的推理能力迁移到更小、更高效的模型中,使其能够更好地理解prompt的意图,并生成具备算法推理能力的代码,从而通过各种测试用例并符合目标编程语言的语法。该方法通过学习识别正确的解决方案路径,并利用一种新颖的结构感知损失优化方法,在问题定义和潜在解决方案之间建立结构对应关系,使模型能够超越token级别的生成,深刻理解给定问题的整体解决方案结构。实验结果表明,通过这种简单且低成本的微调过程开发的模型,在MBPP、MBPP Plus和HumanEval基准测试中,pass@1、平均数据流和平均语法匹配指标方面均显著优于基线模型。
🔬 方法详解
问题定义:代码生成任务不仅需要准确的token预测,更需要理解解决方案层面的结构关系。现有的小型语言模型在解决复杂问题时,缺乏大型语言模型所具备的推理能力,难以生成符合问题结构和逻辑的代码。
核心思路:本文的核心思路是通过知识蒸馏,将大型语言模型(VLLM)的推理能力迁移到小型语言模型中。具体而言,训练小型模型模仿VLLM的推理和问题解决能力,使其能够识别正确的解决方案路径,并理解问题定义和潜在解决方案之间的结构对应关系。这样,小型模型就能超越简单的token生成,把握问题的整体结构。
技术框架:该方法主要包含两个阶段:首先,利用大型语言模型生成高质量的代码解决方案和推理过程。然后,使用这些数据来训练小型语言模型,使其学习模仿大型模型的行为。关键在于引入了一种结构感知损失函数,该函数鼓励小型模型生成的代码在结构上与大型模型生成的代码保持一致。
关键创新:该方法最重要的创新在于结构感知损失函数的设计。传统的损失函数主要关注token级别的预测准确性,而结构感知损失函数则关注代码的整体结构。通过优化结构感知损失,模型能够更好地理解问题和解决方案之间的结构关系,从而生成更符合问题逻辑的代码。
关键设计:结构感知损失函数的具体形式未知,但可以推测其可能涉及到代码的抽象语法树(AST)的比较,或者其他能够捕捉代码结构信息的表示方法。此外,训练数据的选择和生成方式也至关重要,需要确保训练数据能够充分覆盖各种问题类型和解决方案结构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在MBPP、MBPP Plus和HumanEval基准测试中,pass@1、平均数据流和平均语法匹配指标方面均显著优于基线模型。具体的性能提升数据未知,但可以确定该方法能够有效提升小模型的代码生成能力。
🎯 应用场景
该研究成果可应用于各种需要代码自动生成的场景,例如软件开发辅助工具、自动化测试、编程教育等。通过将大型模型的推理能力迁移到小型模型,可以降低部署成本,提高代码生成效率,并促进更广泛的AI代码生成应用。
📄 摘要(原文)
Effective code generation with language models hinges on two critical factors: accurately understanding the intent of the prompt and generating code that applies algorithmic reasoning to produce correct solutions capable of passing diverse test cases while adhering to the syntax of the target programming language. Unlike other language tasks, code generation requires more than accurate token prediction; it demands comprehension of solution-level and structural relationships rather than merely generating the most likely tokens. very large language model (VLLM) are capable of generating detailed steps toward the correct solution of complex tasks where reasoning is crucial in solving the problem. Such reasoning capabilities may be absent in smaller language models. Therefore, in this work, we distill the reasoning capabilities of a VLLM into a smaller, more efficient model that is faster and cheaper to deploy. Our approach trains the model to emulate the reasoning and problem-solving abilities of the VLLM by learning to identify correct solution pathways and establishing a structural correspondence between problem definitions and potential solutions through a novel method of structure-aware loss optimization. This enables the model to transcend token-level generation and to deeply grasp the overarching structure of solutions for given problems. Experimental results show that our fine-tuned model, developed through a cheap and simple to implement process, significantly outperforms our baseline model in terms of pass@1, average data flow, and average syntax match metrics across the MBPP, MBPP Plus, and HumanEval benchmarks.