MIRAGE: Agentic Framework for Multimodal Misinformation Detection with Web-Grounded Reasoning
作者: Mir Nafis Sharear Shopnil, Sharad Duwal, Abhishek Tyagi, Adiba Mahbub Proma
分类: cs.AI, cs.CL, cs.CV, cs.CY, cs.LG
发布日期: 2025-10-20
备注: 16 pages, 3 tables, 1 figure
💡 一句话要点
MIRAGE:基于Web检索推理的多模态信息检测Agent框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态虚假信息检测 Agent框架 Web检索 视觉真实性评估 跨模态一致性 事实核查 可解释性
📋 核心要点
- 现有监督模型依赖领域数据,难以泛化到各种信息操纵手段,限制了多模态虚假信息检测的有效性。
- MIRAGE框架通过分解多模态验证流程,结合视觉真实性评估、跨模态一致性分析和检索增强的事实核查,实现更可靠的判断。
- 实验表明,MIRAGE在MMFakeBench数据集上显著优于现有零样本方法,并在测试集上保持了良好的泛化能力。
📝 摘要(中文)
针对网络平台海量多模态(文本和图像)信息传播,人工核查能力不足的问题,本文提出MIRAGE,一个推理时可插拔的Agent框架,用于多模态虚假信息检测。MIRAGE将验证过程分解为四个模块:视觉真实性评估(检测AI生成图像)、跨模态一致性分析(识别上下文不符的图像挪用)、检索增强的事实核查(通过迭代问题生成从网络证据中验证声明),以及校准判断模块(整合所有信号)。MIRAGE协调视觉-语言模型推理和定向Web检索,输出结构化且附带引用的理由。在MMFakeBench验证集上,MIRAGE结合GPT-4o-mini实现了81.65%的F1值和75.1%的准确率,优于最强的零样本基线(GPT-4V with MMD-Agent,F1值为74.0%)7.65个百分点,同时保持了34.3%的假阳性率,而仅使用判断模块的基线假阳性率为97.3%。在测试集上的结果(5000个样本)证实了其泛化能力,F1值为81.44%,准确率为75.08%。消融研究表明,视觉验证贡献了5.18个F1值,检索增强推理贡献了2.97个F1值。结果表明,分解的Agent推理与Web检索可以匹配监督检测器的性能,而无需特定领域的训练数据,从而能够在缺乏标注数据的多模态场景中进行虚假信息检测。
🔬 方法详解
问题定义:当前多模态虚假信息检测面临的挑战是,监督学习方法需要大量的特定领域标注数据,而虚假信息的传播方式和内容不断变化,导致模型难以泛化到新的场景和操纵手段。现有方法难以有效利用外部知识,缺乏可解释性。
核心思路:MIRAGE的核心思路是将多模态虚假信息检测分解为多个可解释的步骤,每个步骤由专门的模块处理,并利用外部Web知识进行验证。通过Agent框架协调各个模块,实现更鲁棒和可解释的检测。
技术框架:MIRAGE框架包含四个主要模块:1) 视觉真实性评估:检测图像是否为AI生成;2) 跨模态一致性分析:检查文本和图像内容是否一致,是否存在图像被挪用的情况;3) 检索增强的事实核查:通过迭代生成问题,从Web上检索相关证据,验证文本声明的真实性;4) 校准判断模块:整合前三个模块的输出,给出最终的判断结果。
关键创新:MIRAGE的关键创新在于其Agent框架的设计,它将复杂的虚假信息检测任务分解为多个可解释的子任务,并利用Web检索增强推理能力。这种分解的方式使得模型更易于理解和调试,并且可以灵活地集成不同的模块。
关键设计:MIRAGE使用GPT-4o-mini作为核心推理引擎,并结合了专门的视觉真实性检测模型。检索增强的事实核查模块使用迭代问题生成策略,以更有效地从Web上获取相关证据。校准判断模块使用逻辑回归模型,对各个模块的输出进行加权融合。
🖼️ 关键图片
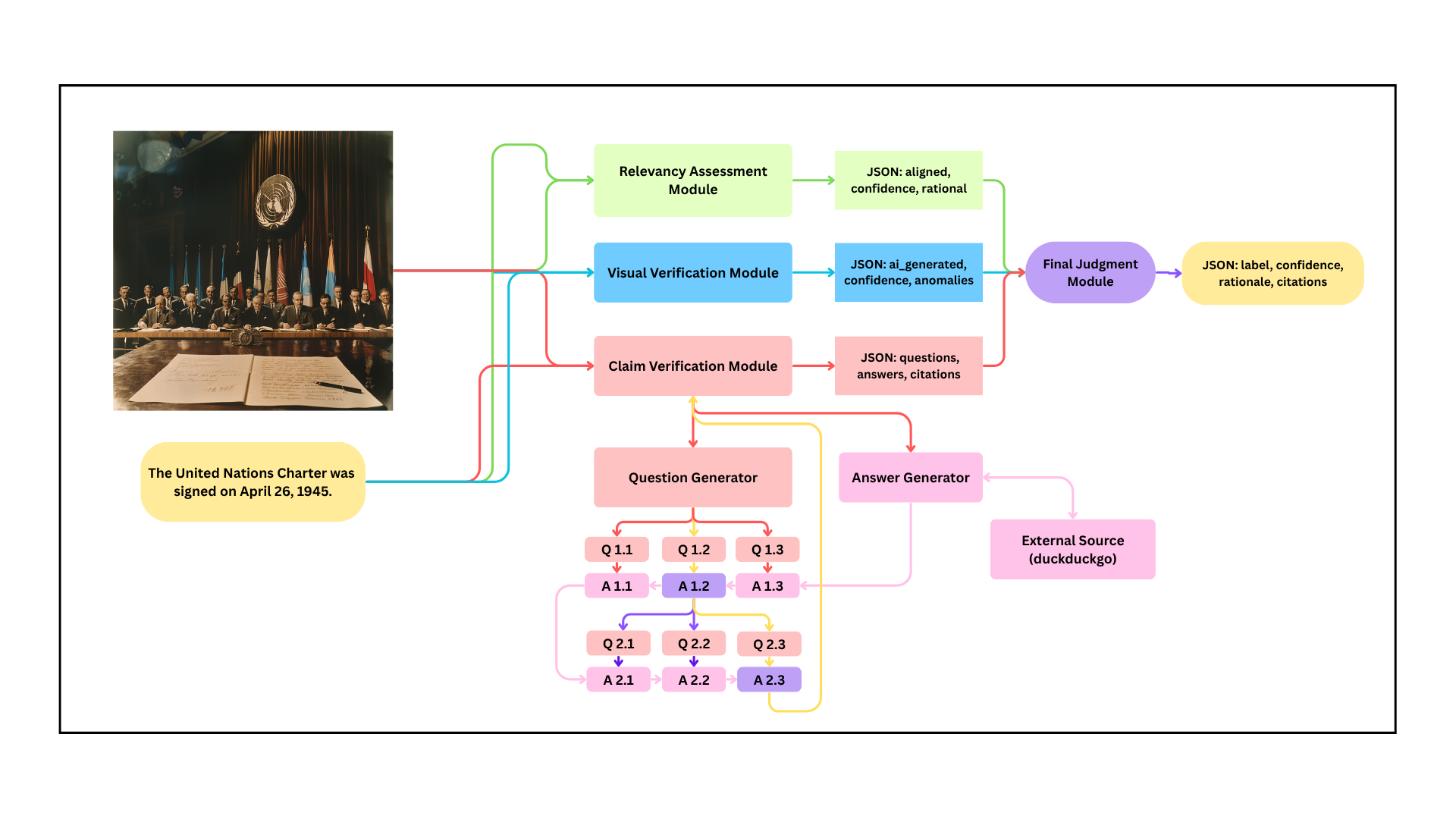
📊 实验亮点
MIRAGE在MMFakeBench验证集上取得了81.65%的F1值和75.1%的准确率,显著优于GPT-4V with MMD-Agent (74.0% F1)。消融实验表明,视觉验证和检索增强推理分别贡献了5.18和2.97个F1值的提升。测试集结果(81.44% F1,75.08%准确率)验证了MIRAGE的泛化能力。
🎯 应用场景
MIRAGE框架可应用于社交媒体平台、新闻网站等场景,自动检测和标记虚假信息,减少其传播。该研究有助于提高公众对虚假信息的识别能力,维护网络信息生态的健康。未来可扩展到更多模态和语言,应对更复杂的虚假信息传播形式。
📄 摘要(原文)
Misinformation spreads across web platforms through billions of daily multimodal posts that combine text and images, overwhelming manual fact-checking capacity. Supervised detection models require domain-specific training data and fail to generalize across diverse manipulation tactics. We present MIRAGE, an inference-time, model-pluggable agentic framework that decomposes multimodal verification into four sequential modules: visual veracity assessment detects AI-generated images, cross-modal consistency analysis identifies out-of-context repurposing, retrieval-augmented factual checking grounds claims in web evidence through iterative question generation, and a calibrated judgment module integrates all signals. MIRAGE orchestrates vision-language model reasoning with targeted web retrieval, outputs structured and citation-linked rationales. On MMFakeBench validation set (1,000 samples), MIRAGE with GPT-4o-mini achieves 81.65% F1 and 75.1% accuracy, outperforming the strongest zero-shot baseline (GPT-4V with MMD-Agent at 74.0% F1) by 7.65 points while maintaining 34.3% false positive rate versus 97.3% for a judge-only baseline. Test set results (5,000 samples) confirm generalization with 81.44% F1 and 75.08% accuracy. Ablation studies show visual verification contributes 5.18 F1 points and retrieval-augmented reasoning contributes 2.97 points. Our results demonstrate that decomposed agentic reasoning with web retrieval can match supervised detector performance without domain-specific training, enabling misinformation detection across modalities where labeled data remains scarce.