DeepAnalyze: Agentic Large Language Models for Autonomous Data Science
作者: Shaolei Zhang, Ju Fan, Meihao Fan, Guoliang Li, Xiaoyong Du
分类: cs.AI, cs.CL, cs.DB
发布日期: 2025-10-19
备注: Code: https://github.com/ruc-datalab/DeepAnalyze Model: https://huggingface.co/RUC-DataLab/DeepAnalyze-8B
💡 一句话要点
DeepAnalyze:面向自主数据科学的Agentic大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自主数据科学 Agentic LLM 课程学习 数据驱动 轨迹合成 大语言模型 数据分析 深度研究报告
📋 核心要点
- 现有基于工作流的数据Agent在实现完全自主的数据科学方面存在根本性限制,因为它们依赖于预定义的流程。
- DeepAnalyze采用基于课程的Agentic训练范式,模拟人类数据科学家的学习过程,逐步提升LLM在数据科学任务中的能力。
- 实验结果表明,DeepAnalyze仅用80亿参数就超越了基于更先进的专有LLM构建的现有工作流Agent。
📝 摘要(中文)
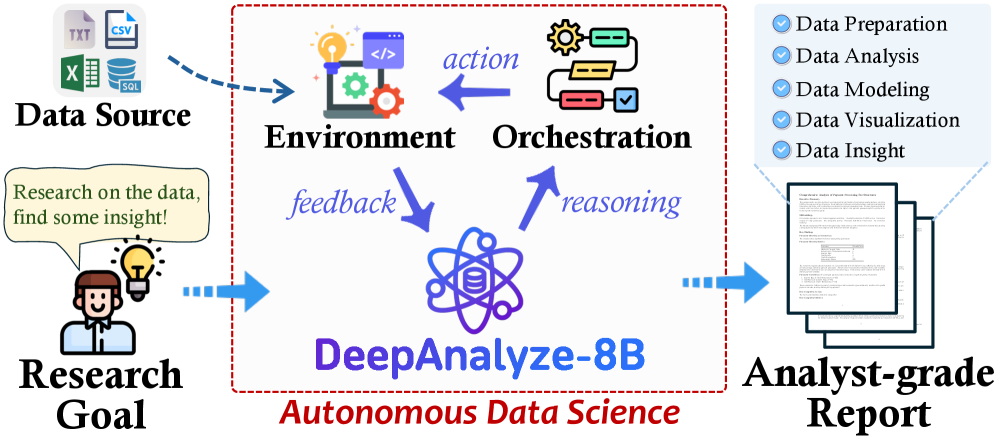
本文提出了DeepAnalyze-8B,这是第一个专为自主数据科学设计的agentic大语言模型,能够自动完成从数据源到分析师级别的深度研究报告的端到端流程。为了应对高复杂度的数据科学任务,作者提出了一种基于课程的agentic训练范式,模拟人类数据科学家的学习轨迹,使LLM能够在真实环境中逐步获取和整合多种能力。此外,还引入了一个数据驱动的轨迹合成框架,用于构建高质量的训练数据。通过agentic训练,DeepAnalyze学会执行广泛的数据任务,从数据问答、专业分析任务到开放式数据研究。实验表明,DeepAnalyze仅使用80亿参数,就优于之前基于最先进的专有LLM构建的基于工作流的agent。DeepAnalyze的模型、代码和训练数据已开源,为自主数据科学铺平了道路。
🔬 方法详解
问题定义:论文旨在解决自主数据科学的问题,即如何让LLM能够从原始数据源自主生成分析师级别的深度研究报告。现有方法主要依赖于预定义的工作流,无法灵活应对复杂多变的数据科学任务,缺乏自主性和泛化能力。
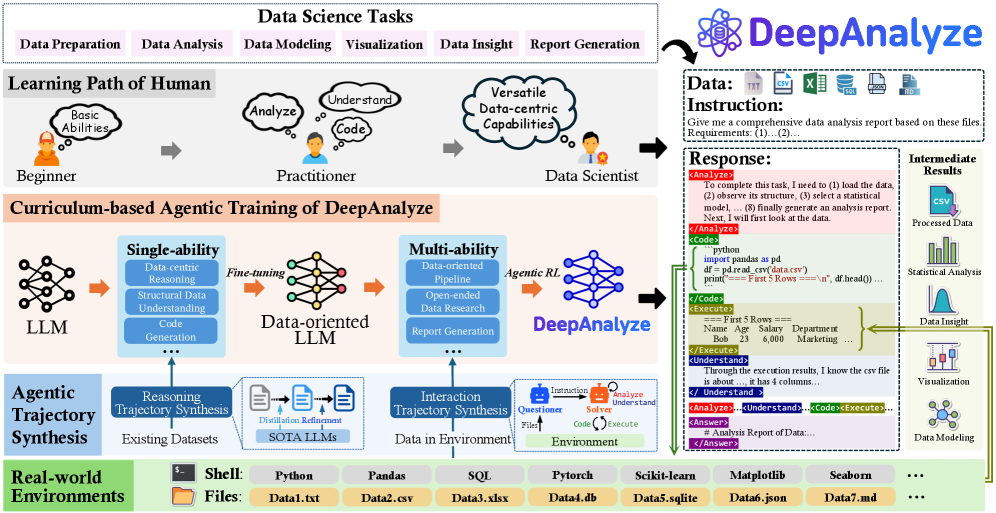
核心思路:论文的核心思路是采用Agentic LLM,并结合课程学习和数据驱动的轨迹合成,使LLM能够像人类数据科学家一样,逐步学习和掌握数据科学所需的各种技能,从而实现端到端的自主数据科学流程。
技术框架:DeepAnalyze的整体框架包含以下几个关键部分:1) Agentic LLM:作为核心决策引擎,负责规划和执行数据科学任务;2) 课程学习:设计一系列难度递增的数据科学任务,引导LLM逐步学习;3) 数据驱动的轨迹合成:生成高质量的训练数据,用于Agentic LLM的训练;4) 环境交互:LLM与真实数据环境进行交互,获取反馈并调整策略。
关键创新:论文最重要的技术创新在于提出了基于课程的Agentic训练范式,这是一种模拟人类学习过程的训练方法,能够有效地提升LLM在复杂数据科学任务中的能力。与传统的预定义工作流方法相比,Agentic LLM具有更强的自主性和泛化能力。
关键设计:课程学习的设计至关重要,需要精心设计一系列难度递增的数据科学任务,例如从简单的数据问答到复杂的开放式数据研究。数据驱动的轨迹合成框架需要能够生成高质量的训练数据,包括数据、任务描述、执行步骤和结果等。具体的参数设置、损失函数和网络结构等细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
DeepAnalyze-8B在实验中表现出色,仅使用80亿参数就超越了之前基于最先进的专有LLM构建的基于工作流的Agent。具体的性能数据和提升幅度在论文中进行了详细的对比和分析,证明了DeepAnalyze在自主数据科学方面的优越性。具体的数值提升幅度未知,需要参考原文。
🎯 应用场景
DeepAnalyze具有广泛的应用前景,可以应用于金融分析、市场研究、科学研究等领域,帮助用户快速从海量数据中提取有价值的信息,生成深度分析报告。该研究的实际价值在于降低了数据分析的门槛,提高了数据分析的效率,未来有望推动数据科学的普及和发展。
📄 摘要(原文)
Autonomous data science, from raw data sources to analyst-grade deep research reports, has been a long-standing challenge, and is now becoming feasible with the emergence of powerful large language models (LLMs). Recent workflow-based data agents have shown promising results on specific data tasks but remain fundamentally limited in achieving fully autonomous data science due to their reliance on predefined workflows. In this paper, we introduce DeepAnalyze-8B, the first agentic LLM designed for autonomous data science, capable of automatically completing the end-toend pipeline from data sources to analyst-grade deep research reports. To tackle high-complexity data science tasks, we propose a curriculum-based agentic training paradigm that emulates the learning trajectory of human data scientists, enabling LLMs to progressively acquire and integrate multiple capabilities in real-world environments. We also introduce a data-grounded trajectory synthesis framework that constructs high-quality training data. Through agentic training, DeepAnalyze learns to perform a broad spectrum of data tasks, ranging from data question answering and specialized analytical tasks to open-ended data research. Experiments demonstrate that, with only 8B parameters, DeepAnalyze outperforms previous workflow-based agents built on most advanced proprietary LLMs. The model, code, and training data of DeepAnalyze are open-sourced, paving the way toward autonomous data science.