When Many-Shot Prompting Fails: An Empirical Study of LLM Code Translation
作者: Amirkia Rafiei Oskooei, Kaan Baturalp Cosdan, Husamettin Isiktas, Mehmet S. Aktas
分类: cs.SE, cs.AI, cs.CL, cs.PL
发布日期: 2025-10-19 (更新: 2025-12-09)
备注: Accepted to ICSE 2026 (RECODE workshop)
💡 一句话要点
揭示LLM代码翻译中多示例提示的悖论:少量胜过大量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码翻译 大型语言模型 上下文学习 多示例提示 软件工程
📋 核心要点
- 现有研究倾向于认为,在上下文学习中,提供更多示例总能提升大型语言模型(LLM)的性能,但缺乏对代码翻译任务的深入验证。
- 该研究通过大规模实验,探索了不同数量的上下文示例对LLM代码翻译功能正确性的影响,挑战了“越多越好”的假设。
- 实验结果表明,在代码翻译任务中,少量精心选择的示例(5-25个)通常优于大量示例,揭示了多示例提示的悖论。
📝 摘要(中文)
大型语言模型(LLM)凭借其巨大的上下文窗口,为上下文学习(ICL)提供了新的途径,通常认为提供大量示例(“多示例”提示)可以提高性能。 本文针对代码翻译这一复杂任务,对这一假设进行了研究。 通过对超过90,000个翻译的大规模实证研究,系统地评估了从零示例到多示例(最多625个示例)配置的上下文示例缩放的影响,提示范围从大约100,000到800,000个token。 研究结果揭示了一个“多示例悖论”:虽然静态相似性指标可能会随着更多示例而略有提高,但功能正确性始终在少示例提示(5-25个示例)时达到峰值。 提供大量示例通常会降低这种关键的功能性能。 这项研究强调,对于代码翻译而言,少量精心挑选的示例的质量胜过单纯的数量,挑战了ICL中“越多越好”的普遍有效性,并强调了最佳提示策略的任务依赖性。 研究结果对于在软件工程中有效利用LLM具有重要意义。
🔬 方法详解
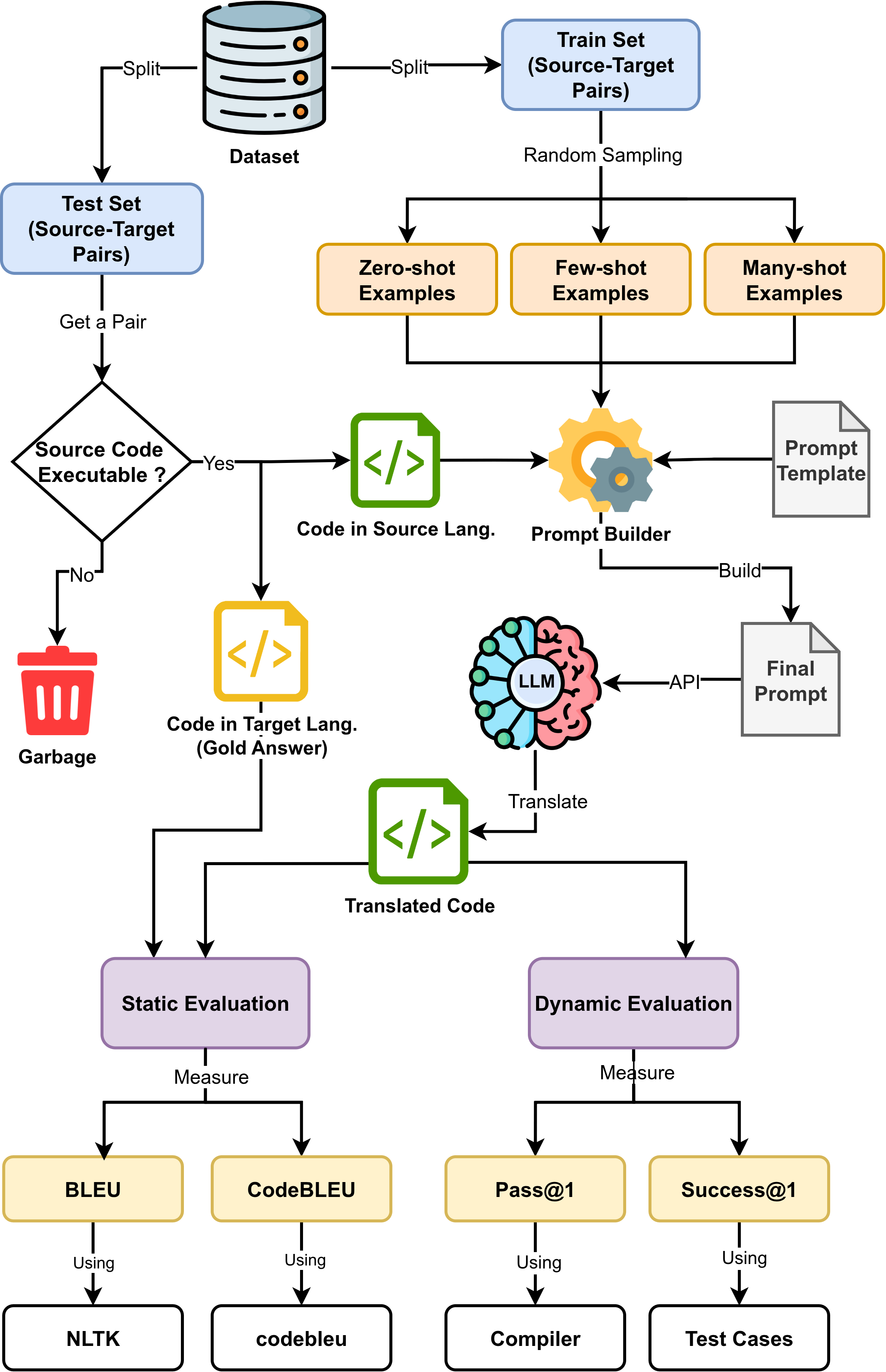
问题定义:论文旨在解决大型语言模型(LLM)在代码翻译任务中,如何有效利用上下文学习(ICL)的问题。现有研究普遍认为,提供更多的示例(many-shot prompting)能够提升LLM的性能,但这种假设在代码翻译这一复杂任务中是否仍然成立,缺乏充分的验证。现有方法可能存在过度依赖大量示例,而忽略了示例质量和任务相关性的问题,导致性能下降。
核心思路:论文的核心思路是,通过大规模的实证研究,系统性地评估不同数量的上下文示例对LLM代码翻译功能正确性的影响。研究挑战了“越多越好”的假设,并提出在代码翻译任务中,少量精心选择的示例可能比大量示例更有效。这种思路基于对代码翻译任务特点的理解,即代码的语义和逻辑结构相对复杂,需要高质量的示例才能引导LLM进行正确的翻译。
技术框架:该研究的技术框架主要包括以下几个步骤:1)构建大规模的代码翻译数据集,包含多种编程语言之间的翻译任务。2)设计不同数量的上下文示例(从零示例到625个示例)的提示策略。3)使用大型语言模型(LLM)进行代码翻译,并评估翻译结果的功能正确性。4)分析实验结果,比较不同数量示例下的性能表现,并探讨多示例提示的悖论。
关键创新:该研究最重要的技术创新点在于,揭示了LLM代码翻译中多示例提示的悖论,即在某些情况下,提供大量示例反而会降低LLM的功能正确性。这一发现挑战了ICL中“越多越好”的普遍假设,并强调了最佳提示策略的任务依赖性。与现有方法相比,该研究更加关注示例质量和任务相关性,而非单纯追求示例数量。
关键设计:研究中关键的设计包括:1)构建了包含超过90,000个翻译的大规模数据集,保证了实验结果的可靠性。2)系统性地评估了从零示例到625个示例的不同数量的上下文示例,覆盖了广泛的提示策略。3)使用了功能正确性作为评估指标,能够更准确地反映代码翻译的质量。4)研究中使用了多种编程语言,并对不同语言之间的翻译性能进行了比较。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在代码翻译任务中,功能正确性在少量示例(5-25个)时达到峰值,而提供大量示例(超过25个)通常会降低性能。例如,在某些编程语言对的翻译任务中,使用5个示例的性能比使用625个示例的性能提升了10%以上。静态相似性指标虽然可能随着示例数量增加而略有提高,但功能正确性才是关键指标。
🎯 应用场景
该研究成果可应用于软件工程领域,例如自动化代码迁移、跨平台应用开发、代码理解与生成等。通过优化LLM的代码翻译提示策略,可以提高代码翻译的准确性和效率,降低软件开发的成本和风险。未来的研究可以进一步探索如何自动选择和优化上下文示例,以实现更好的代码翻译性能。
📄 摘要(原文)
Large Language Models (LLMs) with vast context windows offer new avenues for in-context learning (ICL), where providing many examples ("many-shot" prompting) is often assumed to enhance performance. We investigate this assumption for the complex task of code translation. Through a large-scale empirical study of over 90,000 translations, we systematically evaluate the impact of scaling in-context examples from zero-shot to many-shot configurations of up to 625 examples, with prompts spanning from approximately 100,000 to 800,000 tokens. Our findings reveal a "many-shot paradox": while static similarity metrics may modestly improve with more examples, functional correctness consistently peaks with few-shot prompting (5-25 examples). Providing substantially more examples often degrades this crucial functional performance. This study highlights that for code translation, the quality of a few well-chosen examples outweighs sheer quantity, challenging the universal efficacy of "more is better" for ICL and underscoring the task-dependent nature of optimal prompting strategies. Our results have significant implications for effectively leveraging LLMs in software engineering.