Does GenAI Rewrite How We Write? An Empirical Study on Two-Million Preprints
作者: Minfeng Qi, Zhongmin Cao, Qin Wang, Ningran Li, Tianqing Zhu
分类: cs.CY, cs.AI, cs.CL, cs.DL
发布日期: 2025-10-18
💡 一句话要点
通过分析两百万篇预印本,揭示生成式AI对学术写作的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式AI 大型语言模型 学术出版 预印本分析 时间序列分析
📋 核心要点
- 现有研究缺乏对大型语言模型(LLMs)如何实际影响学术写作和出版的系统性证据。
- 论文提出一个多层次分析框架,整合时间序列模型、合作指标、语言分析和主题建模,评估LLMs的影响。
- 研究发现LLMs加速了提交周期,增加了语言复杂性,并促进了AI相关主题的扩展,但影响存在学科差异。
📝 摘要(中文)
预印本库已成为学术交流的核心基础设施。它们的发展改变了研究在期刊发表前传播和评估的方式。生成式大型语言模型(LLMs)通过改变稿件的写作方式,带来了进一步的潜在颠覆。尽管猜测很多,但关于LLMs是否以及如何重塑科学出版的系统性证据仍然有限。本文通过对2016-2025年间四个主要预印本库(arXiv、bioRxiv、medRxiv、SocArXiv)超过210万篇预印本的大规模分析来填补这一空白。我们引入了一个多层次分析框架,整合了中断时间序列模型、合作和生产力指标、语言分析和主题建模,以评估数量、作者身份、风格和学科方向的变化。我们的研究结果表明,LLMs加速了提交和修订周期,适度增加了语言复杂性,并不成比例地扩展了与AI相关的主题,而计算密集型领域受益更多。这些结果表明,LLMs的作用与其说是普遍的颠覆者,不如说是选择性的催化剂,放大了现有的优势并扩大了学科差距。通过记录这些动态,本文为评估生成式AI对学术出版的影响提供了第一个经验基础,并强调了在AI赋能的研究生态系统中,需要维护信任、公平和责任的治理框架。
🔬 方法详解
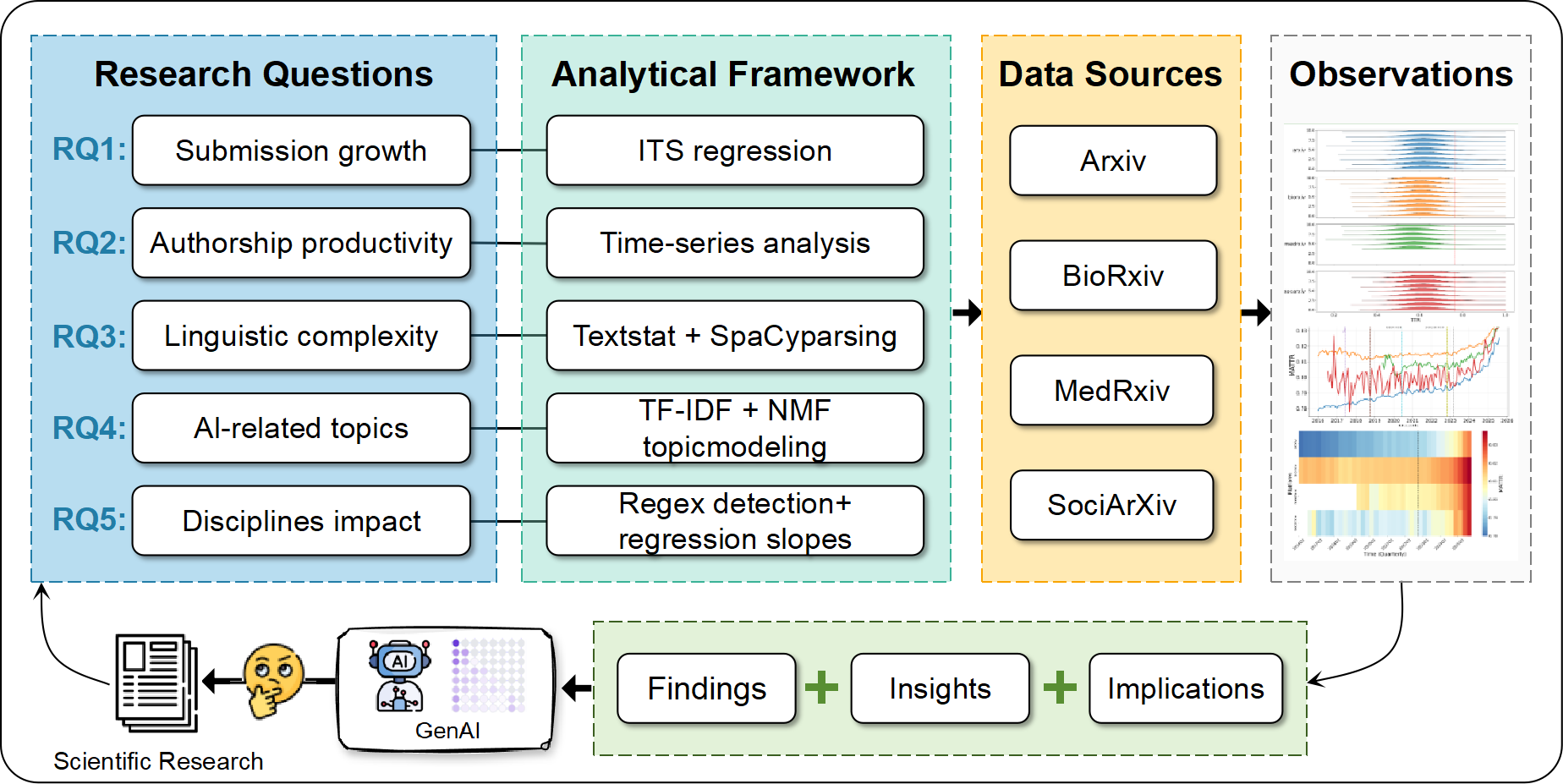
问题定义:论文旨在研究生成式大型语言模型(LLMs)对学术写作和出版的影响。现有方法缺乏对LLMs如何系统性地改变学术出版流程、作者行为、写作风格和研究主题的量化分析,导致对LLMs影响的理解不够全面和深入。
核心思路:论文的核心思路是通过大规模分析预印本数据,量化LLMs对学术出版的影响。通过构建多层次分析框架,从数量、作者身份、写作风格和学科方向等多个维度评估LLMs带来的变化,从而揭示LLMs在学术研究中的实际作用。
技术框架:论文的技术框架主要包括以下几个阶段: 1. 数据收集:收集来自arXiv、bioRxiv、medRxiv和SocArXiv四个主要预印本库的超过210万篇预印本数据。 2. 数据预处理:对收集到的数据进行清洗、去重和格式化等预处理操作。 3. 多层次分析: - 中断时间序列模型:分析LLMs引入前后预印本提交数量的变化。 - 合作和生产力指标:评估LLMs对作者合作模式和研究生产力的影响。 - 语言分析:使用自然语言处理技术分析预印本的语言风格变化,例如词汇复杂度和句法结构。 - 主题建模:使用主题模型识别预印本的研究主题,并分析LLMs对不同主题的影响。 4. 结果分析与可视化:对分析结果进行统计分析和可视化展示,揭示LLMs对学术出版的整体影响和学科差异。
关键创新:论文的关键创新在于: 1. 大规模数据分析:首次对超过200万篇预印本进行大规模分析,提供了更可靠的统计证据。 2. 多层次分析框架:整合了多种分析方法,从多个维度评估LLMs的影响,避免了单一视角的局限性。 3. 实证研究:通过实证研究揭示了LLMs对学术出版的实际影响,而非仅仅停留在理论推测层面。
关键设计:论文的关键设计包括: 1. 中断时间序列模型:选择合适的时间点作为LLMs引入的标志,并使用时间序列模型分析LLMs引入前后预印本提交数量的变化趋势。 2. 语言分析指标:选择合适的语言复杂度指标,例如Flesch Reading Ease和Gunning Fog Index,来量化预印本的语言风格变化。 3. 主题模型:使用LDA或NMF等主题模型,并选择合适的主题数量,以识别预印本的研究主题。
🖼️ 关键图片


📊 实验亮点
研究发现,LLMs加速了预印本的提交和修订周期,适度增加了语言复杂性,并显著扩展了AI相关主题的研究。计算密集型领域受益更多,表明LLMs对不同学科的影响存在差异。例如,AI相关主题的预印本数量显著增加,而其他领域的变化相对较小。
🎯 应用场景
该研究成果可应用于学术出版领域,帮助科研人员、出版机构和政策制定者更好地理解和应对生成式AI带来的影响。研究结果可以指导学术出版流程的优化,促进科研合作,并为制定合理的AI治理框架提供依据,从而维护学术研究的信任、公平和责任。
📄 摘要(原文)
Preprint repositories become central infrastructures for scholarly communication. Their expansion transforms how research is circulated and evaluated before journal publication. Generative large language models (LLMs) introduce a further potential disruption by altering how manuscripts are written. While speculation abounds, systematic evidence of whether and how LLMs reshape scientific publishing remains limited. This paper addresses the gap through a large-scale analysis of more than 2.1 million preprints spanning 2016--2025 (115 months) across four major repositories (i.e., arXiv, bioRxiv, medRxiv, SocArXiv). We introduce a multi-level analytical framework that integrates interrupted time-series models, collaboration and productivity metrics, linguistic profiling, and topic modeling to assess changes in volume, authorship, style, and disciplinary orientation. Our findings reveal that LLMs have accelerated submission and revision cycles, modestly increased linguistic complexity, and disproportionately expanded AI-related topics, while computationally intensive fields benefit more than others. These results show that LLMs act less as universal disruptors than as selective catalysts, amplifying existing strengths and widening disciplinary divides. By documenting these dynamics, the paper provides the first empirical foundation for evaluating the influence of generative AI on academic publishing and highlights the need for governance frameworks that preserve trust, fairness, and accountability in an AI-enabled research ecosystem.