Prompt Optimization via Retrieved Reasoning Assets and Multi-Agent Analysis
作者: Wonduk Seo, Juhyeon Lee, Junseo Koh, Hyunjin An, Jian Park, Seunghyun Lee, Haihua Chen, Yi Bu
分类: cs.MA, cs.AI, cs.CL, cs.HC, cs.IR
发布日期: 2025-10-18
备注: Preprint
💡 一句话要点
提出MA-SAPO框架,通过检索推理资产和多智能体分析优化Prompt
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Prompt优化 大型语言模型 多智能体系统 推理资产 知识检索
📋 核心要点
- 现有Prompt优化方法缺乏对Prompt优劣原因的深入理解,依赖难以解释的试错式改进。
- MA-SAPO框架通过多智能体协作,将评估结果与结构化推理相结合,指导Prompt的系统性编辑和优化。
- 实验表明,MA-SAPO在HelpSteer1/2基准测试上优于现有方法,验证了其有效性和优越性。
📝 摘要(中文)
Prompt优化已成为提高大型语言模型(LLM)性能的有效方法,可以替代模型重训练。然而,现有方法大多将评估视为黑盒,仅依赖数值分数,缺乏对Prompt成功或失败原因的深入理解。它们还严重依赖难以解释和控制的试错式改进。本文提出了MA-SAPO,一个用于分数感知Prompt优化的多智能体框架。与现有方法相比,MA-SAPO将评估结果与结构化推理相结合,以指导系统性编辑。该框架包含两个阶段:在推理阶段,智能体协作解释指标分数,诊断弱点,并综合有针对性的改进,存储为可重用的推理资产;在测试阶段,智能体检索这些资产来分析优化的Prompt,并仅应用基于证据的编辑。通过将评估信号转化为可解释的推理链,MA-SAPO产生更透明、可审计和可控的Prompt改进。在HelpSteer1/2基准测试上的实验表明,该方法优于单轮Prompt、检索增强基线和先前的多智能体策略,验证了其有效性。
🔬 方法详解
问题定义:现有Prompt优化方法主要依赖于黑盒评估和试错式改进,缺乏对Prompt优劣原因的深入理解,导致优化过程难以解释和控制。这些方法通常只关注数值分数,而忽略了Prompt本身的结构和逻辑,使得优化后的Prompt可能存在潜在的问题。
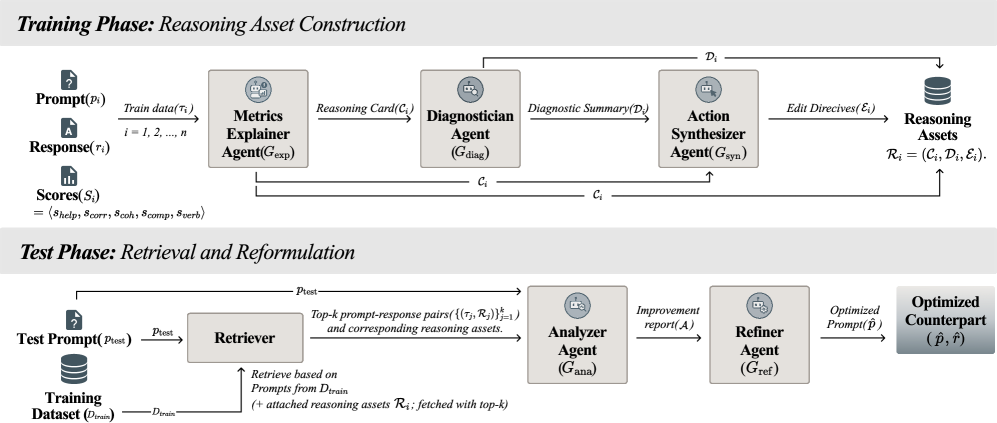
核心思路:MA-SAPO的核心思路是将评估结果与结构化推理相结合,通过多智能体协作的方式,对Prompt进行诊断和改进。该方法将评估信号转化为可解释的推理链,从而实现更透明、可审计和可控的Prompt优化。通过构建可重用的推理资产,MA-SAPO能够更好地利用历史经验,提高Prompt优化的效率和质量。
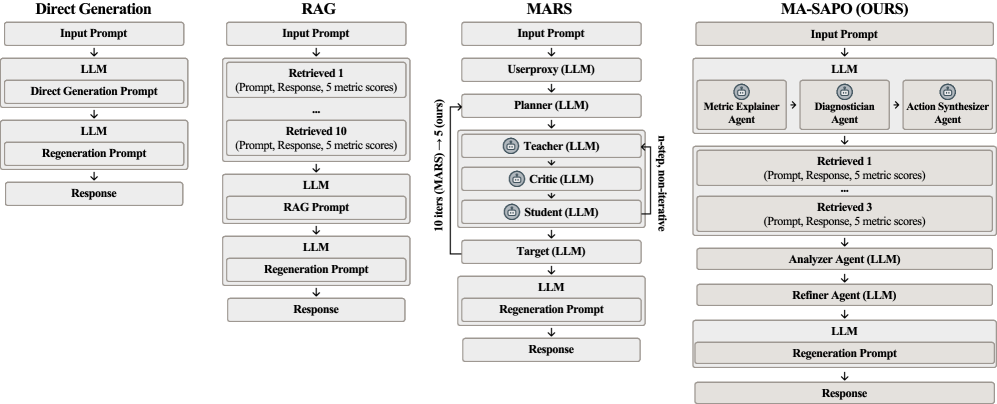
技术框架:MA-SAPO框架包含两个主要阶段:推理阶段和测试阶段。在推理阶段,多个智能体协作分析Prompt的性能,解释指标分数,诊断Prompt的弱点,并综合有针对性的改进建议。这些改进建议被存储为可重用的推理资产。在测试阶段,智能体检索相关的推理资产,分析优化的Prompt,并仅应用基于证据的编辑。整个框架通过迭代的方式,不断优化Prompt的性能。
关键创新:MA-SAPO的关键创新在于将评估结果与结构化推理相结合,构建可重用的推理资产。与现有方法相比,MA-SAPO能够更深入地理解Prompt的优劣原因,并基于证据进行Prompt优化。此外,MA-SAPO的多智能体协作机制能够充分利用不同智能体的知识和经验,提高Prompt优化的效率和质量。
关键设计:MA-SAPO的关键设计包括:1) 推理资产的构建和存储方式,需要保证推理资产的可重用性和可扩展性;2) 智能体之间的协作机制,需要保证智能体之间的信息共享和协同工作;3) Prompt编辑策略,需要保证Prompt编辑的有效性和安全性。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MA-SAPO在HelpSteer1/2基准测试上取得了显著的性能提升,优于单轮Prompt、检索增强基线和先前的多智能体策略。具体的性能数据和提升幅度在论文中未详细说明,属于未知信息。这些结果验证了MA-SAPO框架的有效性和优越性。
🎯 应用场景
MA-SAPO框架可应用于各种需要Prompt优化的场景,例如问答系统、文本生成、对话系统等。通过提高Prompt的质量,可以显著提升LLM在这些应用中的性能。该研究的潜在价值在于提供了一种更透明、可控和高效的Prompt优化方法,有助于推动LLM在实际应用中的广泛应用。
📄 摘要(原文)
Prompt optimization has emerged as an effective alternative to retraining for improving the performance of Large Language Models (LLMs). However, most existing approaches treat evaluation as a black box, relying solely on numerical scores while offering limited insight into why a prompt succeeds or fails. They also depend heavily on trial-and-error refinements, which are difficult to interpret and control. In this paper, we introduce MA-SAPO, a Multi-Agent framework for Score-Aware Prompt Optimization. Compared to prior methods, MA-SAPO explicitly couples evaluation outcomes with structured reasoning to guide systematic edits. The framework specifically consists of two stages: during the Reasoning Phase, agents collaboratively explain metric scores, diagnose weaknesses, and synthesize targeted refinements that are stored as reusable reasoning assets; during the Test Phase, agents retrieve these assets to analyze optimized prompts and apply only evidence-grounded edits. By turning evaluation signals into interpretable reasoning chains, MA-SAPO produces prompt refinements that are more transparent, auditable, and controllable. Experiments on the HelpSteer1/2 benchmarks demonstrate consistent improvements over single-pass prompting, retrieval-augmented baselines, and prior multi-agent strategies, validating the effectiveness of our approach.