Conformal Prediction in The Loop: A Feedback-Based Uncertainty Model for Trajectory Optimization
作者: Han Wang, Chao Ning
分类: math.OC, cs.AI, cs.RO, eess.SY, math.ST
发布日期: 2025-10-18
备注: Accepted by NeurIPS 2025 Main Track
💡 一句话要点
提出基于反馈的保形预测框架,用于轨迹优化中的不确定性建模与风险控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 保形预测 轨迹优化 不确定性建模 反馈控制 风险分配
📋 核心要点
- 现有轨迹优化方法依赖单向预测区域,决策信息无法反馈指导保形预测(CP),导致性能受限。
- 提出基于反馈的保形预测(Fb-CP)框架,利用已实现轨迹信息调整后验风险,迭代优化预测区域。
- 实验证明,该方法能有效提升轨迹性能,且理论保证预测区域的覆盖率和安全性,并可扩展至处理分布偏移。
📝 摘要(中文)
本文提出了一种新颖的基于反馈的保形预测(Fb-CP)框架,用于收缩时域轨迹优化,并具有整个任务时间内的联合风险约束。具体而言,通过充分利用已实现的轨迹来调整后验允许风险,开发了一种基于CP的后验风险计算方法,然后将其分配给未来时间以更新预测区域。通过这种方式,已实现轨迹中的信息被连续反馈到CP,从而能够对预测区域进行有吸引力的基于反馈的调整,并可证明在线改进轨迹性能。此外,我们从理论上证明,这种调整始终保持预测区域的覆盖保证,从而确保可证明的安全性。此外,我们开发了一种以决策为中心的迭代风险分配算法,该算法具有理论收敛性分析,用于分配与Fb-CP紧密对齐的后验允许风险。此外,我们将所提出的方法扩展到处理分布偏移。通过基准实验证明了该方法的有效性和优越性。
🔬 方法详解
问题定义:现有的轨迹优化方法通常采用顺序决策方案,其中决策完全依赖于预测区域,而决策过程中的信息无法反馈给保形预测(CP)模块,从而限制了CP的性能和轨迹优化的效果。尤其是在不确定性环境中,这种单向依赖关系可能导致次优的轨迹规划。
核心思路:本文的核心思路是将轨迹优化过程中的实际轨迹信息反馈给保形预测模块,形成一个闭环反馈系统。通过分析已实现的轨迹,可以更准确地估计后验风险,并据此调整未来的预测区域,从而提高轨迹优化的性能和安全性。这种反馈机制使得预测区域能够动态适应环境变化,并更好地利用历史信息。
技术框架:该框架包含以下主要模块:1) 基于保形预测的初始预测区域生成;2) 轨迹优化器,根据预测区域生成轨迹;3) 后验风险计算模块,利用已实现的轨迹信息计算后验允许风险;4) 风险分配模块,将后验允许风险分配给未来时间步;5) 预测区域更新模块,根据分配的风险更新预测区域。整个流程是一个迭代过程,不断利用反馈信息优化轨迹。
关键创新:该方法最重要的创新在于引入了反馈机制,将轨迹优化过程中的实际轨迹信息反馈给保形预测模块。这种反馈机制使得预测区域能够动态适应环境变化,并更好地利用历史信息。此外,该方法还提出了一种新的后验风险计算方法,能够更准确地估计风险,并保证预测区域的覆盖率。
关键设计:该方法采用了一种决策为中心的迭代风险分配算法,用于将后验允许风险分配给未来时间步。该算法具有理论收敛性分析,能够保证算法的稳定性和有效性。此外,该方法还考虑了分布偏移问题,并提出了一种扩展方法来处理分布偏移。
🖼️ 关键图片

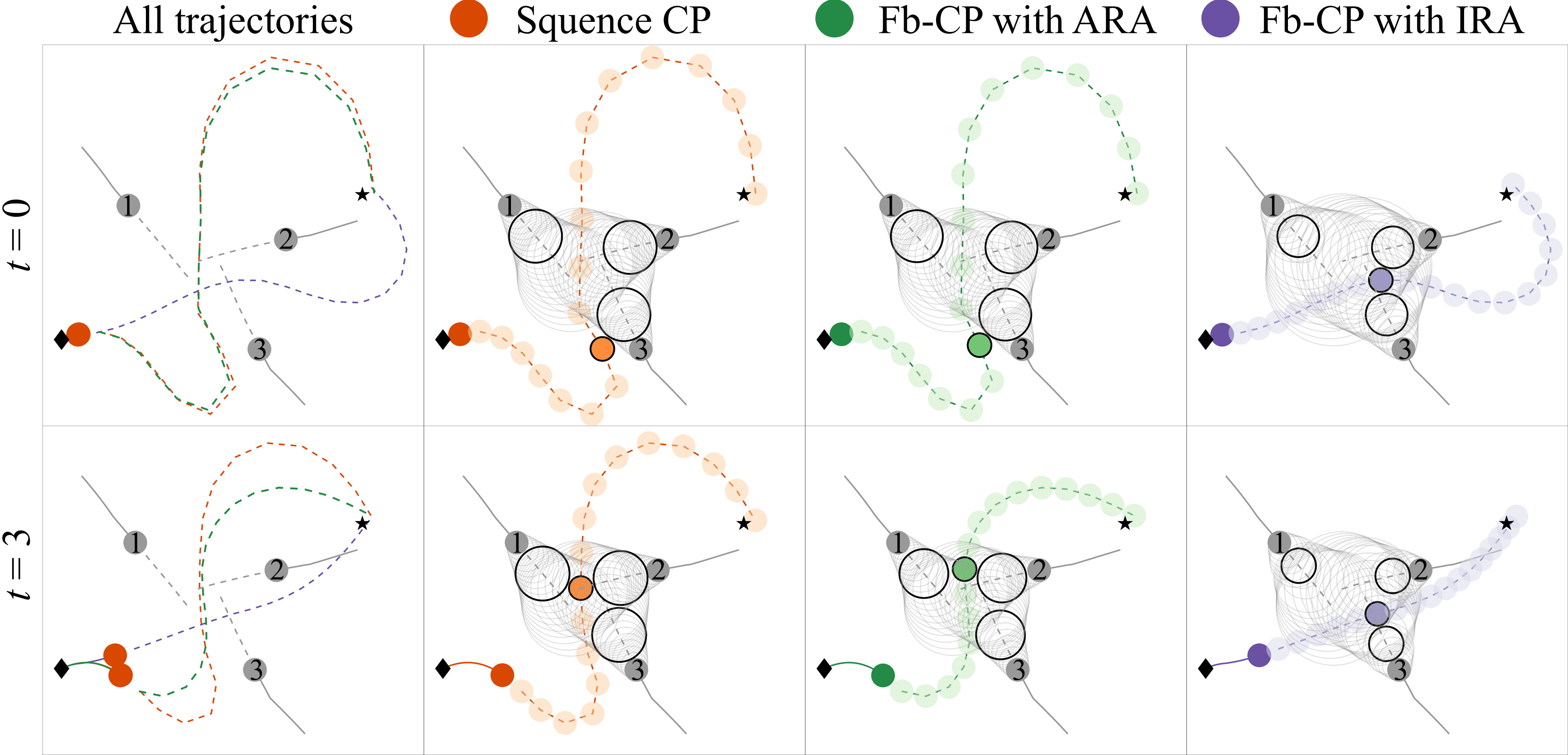

📊 实验亮点
论文通过基准实验验证了所提出方法的有效性和优越性。实验结果表明,与现有方法相比,该方法能够显著提高轨迹性能,并保证预测区域的覆盖率。具体性能提升数据未知,但强调了在基准测试中优于现有方法。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、无人机飞行等领域,尤其是在不确定性较高和安全性要求严格的环境中。通过利用反馈信息动态调整预测区域,可以提高轨迹规划的鲁棒性和可靠性,降低事故发生的风险,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Conformal Prediction (CP) is a powerful statistical machine learning tool to construct uncertainty sets with coverage guarantees, which has fueled its extensive adoption in generating prediction regions for decision-making tasks, e.g., Trajectory Optimization (TO) in uncertain environments. However, existing methods predominantly employ a sequential scheme, where decisions rely unidirectionally on the prediction regions, and consequently the information from decision-making fails to be fed back to instruct CP. In this paper, we propose a novel Feedback-Based CP (Fb-CP) framework for shrinking-horizon TO with a joint risk constraint over the entire mission time. Specifically, a CP-based posterior risk calculation method is developed by fully leveraging the realized trajectories to adjust the posterior allowable risk, which is then allocated to future times to update prediction regions. In this way, the information in the realized trajectories is continuously fed back to the CP, enabling attractive feedback-based adjustments of the prediction regions and a provable online improvement in trajectory performance. Furthermore, we theoretically prove that such adjustments consistently maintain the coverage guarantees of the prediction regions, thereby ensuring provable safety. Additionally, we develop a decision-focused iterative risk allocation algorithm with theoretical convergence analysis for allocating the posterior allowable risk which closely aligns with Fb-CP. Furthermore, we extend the proposed method to handle distribution shift. The effectiveness and superiority of the proposed method are demonstrated through benchmark experiments.