Publication Trend Analysis and Synthesis via Large Language Model: A Case Study of Engineering in PNAS
作者: Mason Smetana, Lev Khazanovich
分类: cs.DL, cs.AI, cs.CL, cs.LG
发布日期: 2025-10-17
备注: 35 pages, 10 figures
💡 一句话要点
提出基于LLM的框架,用于量化主题趋势并绘制科学知识演变图谱
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 主题分析 科学文献 知识图谱 自然语言处理
📋 核心要点
- 现有方法难以捕捉科学知识的动态演变,存在语言复杂、学科结构静态和关键词系统稀疏等问题。
- 利用大型语言模型,通过两阶段分类流程,从摘要到全文,挖掘主题趋势和跨主题联系。
- 实验表明,该方法能够独立恢复期刊的编辑结构,无需先验知识,可有效检测主题趋势。
📝 摘要(中文)
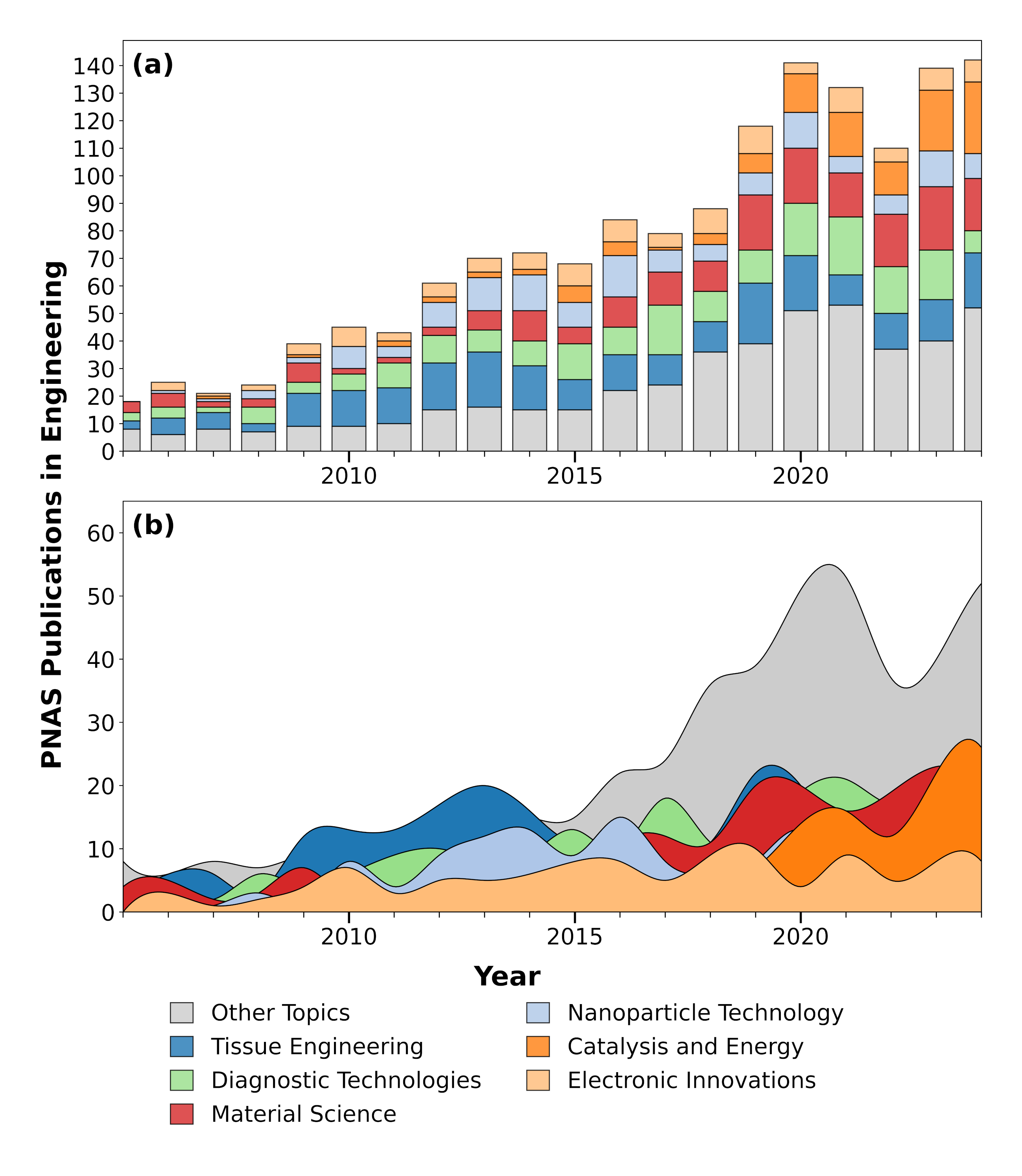
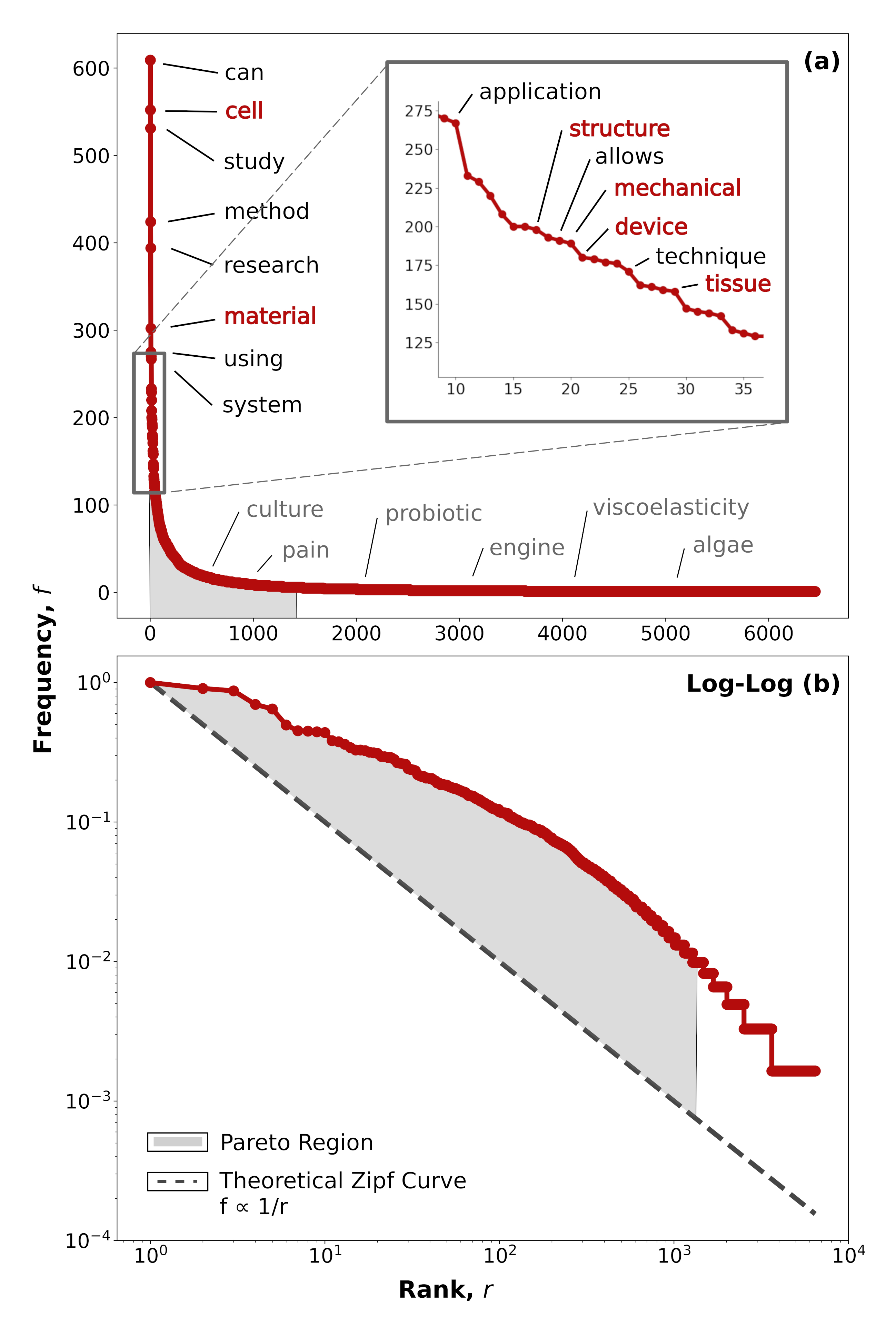
本研究针对科学文献日益复杂的语言、静态的学科结构以及可能稀疏的关键词系统等问题,提出了一种基于大型语言模型(LLM)的自适应框架,用于量化主题趋势并绘制科学知识的演变图谱。该方法以美国国家科学院院刊(PNAS)上发表的1500多篇工程学文章为案例,这些文章的研究范围广泛且深入。该框架采用两阶段分类流程:首先基于摘要确定每篇文章的主要主题类别,然后进行全文分析以分配次要分类,从而揭示语料库中潜在的跨主题联系。传统的自然语言处理(NLP)方法,如词袋模型(BoW)和词频-逆文档频率(TF-IDF),验证了所得到的主题结构,同时也表明独立的词频分析可能不足以绘制具有高度多样性的领域。最后,主要分类和次要分类之间的不相交图表示揭示了主题之间隐含的联系,这些联系在单独分析摘要或关键词时可能不太明显。研究结果表明,该方法能够独立地恢复期刊编辑嵌入的大部分结构,而无需事先了解其现有的双重分类模式(例如,生物学研究也被归类为工程学)。该框架为检测潜在的主题趋势和提供科学进展的高层次概述提供了一个强大的工具。
🔬 方法详解
问题定义:当前科学文献分析面临的挑战在于如何有效地捕捉科学知识的动态演变。传统的关键词分析和人工分类方法难以应对日益增长的文献数量和学科交叉的复杂性。现有的方法往往依赖于静态的学科结构和稀疏的关键词系统,无法充分揭示隐藏在文献中的主题趋势和跨学科联系。
核心思路:本研究的核心思路是利用大型语言模型(LLM)的强大语义理解能力,自动地从科学文献中提取主题信息,并构建主题之间的关联关系。通过两阶段分类流程,首先基于摘要进行粗粒度的主题分类,然后通过全文分析进行细粒度的主题分类,从而揭示潜在的跨主题联系。这种方法能够克服传统方法的局限性,更全面地捕捉科学知识的演变趋势。
技术框架:该框架包含以下主要模块:1) 数据收集:收集PNAS期刊上发表的工程学文章,构建数据集。2) 预处理:对文本数据进行清洗和预处理,包括去除停用词、词干提取等。3) 主要主题分类:使用LLM对文章摘要进行分类,确定文章的主要主题类别。4) 次要主题分类:使用LLM对文章全文进行分析,确定文章的次要主题类别。5) 主题关联分析:构建主要主题和次要主题之间的不相交图,揭示主题之间的隐含联系。6) 结果验证:使用传统的NLP方法(如BoW和TF-IDF)验证所得到的主题结构。
关键创新:该研究的关键创新在于利用LLM进行科学文献的主题分析,并构建主题之间的关联关系。与传统的关键词分析方法相比,LLM能够更好地理解文本的语义信息,从而更准确地提取主题。此外,通过两阶段分类流程和不相交图表示,该研究能够揭示隐藏在文献中的跨主题联系,为科学知识的演变分析提供了新的视角。
关键设计:在两阶段分类流程中,LLM的选择和训练至关重要。研究中使用的LLM需要具备强大的语义理解能力和泛化能力。此外,损失函数的选择和参数的调整也会影响分类的准确性。在构建不相交图时,需要选择合适的相似度度量方法来衡量主题之间的关联程度。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
该研究表明,基于LLM的框架能够独立地恢复PNAS期刊的编辑结构,而无需事先了解其现有的双重分类模式。这表明该方法具有很强的泛化能力和鲁棒性。此外,该研究还发现,传统的词频分析方法可能不足以绘制具有高度多样性的领域,突显了LLM在科学文献分析中的优势。具体的性能数据和提升幅度在论文中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于多个领域,例如:科学知识图谱构建、科研趋势预测、学科交叉研究、科技情报分析等。通过自动分析大量的科学文献,可以帮助研究人员快速了解领域动态,发现潜在的研究方向,促进学科交叉和创新。此外,该方法还可以用于评估科研成果的影响力,为科研管理和决策提供支持。
📄 摘要(原文)
Scientific literature is increasingly siloed by complex language, static disciplinary structures, and potentially sparse keyword systems, making it cumbersome to capture the dynamic nature of modern science. This study addresses these challenges by introducing an adaptable large language model (LLM)-driven framework to quantify thematic trends and map the evolving landscape of scientific knowledge. The approach is demonstrated over a 20-year collection of more than 1,500 engineering articles published by the Proceedings of the National Academy of Sciences (PNAS), marked for their breadth and depth of research focus. A two-stage classification pipeline first establishes a primary thematic category for each article based on its abstract. The subsequent phase performs a full-text analysis to assign secondary classifications, revealing latent, cross-topic connections across the corpus. Traditional natural language processing (NLP) methods, such as Bag-of-Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF), confirm the resulting topical structure and also suggest that standalone word-frequency analyses may be insufficient for mapping fields with high diversity. Finally, a disjoint graph representation between the primary and secondary classifications reveals implicit connections between themes that may be less apparent when analyzing abstracts or keywords alone. The findings show that the approach independently recovers much of the journal's editorially embedded structure without prior knowledge of its existing dual-classification schema (e.g., biological studies also classified as engineering). This framework offers a powerful tool for detecting potential thematic trends and providing a high-level overview of scientific progress.