BeLLMan: Controlling LLM Congestion
作者: Tella Rajashekhar Reddy, Atharva Deshmukh, Karan Tandon, Rohan Gandhi, Anjaly Parayil, Debopam Bhattacherjee
分类: cs.DC, cs.AI, cs.CL, cs.NI
发布日期: 2025-10-17
备注: To be presented at FAISYS 2025
💡 一句话要点
BeLLMan:通过主动控制LLM输出长度缓解拥塞,降低延迟和能耗。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 拥塞控制 推理优化 动态调整 负载均衡
📋 核心要点
- 现有LLM应用无法感知底层基础设施负载,导致拥塞时推理延迟增加,影响用户体验。
- beLLMan通过基础设施向LLM应用发送信号,动态调整输出长度,缓解拥塞。
- 实验表明,beLLMan能显著降低推理延迟和能耗,同时提高请求处理量。
📝 摘要(中文)
大型语言模型(LLM)应用通常无法感知底层基础设施的状态,以自回归方式生成token,忽略系统负载,这可能导致推理延迟增加和用户体验下降。本文提出了一种名为beLLMan的控制器,它使LLM基础设施能够主动地、渐进地向LLM应用发送信号,以根据不断变化的系统负载调整输出长度。在配备H100 GPU的真实测试平台上,beLLMan有助于控制推理延迟(端到端延迟最多降低8倍),并在摘要工作负载的拥塞期间将能耗降低25%(同时处理的请求增加19%)。
🔬 方法详解
问题定义:论文旨在解决LLM推理服务在高负载下的拥塞问题。现有LLM应用通常以自回归方式生成token,无法根据系统负载动态调整输出长度,导致在高并发或资源受限的情况下,推理延迟显著增加,影响用户体验,甚至可能导致服务崩溃。
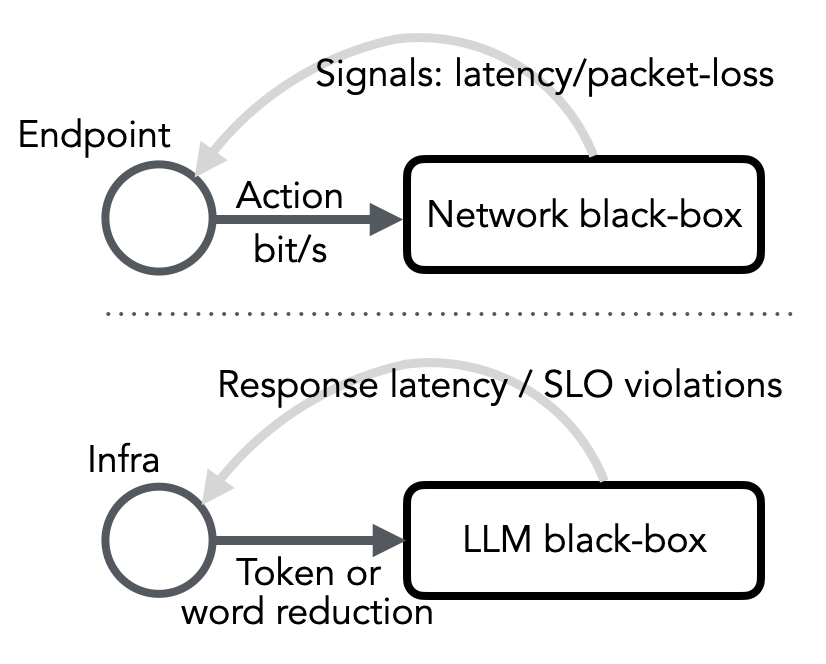
核心思路:beLLMan的核心思路是引入一个控制器,该控制器能够监测LLM基础设施的负载状态,并根据负载情况向LLM应用发送信号,指示其调整输出长度。通过动态调整输出长度,可以在拥塞期间减少每个请求的计算量,从而缓解拥塞,降低延迟。
技术框架:beLLMan的整体框架包含以下几个主要模块:1) 负载监测模块:负责监测LLM基础设施的负载状态,例如GPU利用率、内存占用率等。2) 控制器模块:根据负载监测模块的输出,决定是否需要调整LLM应用的输出长度,并生成相应的控制信号。3) LLM应用接口:LLM应用需要提供一个接口,用于接收控制器发送的控制信号,并根据信号调整输出长度。整个流程是闭环反馈控制,根据实际负载动态调整。
关键创新:beLLMan的关键创新在于它将LLM基础设施和LLM应用连接起来,实现了基础设施对LLM应用的主动控制。与传统的静态资源分配或请求调度方法不同,beLLMan能够根据实时负载动态调整LLM应用的行为,从而更有效地利用资源,缓解拥塞。
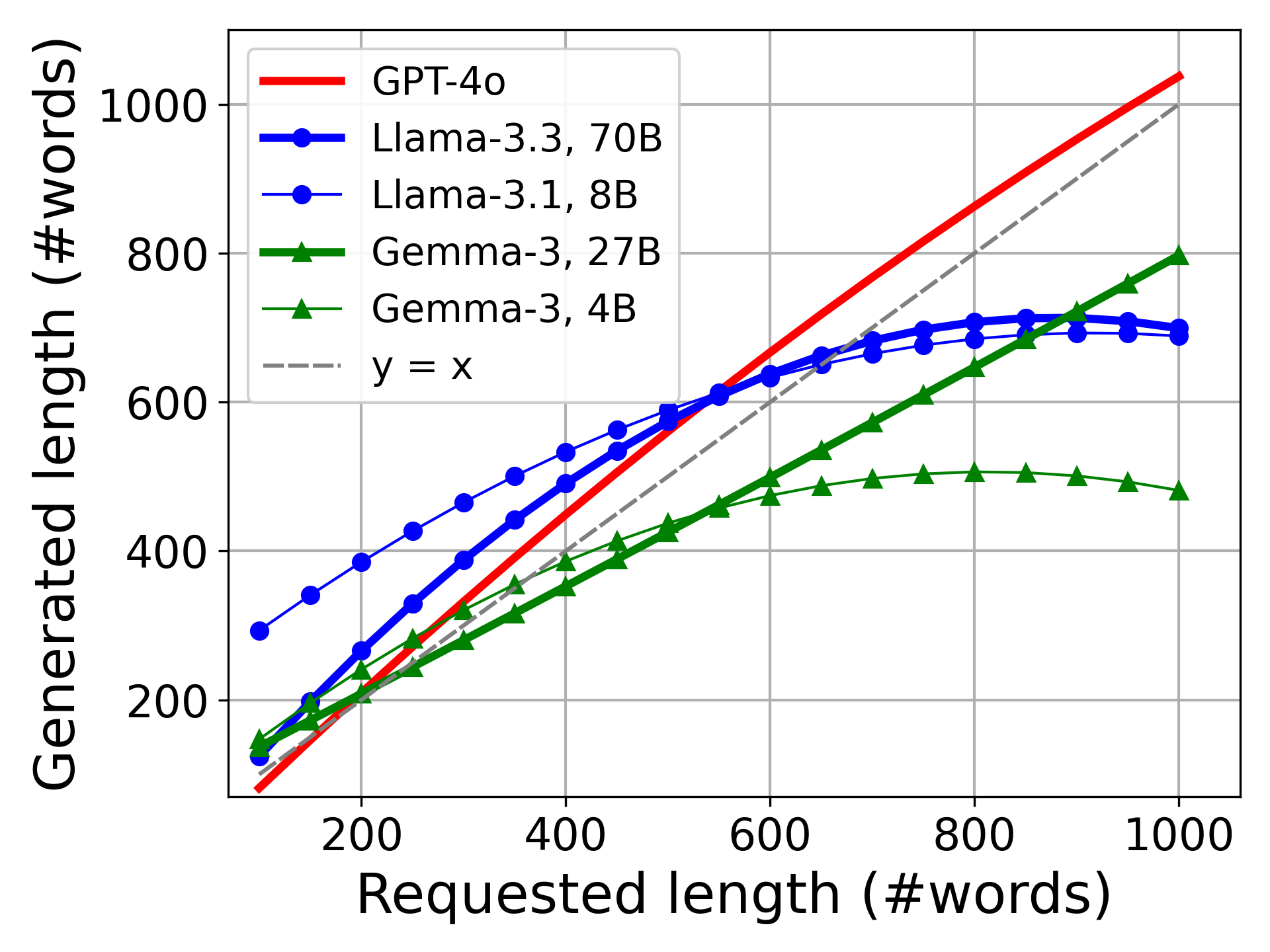
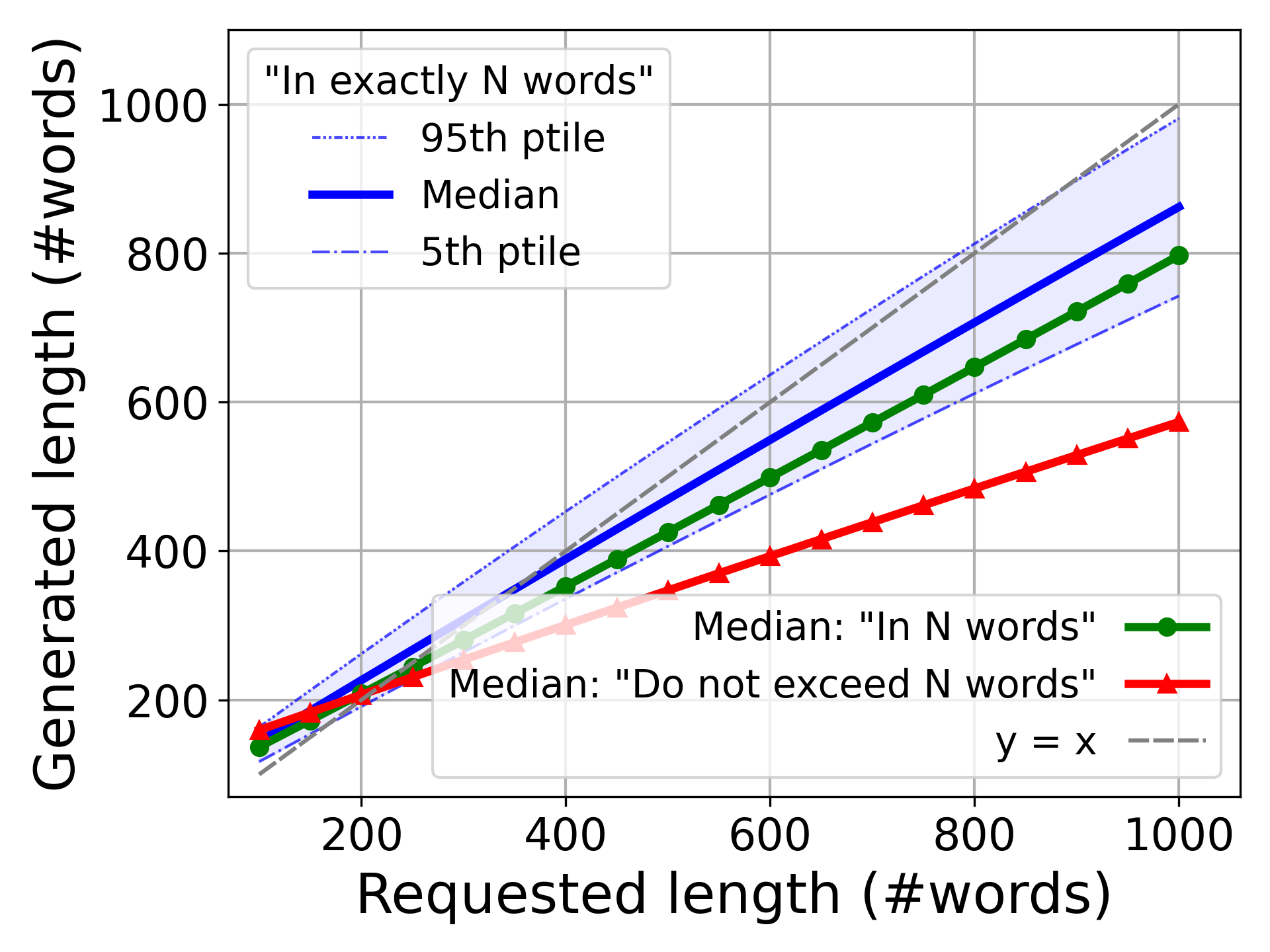
关键设计:控制器模块的设计是关键。论文中提到beLLMan是“first-cut controller”,具体控制算法细节未知。推测可能采用PID控制或类似的反馈控制算法,根据负载状态和目标延迟之间的误差,调整输出长度的调整幅度。LLM应用接口的设计也需要考虑如何平滑地调整输出长度,避免影响生成质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在配备H100 GPU的真实测试平台上,beLLMan能够显著降低LLM推理延迟(端到端延迟最多降低8倍),并在摘要工作负载的拥塞期间将能耗降低25%(同时处理的请求增加19%)。这些数据表明beLLMan在缓解LLM拥塞方面具有显著优势。
🎯 应用场景
beLLMan可应用于各种需要大规模LLM推理服务的场景,例如在线客服、智能助手、内容生成平台等。通过动态调整输出长度,可以在保证服务质量的前提下,提高系统吞吐量,降低延迟,并节省能源。该研究对于构建高效、可靠的LLM服务具有重要意义,并为未来的LLM基础设施优化提供了新的思路。
📄 摘要(原文)
Large language model (LLM) applications are blindfolded to the infrastructure underneath and generate tokens autoregressively, indifferent to the system load, thus risking inferencing latency inflation and poor user experience. Our first-cut controller, named beLLMan, enables the LLM infrastructure to actively and progressively signal the first-party LLM application to adjust the output length in response to changing system load. On a real testbed with H100 GPUs, beLLMan helps keep inferencing latency under control (upto 8X lower end-to-end latency) and reduces energy consumption by 25% (while serving 19% more requests) during periods of congestion for a summarization workload.