RoboGPT-R1: Enhancing Robot Planning with Reinforcement Learning
作者: Jinrui Liu, Bingyan Nie, Boyu Li, Yaran Chen, Yuze Wang, Shunsen He, Haoran Li
分类: cs.AI, cs.RO
发布日期: 2025-10-16 (更新: 2025-10-22)
💡 一句话要点
RoboGPT-R1:强化学习增强机器人规划能力,提升长时程操作任务性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人规划 强化学习 视觉语言模型 长时程任务 具身智能 监督微调 奖励函数
📋 核心要点
- 现有基于监督微调的大语言模型和视觉语言模型在复杂环境中执行长时程操作任务时,面临常识和推理能力不足的挑战。
- RoboGPT-R1采用两阶段微调框架,先通过监督学习获取知识,再通过强化学习提升视觉空间理解和推理能力。
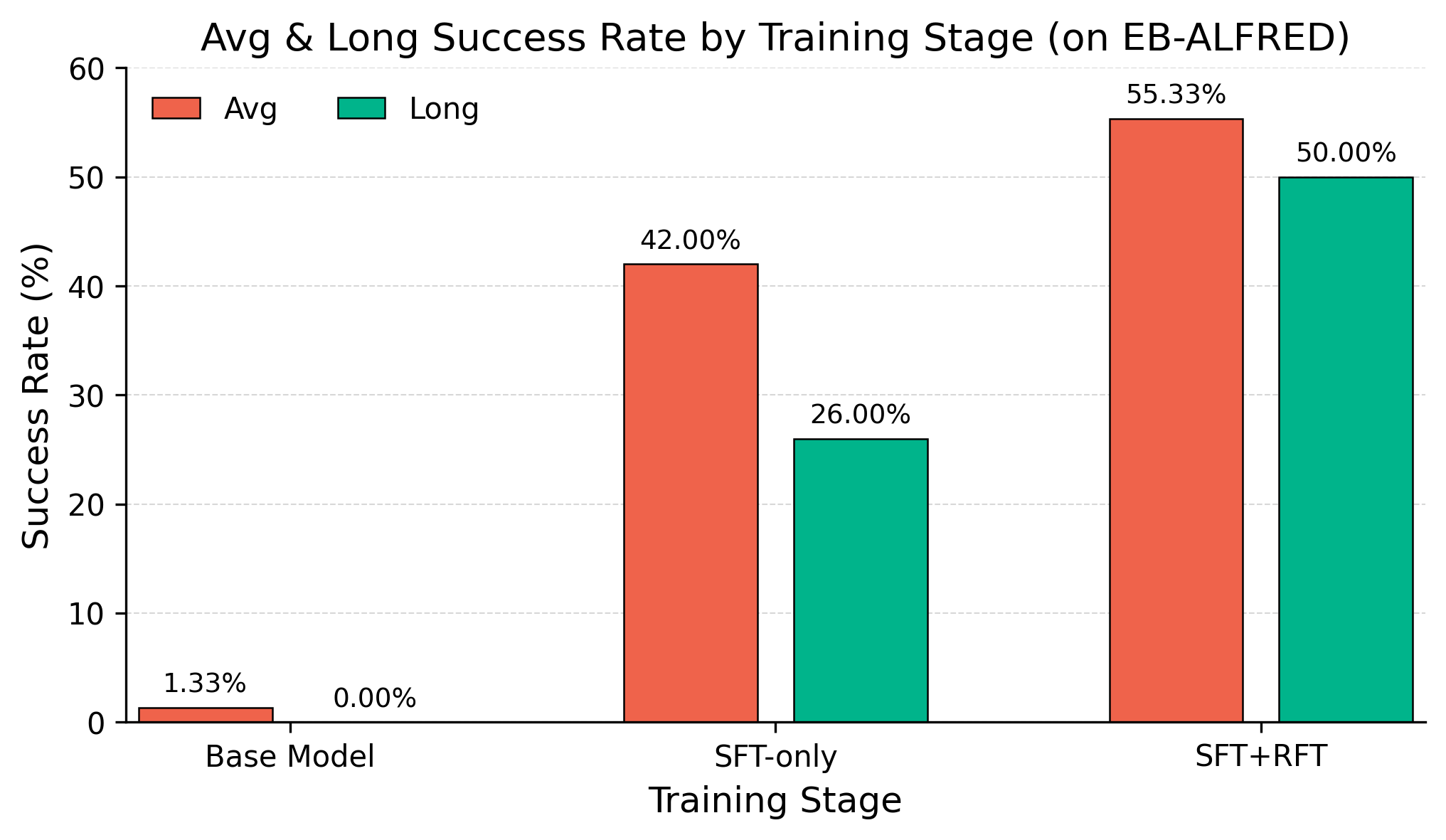
- 实验结果表明,在Qwen2.5-VL-3B上训练的RoboGPT-R1显著优于GPT-4o-mini和在Qwen2.5-VL-7B上训练的其他模型。
📝 摘要(中文)
为了提高具身智能体在长时程操作任务中完成复杂人类指令的推理能力,本文提出了RoboGPT-R1,一个用于具身规划的两阶段微调框架。该框架首先通过监督训练从专家序列中获取基础知识,然后利用强化学习解决模型在视觉空间理解和推理方面的不足。为了在多步推理任务中实现物理理解和动作序列一致性,设计了一种基于规则的奖励函数,同时考虑了长时程性能和环境中的动作约束。在Qwen2.5-VL-3B上训练的推理模型,在EmbodiedBench基准测试中,显著优于更大规模的模型GPT-4o-mini 21.33%,并且超过了在Qwen2.5-VL-7B上训练的其他工作 20.33%。
🔬 方法详解
问题定义:论文旨在解决机器人如何在复杂环境中,根据人类指令完成长时程操作任务的问题。现有方法,特别是基于监督微调的视觉语言模型,在物理世界的常识推理和长期规划方面存在不足,导致泛化能力差,无法很好地理解和执行复杂任务。
核心思路:论文的核心思路是结合监督学习和强化学习的优势。首先,利用监督学习从专家数据中学习基础知识,然后,通过强化学习来弥补模型在视觉空间理解和推理方面的不足,从而提升模型在复杂环境中的泛化能力和长期规划能力。
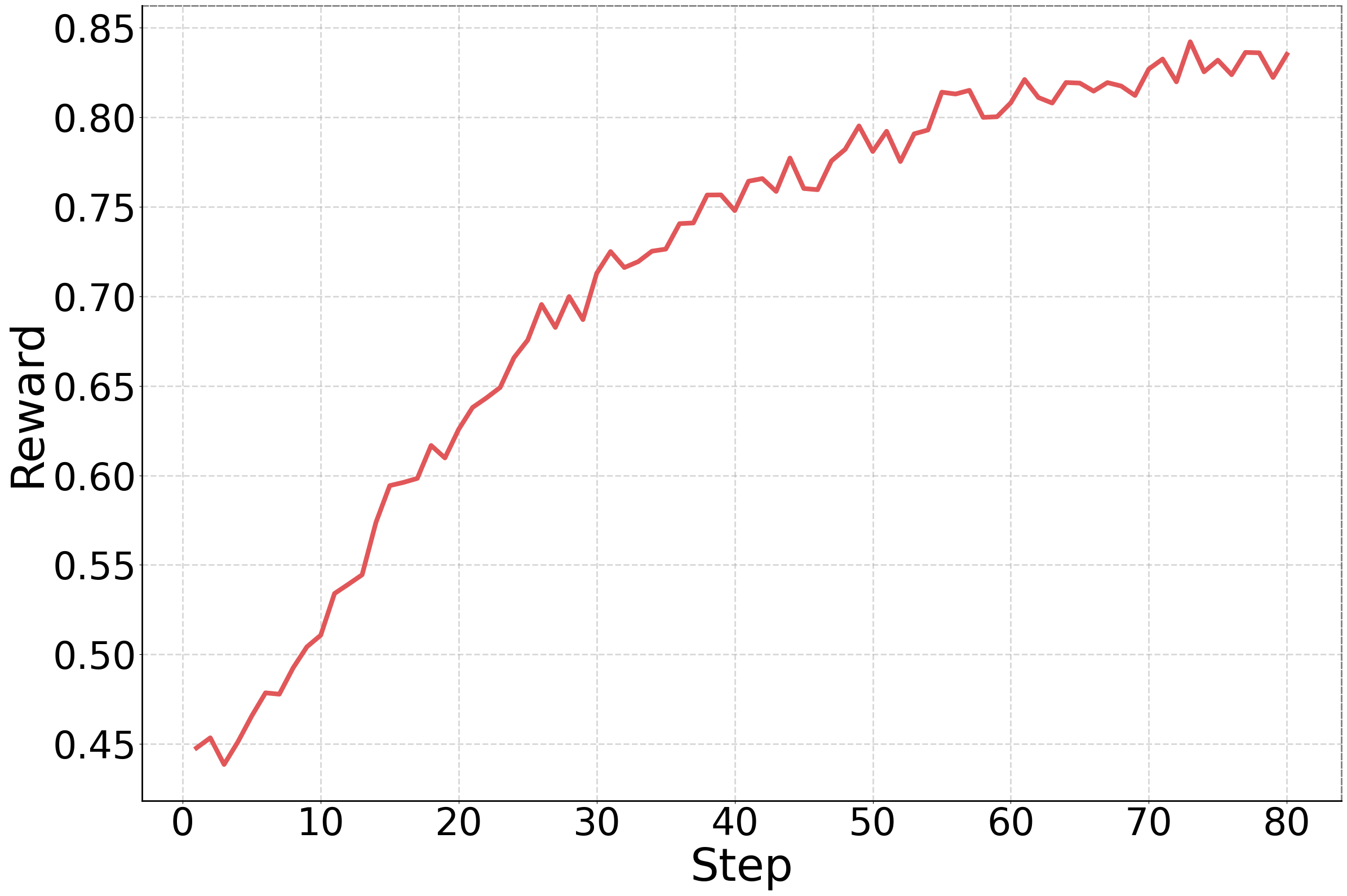
技术框架:RoboGPT-R1是一个两阶段的微调框架。第一阶段是监督微调(SFT),使用专家轨迹数据训练模型,使其具备初步的规划能力。第二阶段是强化学习(RL),通过与环境交互,利用奖励函数来优化模型的策略,使其更好地理解物理世界的约束,并做出更合理的决策。整体流程是从视觉输入开始,经过视觉语言模型处理,输出动作序列,然后执行动作,获得环境反馈,用于强化学习的训练。
关键创新:论文的关键创新在于结合了监督学习和强化学习,并设计了基于规则的奖励函数。这种结合方式能够有效地利用专家数据和环境反馈,提升模型的泛化能力和长期规划能力。奖励函数的设计同时考虑了长时程性能和动作约束,使得模型能够学习到更符合物理规律的动作序列。
关键设计:论文使用Qwen2.5-VL作为基础模型。奖励函数的设计是关键,它综合考虑了任务完成度、动作的物理可行性以及动作序列的一致性。具体来说,奖励函数可能包含以下几个部分:任务完成奖励、动作约束惩罚、动作序列平滑性奖励等。这些奖励项的权重需要根据具体任务进行调整,以达到最佳的训练效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RoboGPT-R1在EmbodiedBench基准测试中取得了显著的性能提升。具体来说,在Qwen2.5-VL-3B上训练的RoboGPT-R1模型,超越了更大规模的模型GPT-4o-mini 21.33%,并且超过了在Qwen2.5-VL-7B上训练的其他工作 20.33%。这些数据表明,该方法在提升机器人规划能力方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要机器人进行长时程操作任务的场景,例如智能家居、工业自动化、医疗辅助等。通过提升机器人的规划和推理能力,可以使其更好地理解人类指令,完成更复杂的任务,提高工作效率和服务质量。未来,该方法有望进一步扩展到更复杂的环境和任务中,实现更智能、更自主的机器人。
📄 摘要(原文)
Improving the reasoning capabilities of embodied agents is crucial for robots to complete complex human instructions in long-view manipulation tasks successfully. Despite the success of large language models and vision language models based on Supervised Fine-Tuning (SFT) in planning tasks, they continue facing challenges in performing long-horizon manipulation tasks in complex real-world environments, owing to their restricted common sense and reasoning capabilities. Considering that aligning general-purpose vision language models to robotic planning tasks via supervised fine-tuning suffers from poor generalization and insufficient physical understanding, we propose RoboGPT-R1, a two-stage fine-tuning framework for embodied planning. In this framework, supervised training acquires foundational knowledge through expert sequences, followed by RL to address the model's shortcomings in visual-spatial understanding and reasoning. To achieve physical understanding and action sequence consistency in multi-step reasoning tasks, we design a rule-based reward function that simultaneously considers long-horizon performance and action constraint in the environment. The reasoning model, trained on Qwen2.5-VL-3B, significantly outperforms the larger-scale model, GPT-4o-mini, by 21.33% and surpasses other work trained on Qwen2.5-VL-7B by 20.33% on the EmbodiedBench benchmark.