MCP Security Bench (MSB): Benchmarking Attacks Against Model Context Protocol in LLM Agents
作者: Dongsen Zhang, Zekun Li, Xu Luo, Xuannan Liu, Peipei Li, Wenjun Xu
分类: cs.CR, cs.AI
发布日期: 2025-10-14
💡 一句话要点
提出MCP安全基准(MSB),系统评估LLM Agent中模型上下文协议(MCP)面临的安全风险。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 模型上下文协议 安全基准 攻击评估 工具使用
📋 核心要点
- 现有LLM Agent的工具使用依赖模型上下文协议(MCP),但MCP引入了新的安全漏洞,缺乏系统性的安全评估方法。
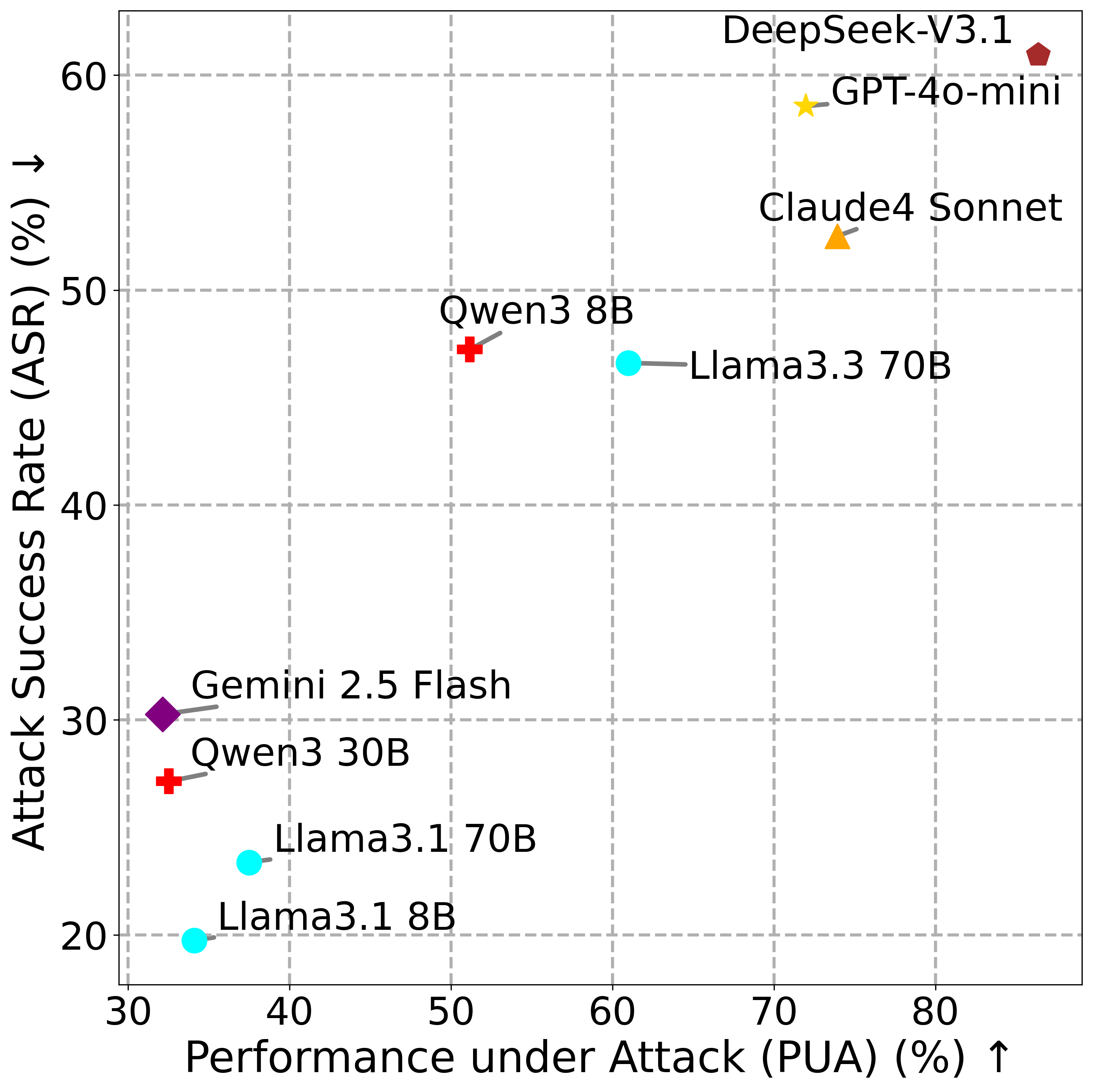
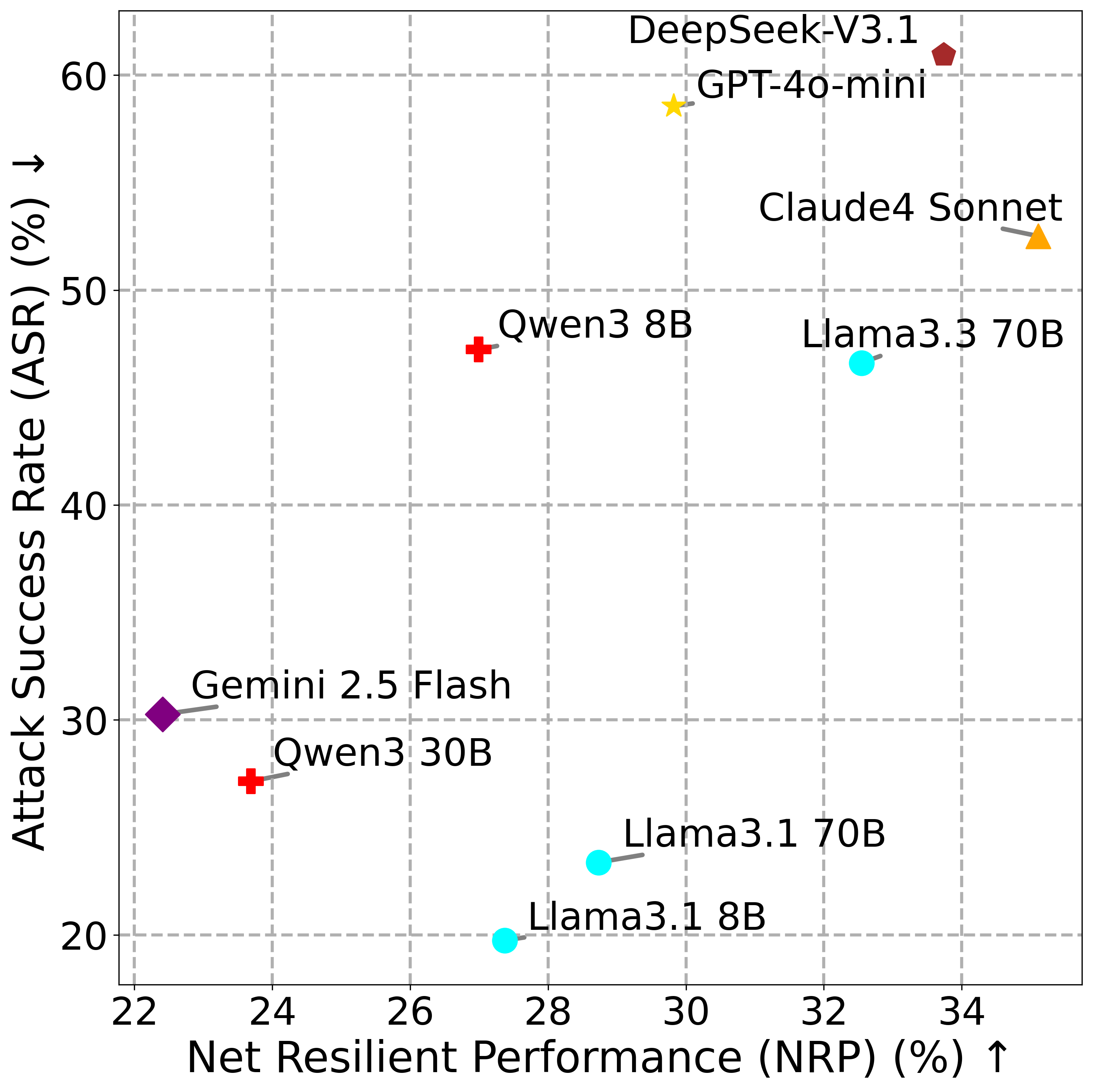
- MSB通过构建包含12种攻击类型的评估套件,并设计净弹性性能(NRP)指标,来全面评估LLM Agent在MCP环境下的安全性。
- 实验结果表明,现有LLM Agent在MCP环境下存在严重的安全风险,且性能更强的模型反而更容易受到攻击。
📝 摘要(中文)
模型上下文协议(MCP)标准化了大语言模型(LLM) Agent发现、描述和调用外部工具的方式。虽然MCP解锁了广泛的互操作性,但也通过将工具作为具有自然语言元数据和标准化I/O的一流、可组合对象,扩大了攻击面。我们提出了MSB(MCP安全基准),这是第一个端到端评估套件,系统地衡量LLM Agent在整个工具使用流程中抵抗MCP特定攻击的能力:任务规划、工具调用和响应处理。MSB贡献了:(1)一个包含12种攻击的分类,包括名称冲突、偏好操纵、嵌入在工具描述中的提示注入、超出范围的参数请求、用户模仿响应、虚假错误升级、工具转移、检索注入和混合攻击;(2)一个通过MCP运行真实工具(良性和恶意)来执行攻击的评估工具,而不是模拟;(3)一种量化安全性和性能之间权衡的鲁棒性指标:净弹性性能(NRP)。我们评估了10个领域和400多个工具中的9个流行的LLM Agent,产生了2000个攻击实例。结果表明了攻击对MCP每个阶段的有效性。由于其出色的工具调用和指令遵循能力,性能更强的模型更容易受到攻击。MSB为研究人员和从业人员研究、比较和加强MCP Agent提供了一个实用的基线。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在模型上下文协议(MCP)下,由于工具的引入而面临的安全风险评估问题。现有方法缺乏对MCP特定攻击的系统性评估,无法有效衡量Agent在真实环境下的安全性。现有的安全评估方法通常基于模拟环境,与真实场景存在差距,难以准确反映Agent的脆弱性。
核心思路:论文的核心思路是构建一个全面的MCP安全基准(MSB),通过模拟真实攻击场景,评估LLM Agent在任务规划、工具调用和响应处理等关键阶段的安全性。MSB包含一个攻击类型分类、一个基于真实工具的评估工具和一个鲁棒性指标,从而实现对Agent安全性的系统性、可量化评估。
技术框架:MSB的整体框架包含以下几个主要模块: 1. 攻击类型分类:定义了12种针对MCP的攻击类型,涵盖名称冲突、提示注入、参数篡改等多个方面。 2. 评估工具:该工具通过MCP运行真实工具(包括良性和恶意工具),模拟攻击场景,并记录Agent的行为。 3. 鲁棒性指标(NRP):NRP用于量化Agent在安全性和性能之间的权衡,评估其在遭受攻击时的表现。 4. 实验评估:使用MSB评估多个流行的LLM Agent,分析其在不同攻击下的表现,并识别潜在的安全漏洞。
关键创新:MSB的关键创新在于: 1. 真实环境模拟:使用真实工具而非模拟环境进行评估,更贴近实际应用场景。 2. 全面的攻击类型覆盖:定义了12种针对MCP的攻击类型,覆盖了Agent工具使用流程的各个阶段。 3. 量化的鲁棒性指标:NRP指标能够量化Agent在安全性和性能之间的权衡,为安全优化提供指导。
关键设计:MSB的关键设计包括: 1. 攻击实例生成:针对每种攻击类型,设计了多个攻击实例,以覆盖不同的攻击场景。 2. 工具选择:选择了400多个工具,涵盖10个领域,以保证评估的全面性。 3. NRP计算:NRP的计算考虑了Agent在正常情况下的性能和在遭受攻击时的性能,从而量化其鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有LLM Agent在MCP环境下普遍存在安全漏洞,攻击成功率较高。例如,某些Agent在遭受提示注入攻击时,容易被诱导执行恶意操作。此外,研究发现,性能更强的Agent由于其更强的工具调用和指令遵循能力,反而更容易受到攻击。MSB为评估和改进LLM Agent的安全性提供了一个有效的基准。
🎯 应用场景
该研究成果可应用于LLM Agent的安全评估和加固,帮助开发者识别和修复潜在的安全漏洞,提高Agent在实际应用中的安全性。此外,MSB可以作为LLM Agent安全研究的基准平台,促进相关领域的发展。该研究对于构建安全可靠的LLM Agent生态系统具有重要意义。
📄 摘要(原文)
The Model Context Protocol (MCP) standardizes how large language model (LLM) agents discover, describe, and call external tools. While MCP unlocks broad interoperability, it also enlarges the attack surface by making tools first-class, composable objects with natural-language metadata, and standardized I/O. We present MSB (MCP Security Benchmark), the first end-to-end evaluation suite that systematically measures how well LLM agents resist MCP-specific attacks throughout the full tool-use pipeline: task planning, tool invocation, and response handling. MSB contributes: (1) a taxonomy of 12 attacks including name-collision, preference manipulation, prompt injections embedded in tool descriptions, out-of-scope parameter requests, user-impersonating responses, false-error escalation, tool-transfer, retrieval injection, and mixed attacks; (2) an evaluation harness that executes attacks by running real tools (both benign and malicious) via MCP rather than simulation; and (3) a robustness metric that quantifies the trade-off between security and performance: Net Resilient Performance (NRP). We evaluate nine popular LLM agents across 10 domains and 400+ tools, producing 2,000 attack instances. Results reveal the effectiveness of attacks against each stage of MCP. Models with stronger performance are more vulnerable to attacks due to their outstanding tool calling and instruction following capabilities. MSB provides a practical baseline for researchers and practitioners to study, compare, and harden MCP agents.