Benefits and Limitations of Communication in Multi-Agent Reasoning
作者: Michael Rizvi-Martel, Satwik Bhattamishra, Neil Rathi, Guillaume Rabusseau, Michael Hahn
分类: cs.MA, cs.AI, cs.LG
发布日期: 2025-10-14
备注: 34 pages, 14 figures
💡 一句话要点
提出多智能体推理理论框架,分析通信对解决复杂任务的益处与局限
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 推理 通信 理论框架 大型语言模型
📋 核心要点
- 大型语言模型在复杂推理任务中面临上下文长度限制和性能下降的挑战。
- 论文提出一个理论框架,分析多智能体系统在解决复杂推理任务时的表达能力。
- 实验结果验证了理论框架预测的智能体数量、通信量和性能之间的权衡关系。
📝 摘要(中文)
思维链提示已使大型语言模型中的逐步推理普及,但随着问题复杂性和上下文长度的增加,模型性能仍然会下降。通过将具有长上下文的困难任务分解为更短、更易于管理的任务,最近的多智能体范式为解决这个问题提供了一个有希望的近期解决方案。然而,人们对这种系统的基本能力知之甚少。在这项工作中,我们提出了一个理论框架来分析多智能体系统的表达能力。我们将我们的框架应用于三个算法族:状态跟踪、回忆和k跳推理。我们推导出了关于以下方面的界限:(i)精确解决任务所需的智能体数量,(ii)智能体间通信的数量和结构,以及(iii)随着问题规模和上下文扩展,可实现的加速。我们的结果确定了通信在理论上被证明是有益的区域,划定了智能体数量和带宽之间的权衡,并揭示了当任何一种资源受到约束时的内在局限性。我们使用受控合成基准,通过预训练的LLM上的一组实验来补充我们的理论分析。经验结果证实了我们的理论预测的关键量之间的权衡。总的来说,我们的分析为设计可扩展的多智能体推理系统提供了原则性指导。
🔬 方法详解
问题定义:现有的大型语言模型在处理需要长上下文和复杂推理的任务时,性能会显著下降。传统的思维链方法虽然能够逐步推理,但仍然难以克服上下文长度的限制。多智能体系统通过将任务分解为更小的子任务,并分配给不同的智能体处理,有望缓解这个问题。然而,目前对多智能体系统的理论理解还不够深入,缺乏指导其设计的原则。
核心思路:论文的核心思路是建立一个理论框架,用于分析多智能体系统在解决复杂推理任务时的表达能力。该框架能够量化智能体数量、通信量以及问题规模之间的关系,从而揭示多智能体系统的优势和局限性。通过理论分析,可以指导多智能体系统的设计,使其能够更有效地解决复杂推理问题。
技术框架:该论文提出的理论框架主要包含以下几个部分:首先,定义了多智能体系统的基本组成,包括智能体、通信信道和任务。其次,针对三种典型的算法族(状态跟踪、回忆和k跳推理)进行了分析。对于每种算法族,论文推导出了解决任务所需的智能体数量、智能体间通信量以及可实现的加速的理论界限。这些理论界限可以帮助我们理解多智能体系统的性能瓶颈,并指导其优化。
关键创新:论文的关键创新在于提出了一个通用的理论框架,用于分析多智能体系统的表达能力。该框架不仅能够量化智能体数量和通信量之间的关系,还能够揭示多智能体系统在解决不同类型任务时的内在局限性。此外,论文还通过实验验证了理论分析的有效性,为多智能体系统的设计提供了有力的理论支撑。
关键设计:论文针对三种算法族进行了详细的理论分析。在状态跟踪任务中,论文分析了智能体需要维护的状态数量与问题规模之间的关系。在回忆任务中,论文分析了智能体需要存储的信息量与问题规模之间的关系。在k跳推理任务中,论文分析了智能体需要进行的推理步骤与问题规模之间的关系。此外,论文还考虑了通信带宽的限制,并分析了带宽限制对多智能体系统性能的影响。
🖼️ 关键图片
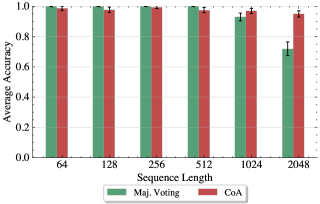
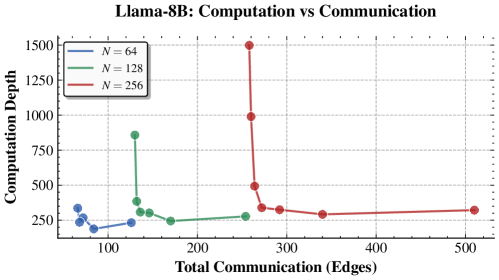
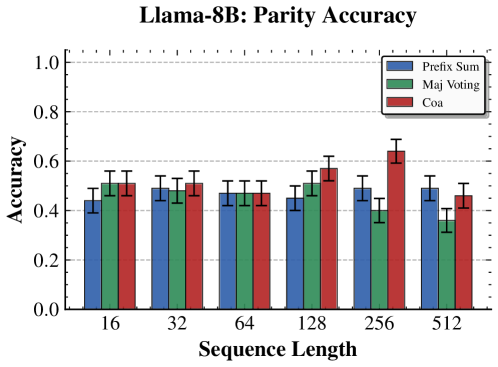
📊 实验亮点
论文通过在预训练LLM上进行受控合成基准测试,验证了理论分析的有效性。实验结果表明,智能体数量和通信量与任务性能之间存在明确的权衡关系,这与理论预测相符。例如,在k跳推理任务中,增加智能体数量可以显著提高推理的准确性,但同时也会增加通信开销。这些实验结果为多智能体系统的设计提供了重要的经验依据。
🎯 应用场景
该研究成果可应用于需要复杂推理和知识整合的领域,例如智能问答系统、知识图谱推理、多文档摘要等。通过合理设计多智能体系统,可以有效提升这些应用在处理大规模、复杂任务时的性能和效率,并为构建更强大的通用人工智能系统奠定基础。
📄 摘要(原文)
Chain-of-thought prompting has popularized step-by-step reasoning in large language models, yet model performance still degrades as problem complexity and context length grow. By decomposing difficult tasks with long contexts into shorter, manageable ones, recent multi-agent paradigms offer a promising near-term solution to this problem. However, the fundamental capacities of such systems are poorly understood. In this work, we propose a theoretical framework to analyze the expressivity of multi-agent systems. We apply our framework to three algorithmic families: state tracking, recall, and $k$-hop reasoning. We derive bounds on (i) the number of agents required to solve the task exactly, (ii) the quantity and structure of inter-agent communication, and (iii) the achievable speedups as problem size and context scale. Our results identify regimes where communication is provably beneficial, delineate tradeoffs between agent count and bandwidth, and expose intrinsic limitations when either resource is constrained. We complement our theoretical analysis with a set of experiments on pretrained LLMs using controlled synthetic benchmarks. Empirical outcomes confirm the tradeoffs between key quantities predicted by our theory. Collectively, our analysis offers principled guidance for designing scalable multi-agent reasoning systems.