DeepPlanner: Scaling Planning Capability for Deep Research Agents via Advantage Shaping
作者: Wei Fan, Wenlin Yao, Zheng Li, Feng Yao, Xin Liu, Liang Qiu, Qingyu Yin, Yangqiu Song, Bing Yin
分类: cs.AI, cs.CL
发布日期: 2025-10-14
备注: Under Review
💡 一句话要点
DeepPlanner:通过优势塑造提升深度研究Agent的规划能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 深度研究Agent 规划能力 优势塑造 长程规划 高熵Token 端到端学习
📋 核心要点
- 现有方法在优化深度研究Agent的规划能力方面存在不足,要么依赖隐式规划,要么缺乏对显式规划器的系统优化。
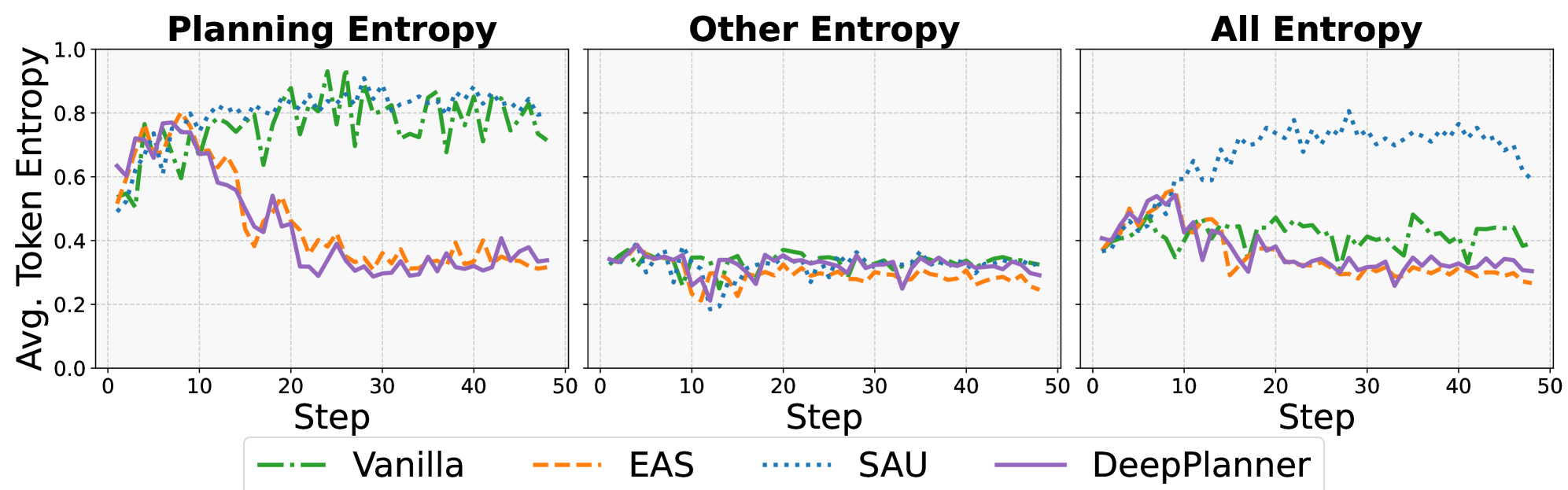
- DeepPlanner通过塑造token级别和样本级别的优势函数,有针对性地优化规划过程中的高熵token和规划密集型rollout。
- 实验结果表明,DeepPlanner在多个深度研究基准上显著提升了规划质量,并在更低的训练成本下达到了SOTA水平。
📝 摘要(中文)
本文提出DeepPlanner,一个端到端的强化学习框架,旨在有效提升深度研究Agent的规划能力。现有方法要么依赖于推理阶段的隐式规划,要么引入显式规划器但未系统地优化规划阶段。通过观察发现,在原始强化学习下,规划token比其他动作token表现出更高的熵,揭示了未充分优化的不确定决策点。DeepPlanner通过基于熵的项来塑造token级别的优势函数,从而为高熵token分配更大的更新,并选择性地提升规划密集型rollout的样本级别优势。在七个深度研究基准上的大量实验表明,DeepPlanner提高了规划质量,并在显著降低的训练预算下实现了最先进的结果。
🔬 方法详解
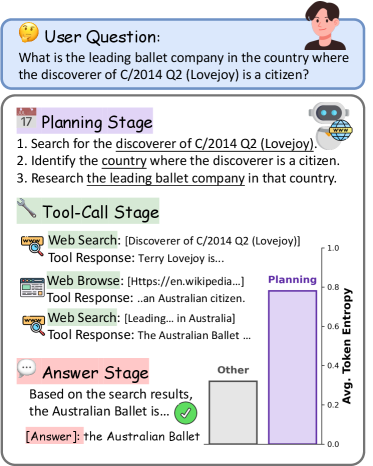
问题定义:论文旨在解决深度研究Agent在复杂任务中进行长程规划时,规划能力不足的问题。现有方法,如仅依赖LLM的隐式规划或直接引入显式规划器,都未能有效优化规划过程,导致规划token的不确定性较高,规划效果不佳。
核心思路:论文的核心思路是通过强化学习来显式地优化规划过程。具体而言,通过塑造优势函数,使得模型能够更加关注那些不确定性高(高熵)的规划token,并对规划密集型的rollout给予更高的权重,从而提升规划的质量和效率。
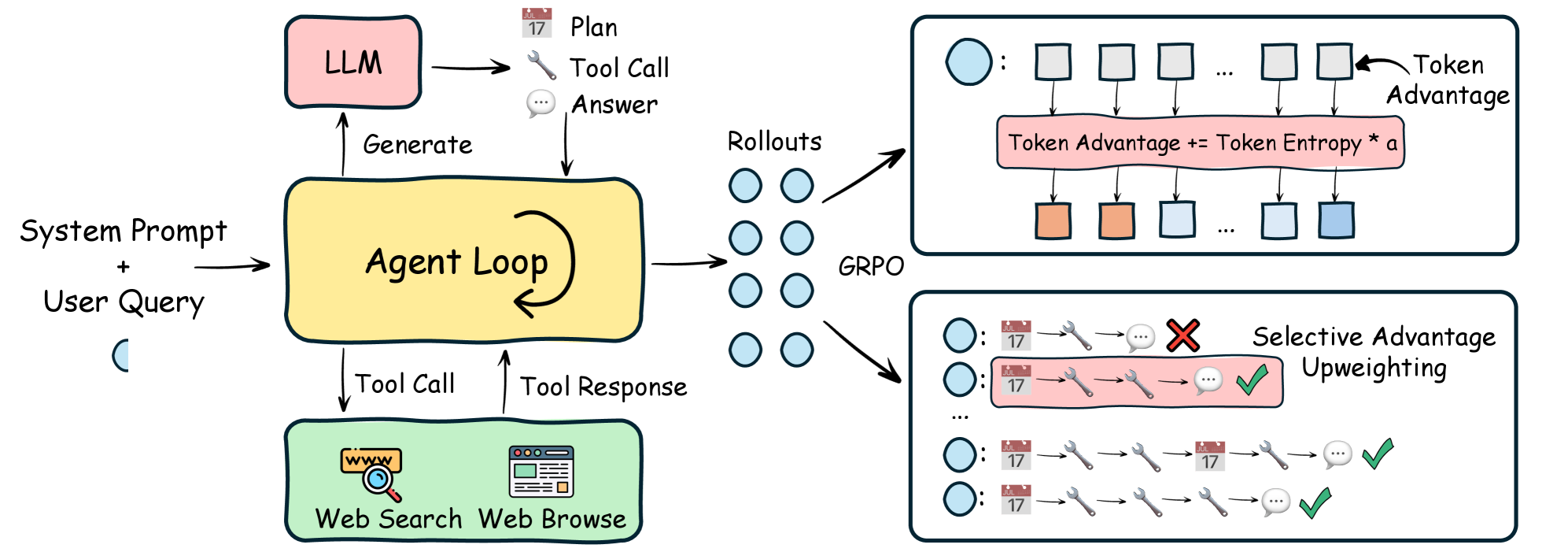
技术框架:DeepPlanner是一个端到端的强化学习框架,主要包含以下几个模块:1) LLM作为Agent,负责生成推理和动作;2) 强化学习模块,用于优化LLM的策略;3) 优势塑造模块,用于计算token级别和样本级别的优势函数,并根据熵值和规划密集度进行调整。整个流程是:Agent与环境交互生成rollout,然后利用优势塑造模块计算优势函数,最后利用强化学习算法更新Agent的策略。
关键创新:论文的关键创新在于优势塑造方法,它能够有针对性地优化规划过程。具体来说,通过引入基于熵的token级别优势塑造,使得模型能够更加关注那些不确定性高的规划token,从而提升规划的质量。同时,通过选择性地提升规划密集型rollout的样本级别优势,使得模型能够更加关注那些需要复杂规划的场景。
关键设计:在token级别的优势塑造中,论文引入了一个基于熵的权重,用于调整不同token的优势函数。具体来说,对于熵值较高的token,给予更高的权重,使得模型能够更加关注这些token。在样本级别的优势塑造中,论文根据rollout中规划token的比例来调整样本的权重,对于规划token比例较高的rollout,给予更高的权重。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DeepPlanner在七个深度研究基准上都取得了显著的提升,在训练预算大幅降低的情况下,达到了state-of-the-art的性能。例如,在某些基准上,DeepPlanner的性能超过了现有方法,同时训练成本降低了50%以上。这些结果表明,DeepPlanner能够有效地提升深度研究Agent的规划能力。
🎯 应用场景
DeepPlanner具有广泛的应用前景,可应用于科学研究、自动化决策、智能助手等领域。例如,可以用于自动化化学实验设计、智能投资组合管理、以及复杂问题求解等任务。该研究有助于提升AI在复杂任务中的规划和决策能力,推动人工智能的进一步发展。
📄 摘要(原文)
Large language models (LLMs) augmented with multi-step reasoning and action generation abilities have shown promise in leveraging external tools to tackle complex tasks that require long-horizon planning. However, existing approaches either rely on implicit planning in the reasoning stage or introduce explicit planners without systematically addressing how to optimize the planning stage. As evidence, we observe that under vanilla reinforcement learning (RL), planning tokens exhibit significantly higher entropy than other action tokens, revealing uncertain decision points that remain under-optimized. To address this, we propose DeepPlanner, an end-to-end RL framework that effectively enhances the planning capabilities of deep research agents. Our approach shapes token-level advantage with an entropy-based term to allocate larger updates to high entropy tokens, and selectively upweights sample-level advantages for planning-intensive rollouts. Extensive experiments across seven deep research benchmarks demonstrate that DeepPlanner improves planning quality and achieves state-of-the-art results under a substantially lower training budget.