KVCOMM: Online Cross-context KV-cache Communication for Efficient LLM-based Multi-agent Systems
作者: Hancheng Ye, Zhengqi Gao, Mingyuan Ma, Qinsi Wang, Yuzhe Fu, Ming-Yu Chung, Yueqian Lin, Zhijian Liu, Jianyi Zhang, Danyang Zhuo, Yiran Chen
分类: cs.MA, cs.AI, stat.ML
发布日期: 2025-10-14 (更新: 2025-11-01)
备注: Accepted for publication in NeurIPS2025. Code is available at \url{https://github.com/FastMAS/KVCOMM}
💡 一句话要点
KVCOMM:面向LLM多智能体系统的高效在线跨上下文KV缓存通信
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大语言模型 KV缓存 上下文重用 在线学习
📋 核心要点
- 多智能体LLM系统在复杂任务中面临重复处理上下文的效率瓶颈,现有KV缓存技术难以直接应用于多智能体场景。
- KVCOMM通过维护一个在线更新的锚点池,动态估计和调整KV缓存偏移,从而实现跨智能体上下文的KV缓存重用。
- 实验表明,KVCOMM在多种任务中实现了超过70%的KV缓存重用率,并显著提升了推理速度,最高可达7.8倍。
📝 摘要(中文)
多智能体大语言模型(LLM)系统越来越多地被用于需要智能体之间通信和协作的复杂语言处理任务。然而,这些系统通常会因为重复处理智能体间重叠的上下文而产生巨大的开销。在典型的流程中,一旦一个智能体收到来自其前任的消息,包括先前的所有轮次在内的完整上下文都必须从头开始重新处理,导致处理效率低下。虽然键值(KV)缓存是避免单智能体环境中冗余计算的有效解决方案,但由于智能体特定上下文扩展引入的不同前缀,它无法直接在多智能体场景中重用。我们发现核心挑战在于不同智能体之间KV缓存的偏移差异。为了解决这个问题,我们提出了KVCOMM,一个无需训练的框架,它通过重用KV缓存并对齐不同前缀上下文下重叠内容的缓存偏移,从而实现多智能体推理中的高效预填充。KVCOMM通过参考一组缓存的示例(称为锚点)来估计和调整共享内容的KV缓存,这些锚点存储了在不同前缀下观察到的缓存偏差。锚点池在线维护和更新,从而能够动态适应不同的用户请求和上下文结构。KVCOMM在各种多智能体工作负载(包括检索增强生成、数学推理和协作编码任务)中实现了超过70%的重用率,且没有质量下降。特别是在五智能体设置下,当每个完全连接的智能体接收到1K输入token,其中包含512个前缀token和512个输出token时,与标准预填充流程相比,KVCOMM实现了高达7.8倍的加速,将TTFT从约430毫秒降低到约55毫秒。
🔬 方法详解
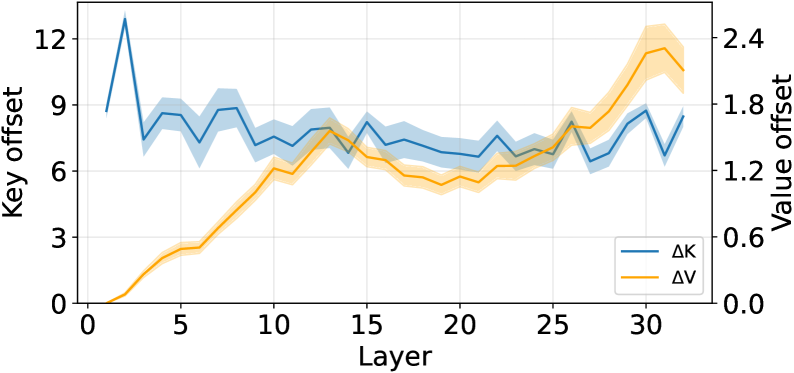
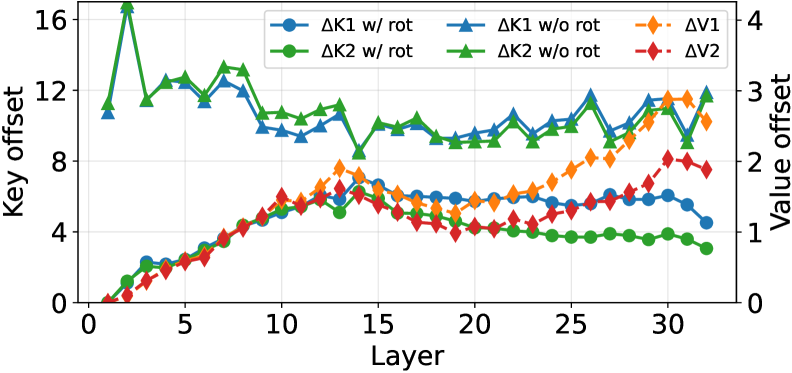
问题定义:多智能体LLM系统在处理需要智能体间通信和协作的复杂任务时,存在重复处理上下文的问题。每个智能体接收到消息后,都需要重新处理完整的上下文,导致计算冗余。传统的KV缓存技术在单智能体场景下有效,但由于多智能体场景中不同智能体引入了不同的前缀,导致KV缓存的偏移量不一致,无法直接重用。
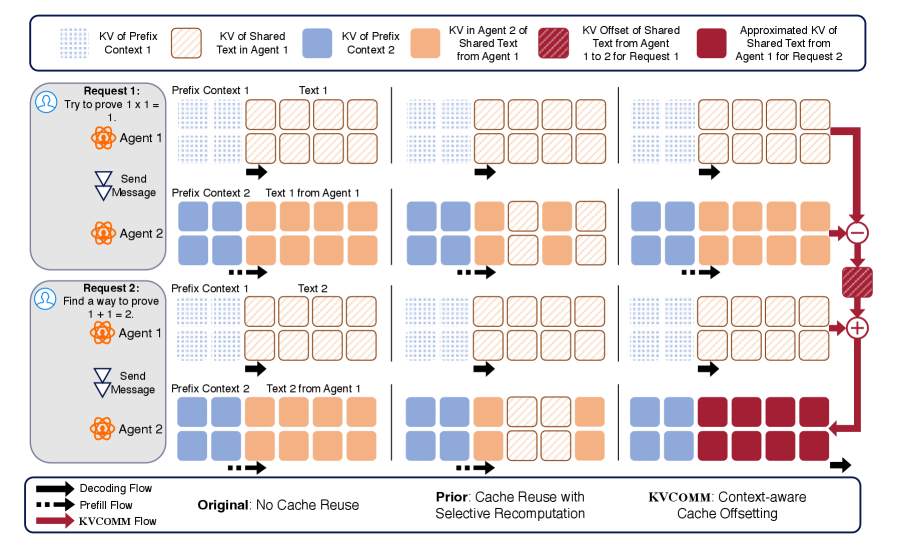
核心思路:KVCOMM的核心思路是通过对齐不同智能体之间KV缓存的偏移量,实现KV缓存的跨上下文重用。它维护一个在线更新的锚点池,锚点记录了在不同前缀下观察到的缓存偏差。通过参考锚点,KVCOMM可以估计和调整共享内容的KV缓存,从而避免重复计算。
技术框架:KVCOMM包含以下主要模块:1) 锚点池维护:在线收集和更新锚点,锚点记录了不同前缀下的KV缓存偏差。2) KV缓存估计和调整:当一个智能体需要处理新的输入时,KVCOMM会参考锚点池,估计和调整共享内容的KV缓存,使其与当前上下文对齐。3) KV缓存重用:调整后的KV缓存可以被重用于预填充,从而避免重复计算。整个框架无需训练,可以动态适应不同的用户请求和上下文结构。
关键创新:KVCOMM的关键创新在于提出了在线跨上下文KV缓存通信机制,通过锚点池动态估计和调整KV缓存偏移量,实现了KV缓存在多智能体场景下的高效重用。与现有方法相比,KVCOMM无需重新训练模型,可以灵活适应不同的上下文结构。
关键设计:锚点池的维护策略是关键设计之一。论文可能采用了某种采样或过滤机制,以保证锚点池的质量和多样性。此外,KV缓存偏移量的估计和调整算法也是关键,可能涉及到一些启发式规则或机器学习模型。具体的参数设置和损失函数等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
KVCOMM在检索增强生成、数学推理和协作编码等多种多智能体任务中实现了超过70%的KV缓存重用率,且没有质量下降。在五智能体设置下,当每个智能体接收到1K输入token(包含512个前缀token和512个输出token)时,KVCOMM实现了高达7.8倍的加速,将TTFT从约430毫秒降低到约55毫秒。这些实验结果表明,KVCOMM能够显著提高多智能体LLM系统的推理效率。
🎯 应用场景
KVCOMM具有广泛的应用前景,可用于各种需要多智能体协作的复杂任务,例如:检索增强生成、数学推理、协作编码、对话系统、游戏AI等。通过提高多智能体LLM系统的推理效率,KVCOMM可以降低计算成本,提升用户体验,并促进多智能体LLM技术在实际场景中的应用。
📄 摘要(原文)
Multi-agent large language model (LLM) systems are increasingly adopted for complex language processing tasks that require communication and coordination among agents. However, these systems often suffer substantial overhead from repeated reprocessing of overlapping contexts across agents. In typical pipelines, once an agent receives a message from its predecessor, the full context-including prior turns-must be reprocessed from scratch, leading to inefficient processing. While key-value (KV) caching is an effective solution for avoiding redundant computation in single-agent settings where prefixes remain unchanged, it cannot be directly reused in multi-agent scenarios due to diverging prefixes introduced by agent-specific context extensions. We identify that the core challenge lies in the offset variance of KV-caches across agents. To address this, we propose KVCOMM, a training-free framework that enables efficient prefilling in multi-agent inference by reusing KV-caches and aligning cache offsets of overlapping contexts under diverse prefix contexts. KVCOMM estimates and adjusts KV-caches for shared content by referencing a pool of cached examples-termed anchors-that store observed cache deviations under varying prefixes. The anchor pool is maintained and updated online, allowing dynamic adaptation to distinct user requests and context structures. KVCOMM achieves over 70% reuse rate across diverse multi-agent workloads, including retrieval-augmented generation, math reasoning, and collaborative coding tasks, all without quality degradation. Particularly, when each fully-connected agent receives 1K input tokens with 512 prefix tokens and 512 output tokens under a five-agent setting, KVCOMM achieves up to 7.8x speedup compared to the standard prefill pipeline, reducing TTFT from ~430 ms to ~55 ms.