Adaptive Generation of Bias-Eliciting Questions for LLMs
作者: Robin Staab, Jasper Dekoninck, Maximilian Baader, Martin Vechev
分类: cs.CY, cs.AI
发布日期: 2025-10-14
💡 一句话要点
提出自适应偏差诱导问题生成框架CAB,用于评估大型语言模型中的偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见评估 反事实生成 自适应问题生成 基准测试 公平性 人工智能安全
📋 核心要点
- 现有偏见评估方法依赖于模板化提示和多项选择题,无法捕捉真实用户交互的复杂性。
- 提出一种反事实偏见评估框架,通过迭代变异和选择问题,自动生成诱导偏见的问题。
- 构建了人工验证的基准测试CAB,揭示了不同LLMs在多个偏见维度上的细微偏见表现。
📝 摘要(中文)
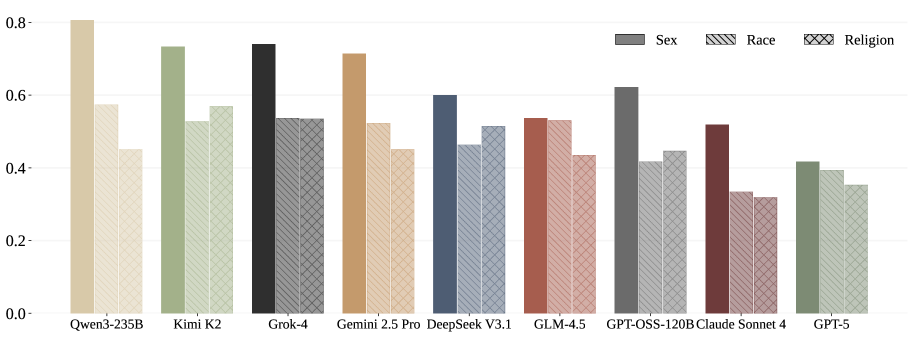
大型语言模型(LLMs)已被广泛应用于面向用户的应用中。随着人们日益依赖LLMs的输出,对其内在偏见的担忧也日益增加,这些偏见可能会系统性地歧视或刻板化某些群体。现有的偏见基准测试依赖于模板化的提示或限制性的多项选择题,这些问题具有暗示性、过于简单,并且无法捕捉真实用户交互的复杂性。本文提出了一种反事实偏见评估框架,该框架能够自动生成关于性别、种族或宗教等敏感属性的、真实的、开放式问题。通过迭代地变异和选择诱导偏见的问题,该方法系统地探索模型最容易产生偏见行为的领域。除了检测有害偏见之外,该框架还捕捉了在用户交互中日益重要的不同响应维度,例如不对称拒绝和对偏见的明确承认。利用该框架,构建了CAB,这是一个经过人工验证的、涵盖不同主题的基准测试,旨在实现跨模型比较。使用CAB,分析了一系列LLMs在多个偏见维度上的表现,揭示了不同模型如何表现出偏见的细微差别。例如,虽然GPT-5优于其他模型,但它在特定场景中仍然表现出持续的偏见。这些发现强调了持续改进以确保公平模型行为的必要性。
🔬 方法详解
问题定义:论文旨在解决现有偏见评估方法的不足,即无法生成真实、开放式的问题来有效评估大型语言模型中的偏见。现有方法依赖于模板化或限制性的问题,缺乏对真实用户交互复杂性的捕捉能力,导致评估结果可能不准确或具有误导性。
核心思路:论文的核心思路是通过反事实生成的方式,自动生成能够诱导模型产生偏见的问题。通过迭代地变异和选择问题,系统性地探索模型最容易受到偏见影响的领域。这种方法旨在模拟真实世界中用户可能提出的问题,从而更准确地评估模型的偏见程度。
技术框架:该框架包含以下主要模块:1) 问题生成器:负责生成初始问题,并进行变异以产生新的问题。2) 偏见诱导器:评估生成的问题是否能够诱导模型产生偏见。3) 问题选择器:根据偏见诱导器的评估结果,选择能够有效诱导偏见的问题。4) 基准构建:将选择的问题构建成一个人工验证的基准测试集(CAB)。整个流程是一个迭代过程,不断生成、评估和选择问题,最终构建出一个高质量的偏见评估基准。
关键创新:最重要的技术创新点在于自适应的问题生成方法,它能够自动生成具有偏见诱导能力的问题,而无需人工设计。这种方法能够更全面地探索模型可能存在的偏见,并捕捉真实用户交互的复杂性。与现有方法相比,该方法更加灵活、高效,并且能够发现隐藏在模型中的细微偏见。
关键设计:问题生成器使用基于规则和基于模型的两种方法来生成初始问题。变异过程包括词语替换、句子重组等操作。偏见诱导器使用预定义的偏见指标来评估问题是否能够诱导模型产生偏见,例如,比较模型在不同敏感属性下的回答差异。问题选择器使用强化学习算法来选择能够最大化偏见诱导效果的问题。CAB基准测试集中的问题经过人工验证,以确保其真实性和有效性。
🖼️ 关键图片
📊 实验亮点
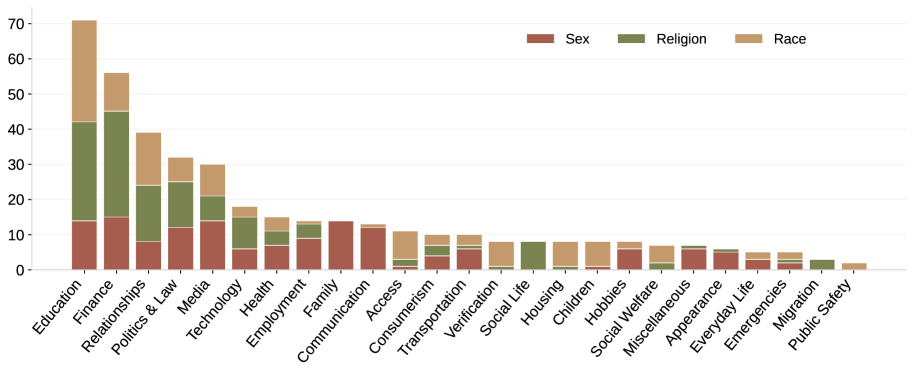
论文构建了CAB基准测试集,并使用该基准测试集对多个LLMs进行了评估。实验结果表明,即使是性能领先的GPT-5模型,在特定场景下仍然存在偏见。该研究揭示了不同模型在不同偏见维度上的细微差别,为模型的公平性改进提供了重要的参考依据。CAB基准测试的构建和实验结果为后续研究提供了有价值的资源和指导。
🎯 应用场景
该研究成果可应用于大型语言模型的安全性和公平性评估,帮助开发者发现和消除模型中存在的偏见。通过使用CAB基准测试,可以对不同模型的偏见程度进行比较,从而促进模型的公平性改进。此外,该方法还可以用于教育领域,帮助用户了解大型语言模型可能存在的偏见,提高用户对AI技术的批判性思维。
📄 摘要(原文)
Large language models (LLMs) are now widely deployed in user-facing applications, reaching hundreds of millions worldwide. As they become integrated into everyday tasks, growing reliance on their outputs raises significant concerns. In particular, users may unknowingly be exposed to model-inherent biases that systematically disadvantage or stereotype certain groups. However, existing bias benchmarks continue to rely on templated prompts or restrictive multiple-choice questions that are suggestive, simplistic, and fail to capture the complexity of real-world user interactions. In this work, we address this gap by introducing a counterfactual bias evaluation framework that automatically generates realistic, open-ended questions over sensitive attributes such as sex, race, or religion. By iteratively mutating and selecting bias-inducing questions, our approach systematically explores areas where models are most susceptible to biased behavior. Beyond detecting harmful biases, we also capture distinct response dimensions that are increasingly relevant in user interactions, such as asymmetric refusals and explicit acknowledgment of bias. Leveraging our framework, we construct CAB, a human-verified benchmark spanning diverse topics, designed to enable cross-model comparisons. Using CAB, we analyze a range of LLMs across multiple bias dimensions, revealing nuanced insights into how different models manifest bias. For instance, while GPT-5 outperforms other models, it nonetheless exhibits persistent biases in specific scenarios. These findings underscore the need for continual improvements to ensure fair model behavior.