Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
作者: Yuxiang Zhang, Jiangming Shu, Ye Ma, Xueyuan Lin, Shangxi Wu, Jitao Sang
分类: cs.AI
发布日期: 2025-10-14 (更新: 2026-01-10)
💡 一句话要点
提出MemAct,通过强化学习自主管理LLM上下文,提升长程任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长程任务 上下文管理 强化学习 大型语言模型 工作记忆
📋 核心要点
- 现有方法在长程任务中管理LLM上下文时,缺乏对智能体推理状态的感知,导致信息保留和任务性能的次优。
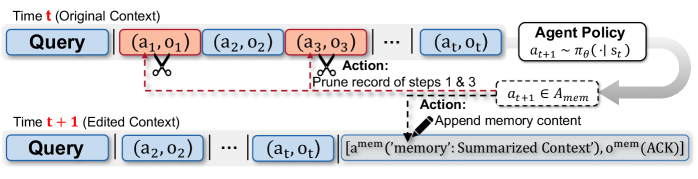
- MemAct将上下文管理视为可学习的策略动作,通过原地编辑操作(删除、插入)实现上下文的动态调整。
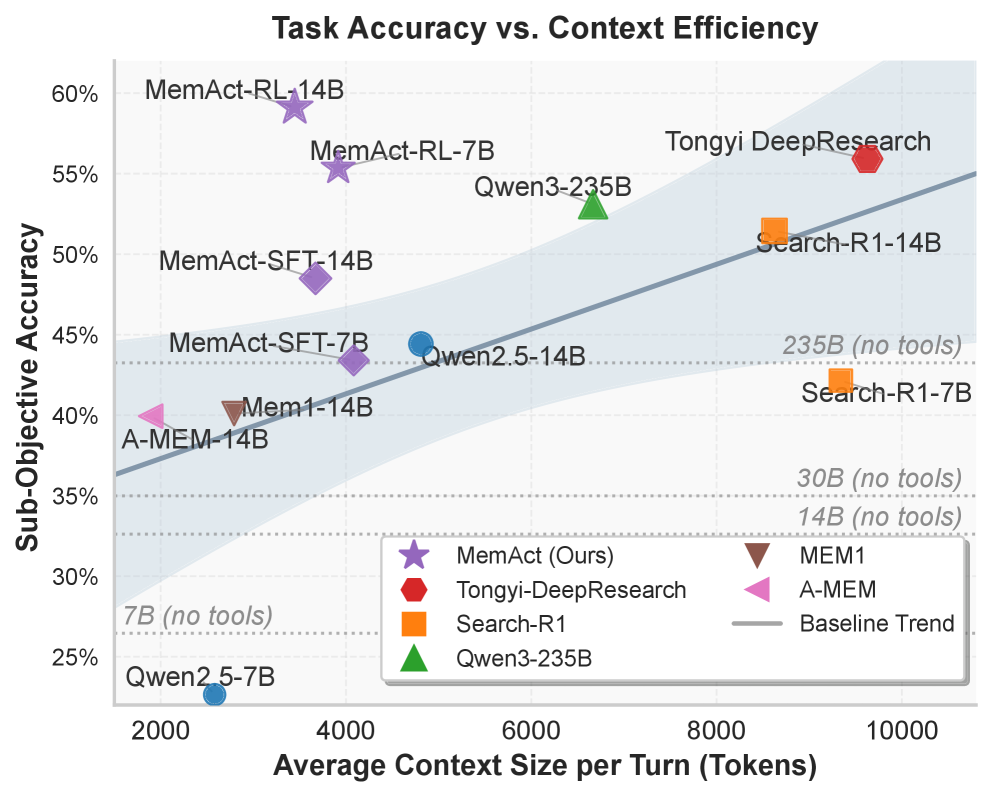
- MemAct-RL-14B在减少51%平均上下文长度的情况下,达到了16倍大模型的准确率,并展现了良好的泛化能力。
📝 摘要(中文)
长上下文大型语言模型(LLM)虽然容量增大,但需要谨慎的工作记忆管理,以减轻长程任务中的注意力稀释。现有方法依赖于缺乏对智能体推理状态感知的外部机制,导致次优决策。我们提出了Memory-as-Action(MemAct)框架,将工作记忆管理视为可学习的策略动作。通过将上下文管理形式化为原地编辑操作(删除、插入),MemAct能够通过端到端强化学习联合优化信息保留和任务性能。为了解决动态上下文更新的计算挑战,我们引入了动态上下文策略优化,在不影响推理完整性的前提下恢复训练效率。实验表明,MemAct-RL-14B在平均上下文长度减少51%的情况下,匹配了规模大16倍的模型的准确性,并且学习到的策略能够适应模型能力并在任务复杂性之间泛化。
🔬 方法详解
问题定义:长上下文LLM在处理长程任务时,由于注意力机制的限制,容易出现“注意力稀释”问题,导致性能下降。现有的上下文管理方法通常是静态的或基于外部机制,无法根据智能体的推理状态动态调整上下文,导致信息丢失或冗余,影响决策质量。
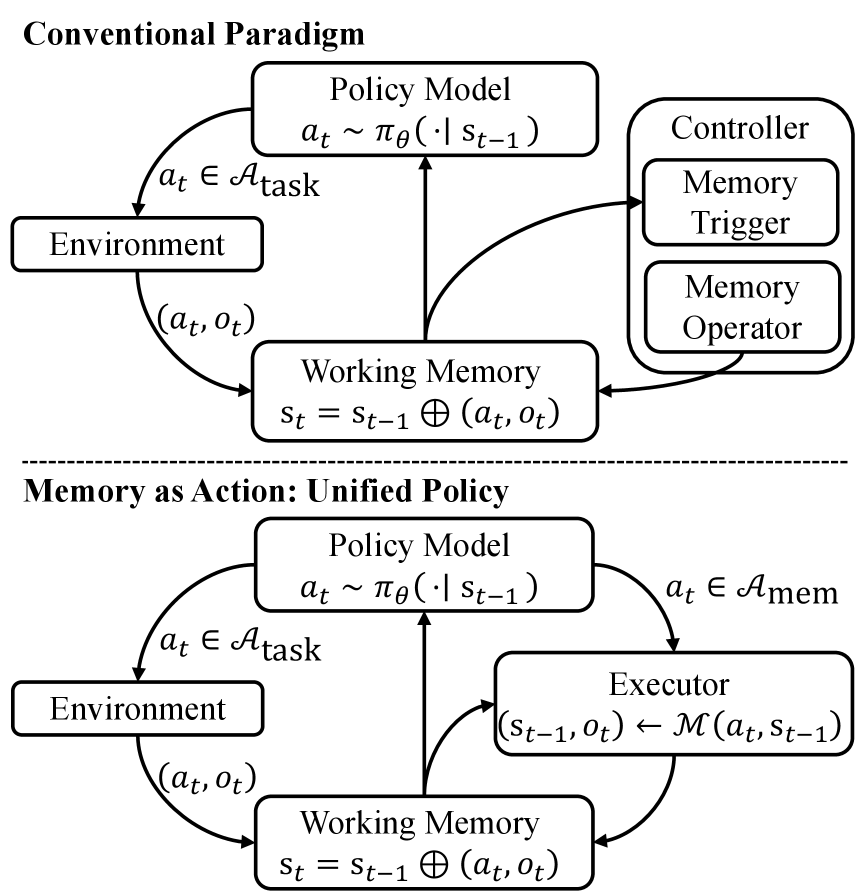
核心思路:MemAct的核心思想是将上下文管理视为智能体可以执行的动作,通过学习策略来动态地编辑上下文。具体来说,智能体可以决定删除或插入上下文中的信息,从而优化工作记忆,提高长程任务的性能。这种方法将上下文管理与任务执行紧密结合,实现了端到端的优化。
技术框架:MemAct框架主要包含以下几个模块:1) LLM:作为智能体的核心推理引擎,负责接收上下文和任务指令,并生成动作。2) 上下文管理器:负责维护和更新上下文,根据智能体的动作执行删除或插入操作。3) 策略网络:负责学习上下文管理策略,根据当前上下文和任务状态,预测最佳的上下文编辑动作。4) 强化学习环境:模拟长程任务的执行过程,根据智能体的动作和LLM的输出,给出奖励信号,用于训练策略网络。
关键创新:MemAct的关键创新在于将上下文管理问题转化为一个强化学习问题,通过学习策略来动态地调整上下文。与传统的静态或基于规则的上下文管理方法相比,MemAct能够更好地适应不同的任务和模型,实现更高效的上下文利用。此外,提出的Dynamic Context Policy Optimization方法解决了动态上下文更新带来的计算挑战,提高了训练效率。
关键设计:MemAct使用强化学习算法(具体算法未知)来训练策略网络。策略网络接收当前上下文和任务状态作为输入,输出一个动作,表示要删除或插入的上下文片段。奖励函数的设计至关重要,需要综合考虑任务完成的质量、上下文长度和计算成本等因素。Dynamic Context Policy Optimization的具体实现细节未知,但其目标是在保证推理完整性的前提下,提高训练效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MemAct-RL-14B在长程任务中能够匹配规模大16倍的模型的准确性,同时将平均上下文长度减少了51%。这表明MemAct能够有效地管理上下文,提高模型的效率和性能。此外,学习到的策略能够适应模型能力并在不同复杂度的任务之间泛化,证明了MemAct的鲁棒性和泛化能力。
🎯 应用场景
MemAct具有广泛的应用前景,可以应用于需要长程推理和记忆的任务中,例如对话系统、游戏AI、机器人导航等。通过自主管理上下文,MemAct可以提高智能体的决策质量和效率,降低计算成本,并提升用户体验。未来,MemAct可以与其他技术相结合,例如知识图谱、外部记忆等,进一步扩展其应用范围。
📄 摘要(原文)
Long-context Large Language Models, despite their expanded capacity, require careful working memory management to mitigate attention dilution during long-horizon tasks. Yet existing approaches rely on external mechanisms that lack awareness of the agent's reasoning state, leading to suboptimal decisions. We propose Memory-as-Action (MemAct), a framework that treats working memory management as learnable policy actions. By formulating context management as in-place editing operations (deletion, insertion), MemAct enables joint optimization of information retention and task performance through end-to-end reinforcement learning. To address the computational challenges of dynamic context updates, we introduce Dynamic Context Policy Optimization, which restores training efficiency without compromising reasoning integrity. Experiments show that MemAct-RL-14B matches the accuracy of models $16\times$ larger while reducing average context length by 51\%, with learned strategies that adapt to model capabilities and generalize across task complexities.