GOAT: A Training Framework for Goal-Oriented Agent with Tools
作者: Hyunji Min, Sangwon Jung, Junyoung Sung, Dosung Lee, Leekyeung Han, Paul Hongsuck Seo
分类: cs.AI
发布日期: 2025-10-14
备注: 32 pages, 21 figures
💡 一句话要点
GOAT:一种用于训练具备工具使用能力的面向目标Agent的框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 面向目标Agent 合成数据 自动训练
📋 核心要点
- 现有LLM Agent在处理需要复杂API调用规划和执行的面向目标查询时存在局限性,且缺乏有效的训练数据。
- GOAT框架通过自动构建合成数据集,使LLM Agent能够在无人为标注的环境中学习面向目标的API执行任务。
- 实验表明,经过GOAT训练的Agent在多个基准测试中取得了领先性能,并成功应用于新的GOATBench基准。
📝 摘要(中文)
大型语言模型(LLMs)的能力已从传统的文本生成扩展到作为交互式Agent,能够根据用户意图使用外部工具。然而,当前的LLM Agent在处理面向目标的查询时能力有限,这类查询需要将高级目标分解为多个相互依赖的API调用,并进行正确的规划和执行。由于缺乏训练数据,目前的方法主要依赖于零样本评估。虽然像GPT-4这样的专有闭源模型表现出强大的推理能力,但较小的开源模型在执行复杂的工具使用方面表现不佳。因此,我们提出了一种新的训练框架GOAT,它能够在无人为标注的环境中微调LLM Agent。GOAT直接从给定的API文档中自动构建面向目标的API执行任务的合成数据集,使模型能够推理相互依赖的调用并生成连贯的响应。通过大量的实验,我们表明,经过GOAT训练的Agent在多个现有的面向目标的基准测试中实现了最先进的性能。此外,我们还引入了GOATBench,这是一个新的面向目标的API执行基准,并证明了使用GOAT训练的Agent在该基准测试中也表现出色。这些结果表明,GOAT是构建能够进行复杂推理和工具使用的强大开源LLM Agent的有效途径。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在面向目标的复杂任务中,由于缺乏训练数据和难以进行有效推理规划而导致的工具使用能力不足的问题。现有方法主要依赖零样本学习,效果有限,尤其是在开源模型上表现不佳。
核心思路:核心思路是通过自动生成合成数据集来训练LLM Agent,使其能够学习如何将高层目标分解为一系列相互依赖的API调用,并进行合理的规划和执行。这种方法避免了人工标注的成本,并能够有效地利用API文档中的信息。
技术框架:GOAT框架主要包含以下几个阶段:1) API文档解析:解析给定的API文档,提取API的描述、参数和返回值等信息。2) 任务生成:根据API文档,自动生成面向目标的API执行任务,包括任务描述、API调用序列和预期结果。3) 数据集构建:将生成的任务组织成训练数据集,用于微调LLM Agent。4) 模型训练:使用生成的数据集对LLM Agent进行微调,使其具备推理和规划API调用的能力。
关键创新:GOAT的关键创新在于其自动生成合成数据集的能力,这使得在无人为标注的情况下训练LLM Agent成为可能。与现有方法相比,GOAT能够更有效地利用API文档中的信息,并生成更具挑战性和多样性的训练数据。
关键设计:GOAT在任务生成过程中,设计了多种策略来保证生成任务的多样性和合理性,例如随机选择API、随机组合API参数、引入约束条件等。此外,GOAT还设计了一种特殊的损失函数,用于鼓励模型生成正确的API调用序列和连贯的响应。具体的参数设置和网络结构细节在论文中可能有所描述,但此处未知。
🖼️ 关键图片
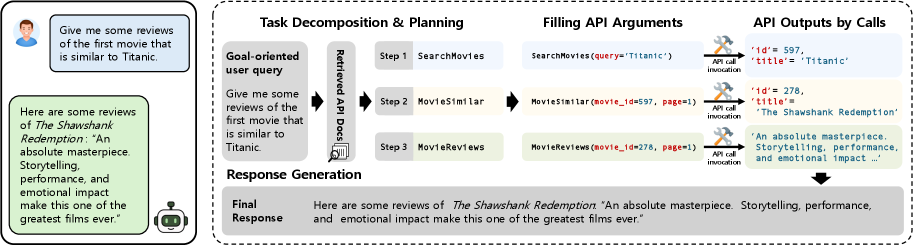

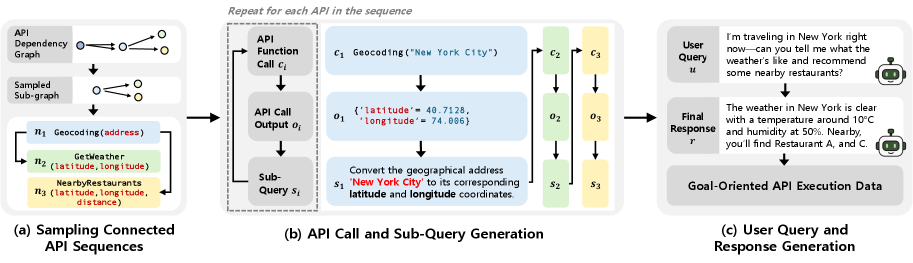
📊 实验亮点
GOAT训练的Agent在多个面向目标的基准测试中取得了state-of-the-art的性能。此外,在新的GOATBench基准测试中也表现出色,证明了GOAT框架的有效性和泛化能力。具体的性能数据和提升幅度在论文中有所描述,但此处未知。
🎯 应用场景
GOAT框架可应用于各种需要LLM Agent进行复杂工具使用的场景,例如智能助手、自动化流程、智能家居等。通过GOAT训练的Agent可以更好地理解用户意图,并利用外部工具完成各种任务,从而提高工作效率和用户体验。该研究有助于推动开源LLM Agent的发展,使其能够更好地服务于社会。
📄 摘要(原文)
Large language models (LLMs) have recently been extended beyond traditional text generation to serve as interactive agents capable of using external tools based on user intent. However, current LLM agents still show limited ability to handle goal-oriented queries, which require decomposing a high-level objective into multiple interdependent API calls with correct planning and execution. Current approaches mainly rely on zero-shot evaluation due to the absence of training data. While proprietary closed-source models such as GPT-4 demonstrate strong reasoning abilities, smaller open-source models struggle to perform complex tool use effectively. Thus, we propose a novel training framework GOAT, which enables fine-tuning of LLM agents in a human annotation-free setting. GOAT automatically constructs synthetic datasets of goal-oriented API execution tasks directly from given API documents, equipping models with the ability to reason over interdependent calls and generate coherent responses. Through extensive experiments, we show that GOAT-trained agents achieve state-of-the-art performance across multiple existing goal-oriented benchmarks. In addition, we introduce GOATBench, a new goal-oriented API execution benchmark, and demonstrate that agents trained with GOAT also excel in this setting. These results highlight GOAT as a practical path toward building robust open-source LLM agents capable of complex reasoning and tool use.