Evolution of meta's llama models and parameter-efficient fine-tuning of large language models: a survey
作者: Abdulhady Abas Abdullah, Arkaitz Zubiaga, Seyedali Mirjalili, Amir H. Gandomi, Fatemeh Daneshfar, Mohammadsadra Amini, Alan Salam Mohammed, Hadi Veisi
分类: cs.AI, cs.CL
发布日期: 2025-10-14
💡 一句话要点
综述Meta LLaMA模型演进及参数高效微调方法,为LLM研究者提供一站式资源
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 参数高效微调 LLaMA模型 低秩适应 指令调优
📋 核心要点
- 大型语言模型微调面临计算资源和存储的挑战,传统微调方法成本高昂且效率低下。
- 论文综述了参数高效微调(PEFT)方法,通过仅更新少量参数来适应LLaMA模型,降低了计算成本。
- 分析了LoRA、LLaMA-Adapter等PEFT方法在LLaMA上的应用,并讨论了其在法律、医疗等领域的实际应用。
📝 摘要(中文)
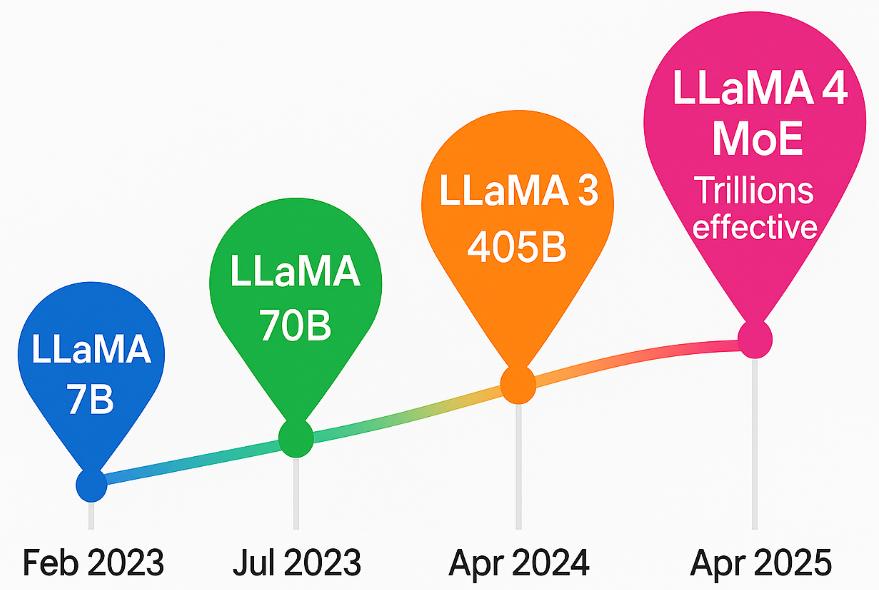
本综述探讨了Meta AI的LLaMA(大型语言模型Meta AI)系列的快速演进——从LLaMA 1到LLaMA 4,以及为这些模型开发的专用参数高效微调(PEFT)方法。首先,我们描述了LLaMA系列的基础模型(7B-65B到288B参数),它们的架构(包括原生多模态和混合专家变体),以及关键性能特征。然后,我们描述并讨论了PEFT的概念,它通过仅更新一小部分参数来调整大型预训练模型,并回顾了应用于LLaMA的五种PEFT方法:LoRA(低秩适应)、LLaMA-Adapter V1和V2、LLaMA-Excitor和QLoRA(量化LoRA)。我们讨论了每种方法的机制、参数节省以及应用于LLaMA的示例(例如,指令调优、多模态任务)。我们对模型和适配器架构、参数计数和基准测试结果进行了结构化讨论和分析(包括微调的LLaMA模型优于更大的基线的示例)。最后,我们研究了基于LLaMA的模型和PEFT已成功应用的实际用例(例如,法律和医疗领域),并讨论了当前面临的挑战和未来的研究方向(例如,扩展到更大的上下文和提高鲁棒性)。本综述为对LLaMA模型和高效微调策略感兴趣的机器学习研究人员和从业者提供了一站式资源。
🔬 方法详解
问题定义:大型语言模型(LLM)的微调需要大量的计算资源和存储空间,传统的全参数微调方法成本高昂,效率低下。此外,针对特定任务微调后的模型泛化能力可能较差,难以适应新的领域或任务。因此,如何在有限的资源下高效地微调LLM,并保持其泛化能力,是一个重要的研究问题。
核心思路:论文的核心思路是综述参数高效微调(PEFT)方法,这些方法通过仅更新LLM的一小部分参数来实现模型适应,从而显著降低计算成本和存储需求。PEFT方法通常采用添加适配器模块或修改现有参数的方式,以最小的参数量实现与全参数微调相近甚至更好的性能。这样设计的目的是在保证模型性能的同时,提高微调效率和泛化能力。
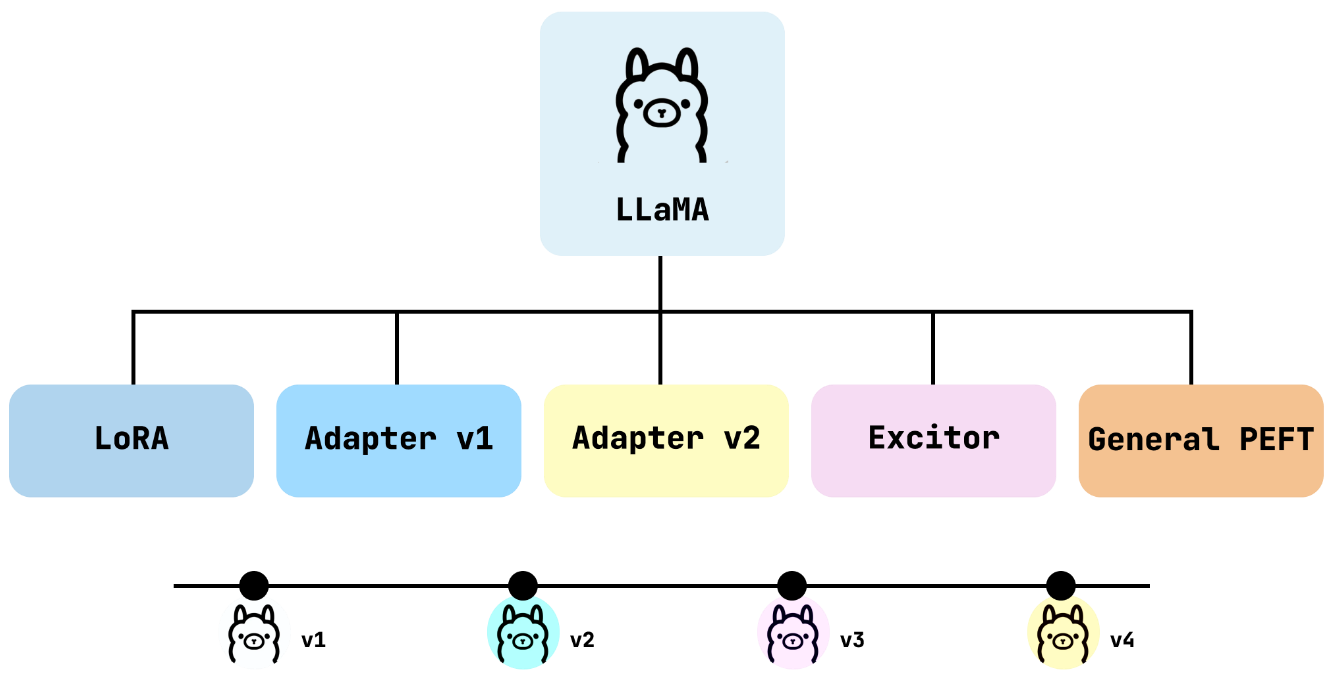
技术框架:该综述首先介绍了Meta AI的LLaMA系列模型,包括其架构、参数规模和性能特点。然后,详细介绍了五种应用于LLaMA的PEFT方法:LoRA、LLaMA-Adapter V1和V2、LLaMA-Excitor和QLoRA。对于每种方法,综述都描述了其核心机制、参数节省情况以及在LLaMA上的应用示例,例如指令调优和多模态任务。最后,综述还讨论了LLaMA模型和PEFT在实际用例中的应用,并展望了未来的研究方向。
关键创新:该综述的关键创新在于系统性地整理和分析了应用于LLaMA模型的各种PEFT方法。与以往的研究相比,该综述不仅涵盖了多种PEFT方法,还深入探讨了它们在LLaMA上的具体应用和性能表现。此外,该综述还对模型和适配器架构、参数计数和基准测试结果进行了结构化分析,为研究人员和从业者提供了全面的参考。
关键设计:不同的PEFT方法在关键设计上有所不同。例如,LoRA通过引入低秩矩阵来近似参数更新,从而减少了需要训练的参数量。LLaMA-Adapter则通过添加额外的适配器模块来实现模型适应。QLoRA则通过量化技术进一步降低了参数量。这些方法在参数设置、损失函数和网络结构等方面都有各自的特点,需要根据具体的任务和资源情况进行选择。
🖼️ 关键图片
📊 实验亮点
该综述总结了多种PEFT方法在LLaMA模型上的应用,并分析了它们的性能表现。例如,一些研究表明,经过PEFT微调的LLaMA模型在某些任务上甚至可以超越更大的基线模型。此外,该综述还提供了各种PEFT方法的参数节省情况,为研究人员选择合适的微调策略提供了参考。
🎯 应用场景
该研究成果可广泛应用于自然语言处理领域,尤其是在资源受限的情况下对大型语言模型进行微调。例如,在法律、医疗等专业领域,可以利用PEFT方法对LLaMA模型进行高效微调,以满足特定任务的需求。此外,该研究还有助于推动LLM在移动设备和边缘计算等场景的应用。
📄 摘要(原文)
This review surveys the rapid evolution of Meta AI's LLaMA (Large Language Model Meta AI) series - from LLaMA 1 through LLaMA 4 and the specialized parameter-efficient fine-tuning (PEFT) methods developed for these models. We first describe the LLaMA family of foundation models (7B-65B to 288B parameters), their architectures (including native multimodal and Mixtureof-Experts variants), and key performance characteristics. We then describe and discuss the concept of PEFT, which adapts large pre-trained models by updating only a small subset of parameters, and review five PEFT methods that have been applied to LLaMA: LoRA (Low-Rank Adaptation), LLaMA-Adapter V1 and V2, LLaMA-Excitor, and QLoRA (Quantized LoRA). We discuss each method's mechanism, parameter savings, and example application to LLaMA (e.g., instruction tuning, multimodal tasks). We provide structured discussion and analysis of model and adapter architectures, parameter counts, and benchmark results (including examples where fine-tuned LLaMA models outperform larger baselines). Finally, we examine real-world use cases where LLaMA-based models and PEFT have been successfully applied (e.g., legal and medical domains), and we discuss ongoing challenges and future research directions (such as scaling to even larger contexts and improving robustness). This survey paper provides a one-stop resource for ML researchers and practitioners interested in LLaMA models and efficient fine-tuning strategies.