MatSciBench: Benchmarking the Reasoning Ability of Large Language Models in Materials Science
作者: Junkai Zhang, Jingru Gan, Xiaoxuan Wang, Zian Jia, Changquan Gu, Jianpeng Chen, Yanqiao Zhu, Mingyu Derek Ma, Dawei Zhou, Ling Li, Wei Wang
分类: cs.AI
发布日期: 2025-10-14
💡 一句话要点
MatSciBench:构建材料科学领域LLM推理能力评估基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 材料科学 大型语言模型 基准测试 科学推理 多模态学习
📋 核心要点
- 现有LLM在材料科学领域的推理能力评估不足,缺乏专门的、细粒度的评估基准。
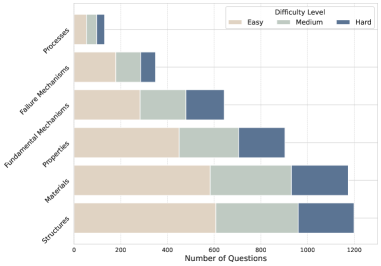
- 构建包含1340个材料科学问题的MatSciBench基准,涵盖6个主要领域和31个子领域,并进行难度分级。
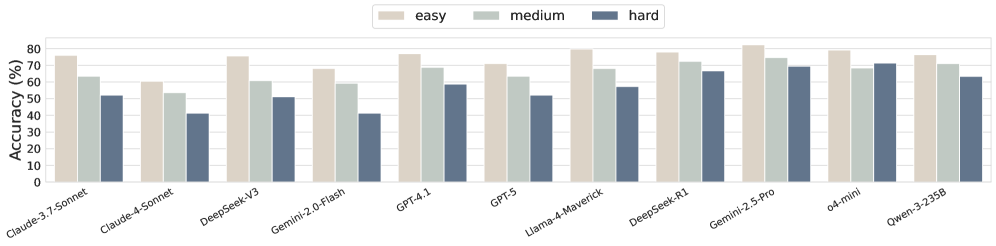
- 评估结果表明,即使是先进的LLM模型在MatSciBench上的表现仍有提升空间,并分析了不同推理策略的优劣。
📝 摘要(中文)
大型语言模型(LLM)在科学推理方面表现出卓越的能力,但其在材料科学领域的推理能力仍未得到充分探索。为了填补这一空白,我们推出了MatSciBench,这是一个全面的大学水平基准,包含1340个问题,涵盖了材料科学的基本子学科。MatSciBench具有结构化和细粒度的分类法,将材料科学问题分为6个主要领域和31个子领域,并根据解决每个问题所需的推理长度,包括一个三层难度分类。MatSciBench提供了详细的参考解决方案,可以进行精确的错误分析,并通过许多问题中的视觉上下文结合了多模态推理。对领先模型的评估表明,即使是性能最高的模型Gemini-2.5-Pro,在大学水平的材料科学问题上的准确率也低于80%,突显了MatSciBench的复杂性。我们对不同推理策略(基本思维链、工具增强和自我纠正)的系统分析表明,没有一种方法能在所有情况下始终表现出色。我们进一步分析了不同难度级别的性能,检查了效率和准确性之间的权衡,强调了多模态推理任务中固有的挑战,分析了LLM和推理方法的失败模式,并评估了检索增强生成的影响。因此,MatSciBench建立了一个全面而可靠的基准,用于评估和推动LLM在材料科学领域科学推理能力的改进。
🔬 方法详解
问题定义:论文旨在解决材料科学领域缺乏专门的、细粒度的LLM推理能力评估基准的问题。现有方法无法充分评估LLM在材料科学特定知识和推理方面的能力,阻碍了该领域LLM应用的进一步发展。
核心思路:论文的核心思路是构建一个全面的、具有挑战性的材料科学基准数据集,该数据集不仅覆盖了材料科学的各个子领域,还考虑了问题的难度和推理复杂度,从而能够更准确地评估LLM在该领域的推理能力。
技术框架:MatSciBench基准数据集的构建流程主要包括以下几个阶段:1) 问题收集与筛选:收集涵盖材料科学各个子领域的题目,并进行筛选,确保题目的质量和难度适中。2) 题目分类与标注:将题目按照领域和难度进行分类,并进行详细的标注,包括参考答案、解题思路等。3) 多模态信息融合:部分题目包含视觉信息,需要LLM具备多模态推理能力。4) 评估指标设计:设计合理的评估指标,用于衡量LLM的推理准确率和效率。
关键创新:MatSciBench的关键创新在于其全面性和细粒度。它不仅覆盖了材料科学的各个子领域,还对问题进行了难度分级,并提供了详细的参考答案和解题思路,方便研究人员进行错误分析和模型改进。此外,MatSciBench还包含了多模态推理题目,更贴近实际应用场景。
关键设计:MatSciBench的题目难度分为三个等级,分别对应不同的推理长度。数据集包含了单选题、多选题和开放式问题等多种题型。在评估过程中,论文采用了准确率作为主要的评估指标,并分析了不同推理策略(如思维链、工具增强和自我纠正)对模型性能的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是目前最先进的LLM模型Gemini-2.5-Pro在MatSciBench上的准确率也低于80%,表明该基准具有挑战性。研究还发现,不同的推理策略在不同类型的题目上表现各异,没有一种方法能够始终取得最佳效果。检索增强生成对模型性能有一定提升,但仍存在改进空间。
🎯 应用场景
MatSciBench可用于评估和提升LLM在材料科学领域的推理能力,促进LLM在材料发现、材料设计、材料性能预测等方面的应用。该基准还可以帮助研究人员更好地理解LLM的优势和局限性,为开发更强大的材料科学AI模型提供指导。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable abilities in scientific reasoning, yet their reasoning capabilities in materials science remain underexplored. To fill this gap, we introduce MatSciBench, a comprehensive college-level benchmark comprising 1,340 problems that span the essential subdisciplines of materials science. MatSciBench features a structured and fine-grained taxonomy that categorizes materials science questions into 6 primary fields and 31 sub-fields, and includes a three-tier difficulty classification based on the reasoning length required to solve each question. MatSciBench provides detailed reference solutions enabling precise error analysis and incorporates multimodal reasoning through visual contexts in numerous questions. Evaluations of leading models reveal that even the highest-performing model, Gemini-2.5-Pro, achieves under 80% accuracy on college-level materials science questions, highlighting the complexity of MatSciBench. Our systematic analysis of different reasoning strategie--basic chain-of-thought, tool augmentation, and self-correction--demonstrates that no single method consistently excels across all scenarios. We further analyze performance by difficulty level, examine trade-offs between efficiency and accuracy, highlight the challenges inherent in multimodal reasoning tasks, analyze failure modes across LLMs and reasoning methods, and evaluate the influence of retrieval-augmented generation. MatSciBench thus establishes a comprehensive and solid benchmark for assessing and driving improvements in the scientific reasoning capabilities of LLMs within the materials science domain.