Precise Attribute Intensity Control in Large Language Models via Targeted Representation Editing
作者: Rongzhi Zhang, Liqin Ye, Yuzhao Heng, Xiang Chen, Tong Yu, Lingkai Kong, Sudheer Chava, Chao Zhang
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-10-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于表征编辑的精确属性强度控制方法,实现大语言模型生成内容属性的精细化调控。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 属性强度控制 表征编辑 梯度干预 价值函数
📋 核心要点
- 现有大语言模型对齐方法难以实现精确的属性强度控制,无法满足用户对生成内容属性的精细化需求。
- 论文提出将属性强度控制视为目标到达问题,通过价值函数预测和梯度干预实现精确控制。
- 实验表明,该方法能够高精度地引导文本生成到用户指定的属性强度,并在下游任务中提升效率。
📝 摘要(中文)
精确的属性强度控制对于生成能够适应不同用户期望的大语言模型(LLM)输出至关重要。然而,现有的LLM对齐方法通常只提供方向性或开放式的指导,无法可靠地实现精确的属性强度。本文通过三个关键设计来解决这一限制:(1)将精确的属性强度控制重新定义为一个目标到达问题,而不是简单的最大化;(2)通过时序差分学习训练一个轻量级的价值函数,从部分生成内容中预测最终的属性强度得分,从而引导LLM输出;(3)采用基于梯度的干预措施来调整隐藏层表征,从而精确地引导模型达到特定的属性强度目标。该方法实现了对属性强度的精细、连续控制,超越了简单的方向性对齐。在LLaMA-3.2-3b和Phi-4-mini上的实验证实了该方法能够以高精度引导文本生成到用户指定的属性强度。最后,本文展示了在三个下游任务中的效率提升:偏好数据合成、帕累托前沿逼近与优化,以及对齐行为的蒸馏,以实现无干预的推理。
🔬 方法详解
问题定义:现有的大语言模型对齐方法,例如强化学习或监督微调,通常只能提供方向性的指导,而无法精确控制生成文本的属性强度。用户希望生成的文本在特定属性(例如,幽默程度、正式程度)上达到特定的强度水平,而现有方法难以满足这种精细化控制的需求。现有方法的痛点在于缺乏对生成过程的精确引导和量化评估。
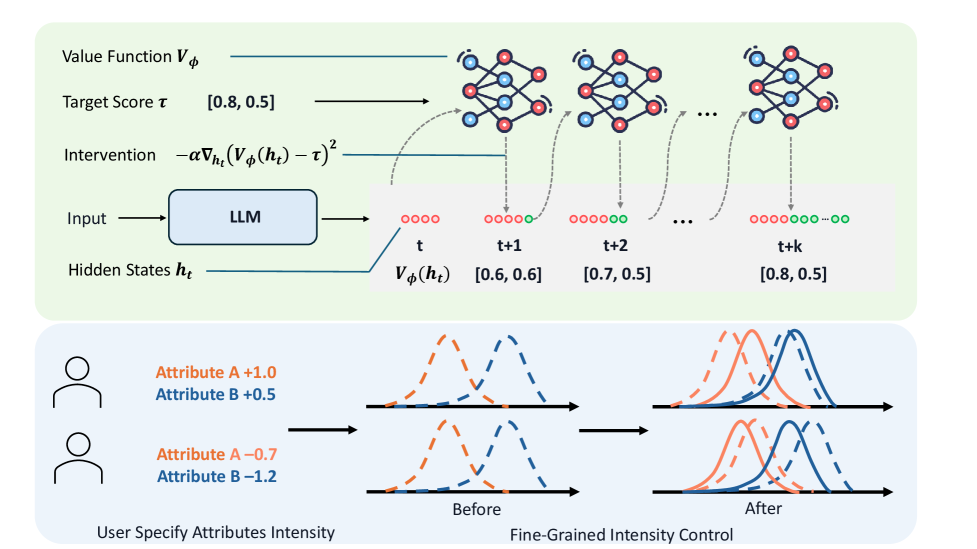
核心思路:论文的核心思路是将精确属性强度控制问题转化为一个目标到达问题。通过训练一个价值函数来预测生成文本的最终属性强度,并利用该价值函数指导生成过程,使得模型能够逐步逼近用户设定的目标属性强度。这种方法避免了简单地最大化或最小化属性强度,而是关注如何精确地达到目标值。
技术框架:整体框架包含三个主要模块:1) 价值函数训练:使用时序差分学习训练一个轻量级的价值函数,该函数能够从部分生成的文本中预测最终的属性强度得分。2) 梯度干预:在生成过程中,利用价值函数提供的梯度信息,对大语言模型的隐藏层表征进行干预,引导模型朝着目标属性强度方向生成文本。3) 文本生成:通过迭代地进行梯度干预和文本生成,最终生成满足用户指定属性强度的文本。
关键创新:最重要的技术创新点在于将精确属性强度控制问题转化为目标到达问题,并利用价值函数和梯度干预来实现对生成过程的精确引导。与现有方法相比,该方法能够实现对属性强度的连续控制,并能够精确地达到用户设定的目标值。此外,使用轻量级的价值函数降低了计算成本。
关键设计:价值函数采用一个小型神经网络,输入为部分生成的文本,输出为预测的属性强度得分。损失函数采用时序差分误差,鼓励价值函数预测的得分与实际得分之间的差距最小化。梯度干预通过计算价值函数对隐藏层表征的梯度,并沿着梯度方向调整表征来实现。具体干预强度通过超参数控制,需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
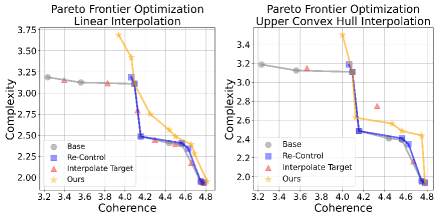
实验结果表明,该方法能够以高精度引导文本生成到用户指定的属性强度。在LLaMA-3.2-3b和Phi-4-mini模型上进行了实验,验证了该方法的有效性。此外,该方法在偏好数据合成、帕累托前沿逼近与优化以及对齐行为蒸馏等下游任务中均取得了显著的效率提升,表明该方法具有良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于人机对话、内容生成、文本风格迁移等领域。例如,可以根据用户的情感需求生成具有特定情感强度的回复,或者根据用户的写作风格生成具有特定风格特征的文章。该技术还有助于合成高质量的偏好数据,用于训练更符合人类价值观的大语言模型,并可用于优化模型的帕累托前沿,实现多目标优化。
📄 摘要(原文)
Precise attribute intensity control--generating Large Language Model (LLM) outputs with specific, user-defined attribute intensities--is crucial for AI systems adaptable to diverse user expectations. Current LLM alignment methods, however, typically provide only directional or open-ended guidance, failing to reliably achieve exact attribute intensities. We address this limitation with three key designs: (1) reformulating precise attribute intensity control as a target-reaching problem, rather than simple maximization; (2) training a lightweight value function via temporal-difference learning to predict final attribute intensity scores from partial generations, thereby steering LLM outputs; and (3) employing gradient-based interventions on hidden representations to navigate the model precisely towards specific attribute intensity targets. Our method enables fine-grained, continuous control over attribute intensities, moving beyond simple directional alignment. Experiments on LLaMA-3.2-3b and Phi-4-mini confirm our method's ability to steer text generation to user-specified attribute intensities with high accuracy. Finally, we demonstrate efficiency enhancements across three downstream tasks: preference data synthesis, Pareto frontier approximation and optimization, and distillation of aligned behaviors for intervention-free inference. Our code is available on https://github.com/Pre-Control/pre-control