Gelina: Unified Speech and Gesture Synthesis via Interleaved Token Prediction
作者: Téo Guichoux, Théodor Lemerle, Shivam Mehta, Jonas Beskow, Gustav Eje Henter, Laure Soulier, Catherine Pelachaud, Nicolas Obin
分类: cs.SD, cs.AI, eess.AS
发布日期: 2025-10-13 (更新: 2025-11-27)
备注: 5 pages
💡 一句话要点
Gelina:提出一种基于交错Token预测的统一语音和手势合成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音合成 手势生成 多模态融合 自回归模型 人机交互
📋 核心要点
- 现有语音和手势生成方法通常是顺序合成,导致语音和手势的同步性和韵律对齐较弱。
- Gelina采用交错Token序列,在离散自回归骨干网络中联合建模语音和手势,实现统一合成。
- 实验结果表明,Gelina在语音质量上具有竞争力,并且在手势生成方面优于单模态基线。
📝 摘要(中文)
本文提出了一种名为Gelina的统一框架,用于从文本中联合合成语音和协同手势。该框架采用离散自回归骨干网络,通过交错的Token序列以及模态特定的解码器实现。Gelina支持多说话人和多风格的克隆,并能够从语音输入合成仅手势。主观和客观评估表明,与单模态基线相比,Gelina在语音质量方面具有竞争力,并在手势生成方面有所改进。
🔬 方法详解
问题定义:论文旨在解决语音和手势同步生成的问题。现有方法通常独立地生成语音和手势,导致两者之间缺乏自然流畅的同步和韵律对齐。这种分离的生成方式忽略了语音和手势之间紧密的耦合关系,限制了生成结果的真实感和表现力。
核心思路:Gelina的核心思路是将语音和手势视为一个统一的多模态序列,并使用交错的Token来表示它们。通过这种方式,模型可以同时学习语音和手势之间的依赖关系,从而生成更自然和同步的语音和手势。这种联合建模的方法能够更好地捕捉人类交流中语音和手势的内在联系。
技术框架:Gelina的整体架构包括以下几个主要模块:1) 文本编码器:将输入文本转换为Token序列。2) 交错Token生成器:将语音和手势的Token交错排列,形成一个统一的序列。3) 自回归骨干网络:使用Transformer等自回归模型学习交错Token序列的概率分布。4) 模态特定解码器:将自回归骨干网络的输出解码为语音和手势。整个流程实现了从文本到同步语音和手势的端到端生成。
关键创新:Gelina的关键创新在于使用交错Token序列来统一表示语音和手势。这种方法允许模型同时学习两种模态之间的依赖关系,从而生成更自然和同步的结果。与现有方法相比,Gelina避免了顺序生成带来的同步问题,并能够更好地捕捉人类交流中的多模态信息。此外,Gelina还支持多说话人和多风格的克隆,以及从语音输入合成仅手势,提供了更灵活的生成能力。
关键设计:Gelina使用离散自回归模型作为骨干网络,例如VQ-VAE或Gumbel-Softmax。模态特定解码器可以是基于Transformer的结构,用于将离散Token解码为连续的语音和手势信号。损失函数包括语音和手势的重建损失,以及用于鼓励同步的对齐损失。具体的参数设置和网络结构需要根据具体的数据集和任务进行调整。
🖼️ 关键图片
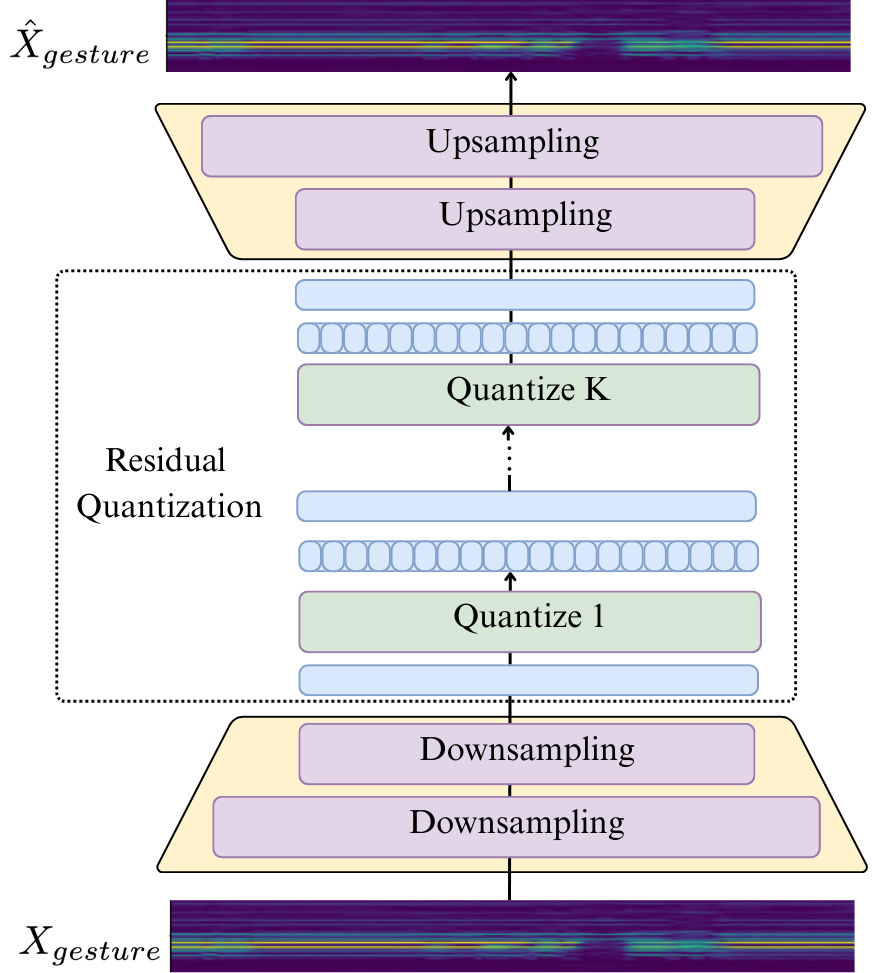
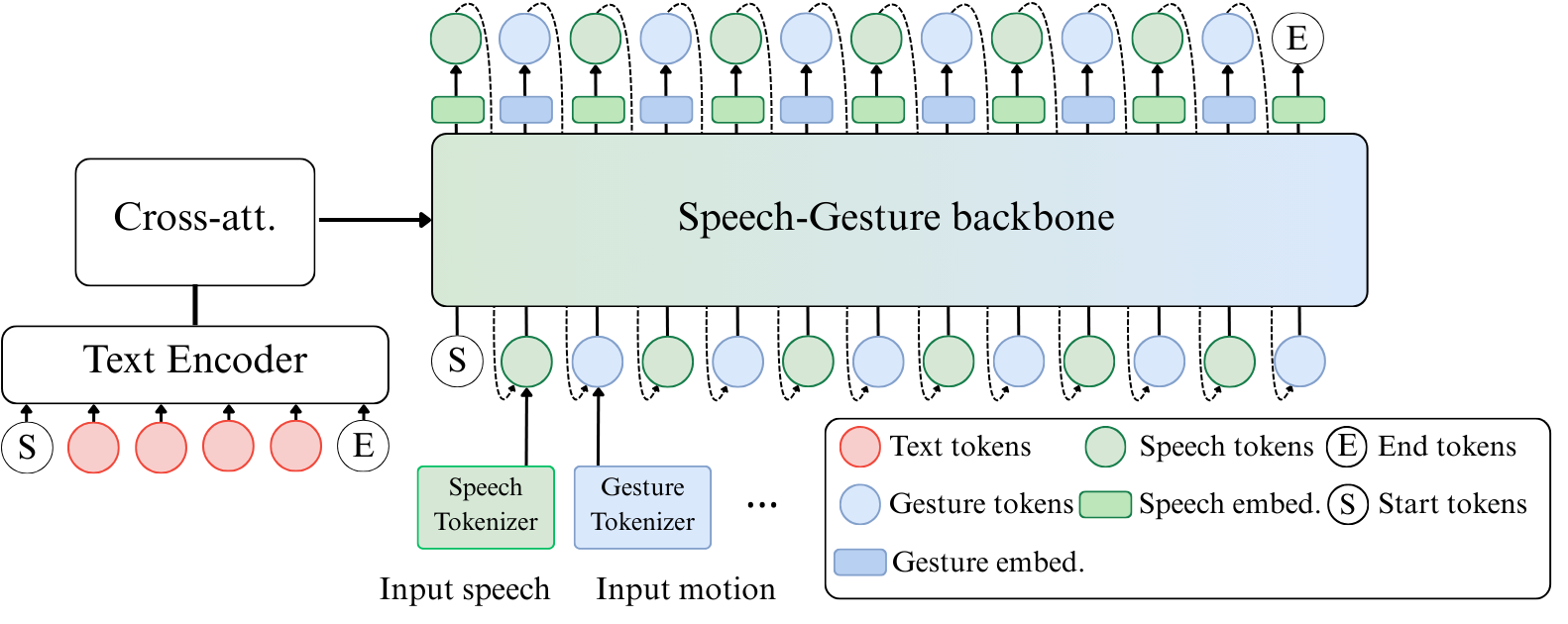

📊 实验亮点
实验结果表明,Gelina在语音质量方面与单模态基线具有竞争力,并且在手势生成方面取得了显著的改进。主观评估显示,Gelina生成的手势更自然、更符合语音内容。客观评估指标也表明,Gelina在手势的准确性和同步性方面优于现有方法。具体性能数据未知。
🎯 应用场景
Gelina具有广泛的应用前景,包括虚拟助手、游戏角色、在线教育、人机交互等领域。它可以用于创建更自然、更具表现力的虚拟人物,提升用户体验。此外,Gelina还可以用于研究人类交流中的语音和手势关系,为心理学、语言学等领域提供新的 insights。
📄 摘要(原文)
Human communication is multimodal, with speech and gestures tightly coupled, yet most computational methods for generating speech and gestures synthesize them sequentially, weakening synchrony and prosody alignment. We introduce Gelina, a unified framework that jointly synthesizes speech and co-speech gestures from text using interleaved token sequences in a discrete autoregressive backbone, with modality-specific decoders. Gelina supports multi-speaker and multi-style cloning and enables gesture-only synthesis from speech inputs. Subjective and objective evaluations demonstrate competitive speech quality and improved gesture generation over unimodal baselines.