CTIArena: Benchmarking LLM Knowledge and Reasoning Across Heterogeneous Cyber Threat Intelligence
作者: Yutong Cheng, Yang Liu, Changze Li, Dawn Song, Peng Gao
分类: cs.CR, cs.AI
发布日期: 2025-10-13
备注: Under peer-review
💡 一句话要点
CTIArena:构建知识增强型网络威胁情报LLM基准评测体系
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 网络威胁情报 大型语言模型 基准评测 知识增强 信息检索
📋 核心要点
- 现有CTI的LLM应用研究主要依赖闭卷设置,忽略了CTI知识库,且任务覆盖范围窄,缺乏多源分析能力。
- CTIArena通过构建异构、多源CTI基准,并采用知识增强方法,系统评估LLM在不同CTI任务上的性能。
- 实验结果表明,通用LLM在闭卷设置下表现不佳,但通过知识增强后性能显著提升,验证了领域定制技术的重要性。
📝 摘要(中文)
网络威胁情报(CTI)对于现代网络安全至关重要,它为检测和缓解不断演变的威胁提供了关键见解。随着大型语言模型(LLM)在自然语言理解和推理能力上的提升,人们对将其应用于CTI的兴趣日益浓厚,这也需要能够严格评估其性能的基准。现有的早期研究在某些CTI任务上对LLM进行了研究,但仍然存在局限性:(i)它们仅采用闭卷设置,依赖于参数知识,而没有利用CTI知识库;(ii)它们仅涵盖一小部分任务,缺乏对CTI领域的系统性认识;(iii)它们将评估限制在单源分析上,这与需要跨多个来源进行推理的实际场景不同。为了填补这些空白,我们提出了CTIArena,这是第一个在知识增强设置下评估LLM在异构、多源CTI上性能的基准。CTIArena跨越结构化、非结构化和混合三种类别,进一步细分为九个任务,涵盖了现代安全运营中CTI分析的广度。我们评估了十个广泛使用的LLM,发现大多数LLM在闭卷设置中表现不佳,但在通过我们设计的检索增强技术增强安全特定知识时,表现出明显的提升。这些发现突出了通用LLM的局限性,以及需要针对特定领域的技术来充分释放其在CTI中的潜力。
🔬 方法详解
问题定义:现有方法在评估LLM在网络威胁情报(CTI)领域的应用时,主要存在三个痛点:一是依赖闭卷设置,无法有效利用现有的CTI知识库;二是任务类型单一,无法全面评估LLM在不同CTI任务中的能力;三是缺乏多源信息融合能力,与实际应用场景不符。这些局限性导致无法准确评估LLM在CTI领域的真实性能,阻碍了LLM在该领域的应用。
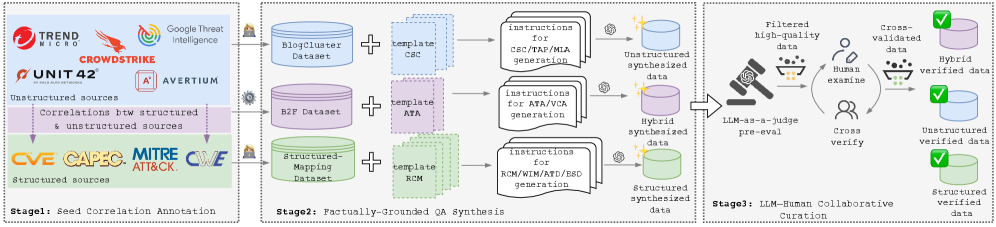
核心思路:CTIArena的核心思路是构建一个更贴近实际应用场景的CTI基准评测体系,通过引入异构、多源数据,并采用知识增强技术,全面评估LLM在不同CTI任务中的性能。该方法旨在弥补现有基准的不足,为LLM在CTI领域的应用提供更可靠的评估依据。
技术框架:CTIArena基准包含三个主要类别:结构化数据、非结构化数据和混合数据。每个类别下又细分为多个具体的CTI任务,例如恶意软件家族分类、漏洞利用分析、威胁行为者识别等。评估过程中,首先利用检索增强技术从CTI知识库中检索相关信息,然后将检索到的信息与输入数据一起输入到LLM中进行推理。最后,根据LLM的输出结果进行评估。
关键创新:CTIArena的关键创新在于其异构、多源的数据集构建方式和知识增强的评估方法。与传统的闭卷评估方法不同,CTIArena允许LLM利用外部知识库,从而更真实地反映了LLM在实际应用中的性能。此外,CTIArena还涵盖了更广泛的CTI任务,能够更全面地评估LLM在该领域的应用潜力。
关键设计:CTIArena的数据集构建过程中,采用了多种数据源,包括公开的CTI报告、漏洞数据库、恶意软件样本等。为了保证数据的质量,对数据进行了清洗和标注。在知识增强方面,采用了基于向量相似度的检索方法,从CTI知识库中检索与输入数据最相关的信息。评估指标方面,采用了准确率、召回率、F1值等常用的分类和信息检索指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在闭卷设置下,大多数LLM在CTIArena基准上的表现不佳。然而,通过检索增强技术,LLM的性能得到了显著提升。例如,在某些任务上,LLM的准确率提升了超过20%。这些结果表明,知识增强是提升LLM在CTI领域应用效果的关键。
🎯 应用场景
CTIArena的研究成果可应用于提升网络安全运营效率,例如自动化威胁情报分析、加速漏洞挖掘和响应、辅助安全事件溯源等。通过更准确地评估和优化LLM在CTI领域的应用,可以显著增强企业和组织的网络安全防御能力,降低安全风险。
📄 摘要(原文)
Cyber threat intelligence (CTI) is central to modern cybersecurity, providing critical insights for detecting and mitigating evolving threats. With the natural language understanding and reasoning capabilities of large language models (LLMs), there is increasing interest in applying them to CTI, which calls for benchmarks that can rigorously evaluate their performance. Several early efforts have studied LLMs on some CTI tasks but remain limited: (i) they adopt only closed-book settings, relying on parametric knowledge without leveraging CTI knowledge bases; (ii) they cover only a narrow set of tasks, lacking a systematic view of the CTI landscape; and (iii) they restrict evaluation to single-source analysis, unlike realistic scenarios that require reasoning across multiple sources. To fill these gaps, we present CTIArena, the first benchmark for evaluating LLM performance on heterogeneous, multi-source CTI under knowledge-augmented settings. CTIArena spans three categories, structured, unstructured, and hybrid, further divided into nine tasks that capture the breadth of CTI analysis in modern security operations. We evaluate ten widely used LLMs and find that most struggle in closed-book setups but show noticeable gains when augmented with security-specific knowledge through our designed retrieval-augmented techniques. These findings highlight the limitations of general-purpose LLMs and the need for domain-tailored techniques to fully unlock their potential for CTI.