Empirical Study on Robustness and Resilience in Cooperative Multi-Agent Reinforcement Learning
作者: Simin Li, Zihao Mao, Hanxiao Li, Zonglei Jing, Zhuohang bian, Jun Guo, Li Wang, Zhuoran Han, Ruixiao Xu, Xin Yu, Chengdong Ma, Yuqing Ma, Bo An, Yaodong Yang, Weifeng Lv, Xianglong Liu
分类: cs.MA, cs.AI, cs.LG
发布日期: 2025-10-13 (更新: 2025-10-23)
备注: 44 pages, 16 figures, NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
大规模实证研究揭示了合作多智能体强化学习中鲁棒性与韧性的关键影响因素。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 鲁棒性 韧性 不确定性 超参数优化
📋 核心要点
- 现有MARL方法在理想环境中优化,但在真实不确定性下鲁棒性和韧性不足。
- 通过大规模实验,研究不同不确定性、算法和超参数对MARL鲁棒性和韧性的影响。
- 发现优化超参数能显著提升合作、鲁棒性和韧性,且可泛化到不同MARL算法。
📝 摘要(中文)
在合作多智能体强化学习(MARL)中,通常在理想的模拟环境中调整超参数以最大化合作性能。然而,为合作而调整的策略往往无法在现实世界的不确定性下保持鲁棒性和韧性。构建可信的MARL系统需要深入理解鲁棒性(确保在不确定性下的稳定性)和韧性(从中断中恢复的能力)——这两个概念在控制系统中被广泛研究,但在MARL中却在很大程度上被忽视。本文进行了一项大规模的实证研究,包含超过82,620个实验,以评估MARL在4个真实环境、13种不确定性类型和15个超参数下的合作、鲁棒性和韧性。研究的关键发现包括:(1)在轻微的不确定性下,优化合作可以提高鲁棒性和韧性,但随着扰动强度的增加,这种联系会减弱。鲁棒性和韧性也因算法和不确定性类型而异。(2)鲁棒性和韧性不能跨不确定性模式或智能体范围泛化:对所有智能体的动作噪声具有鲁棒性的策略可能在单个智能体的观察噪声下失效。(3)超参数调整对于可信的MARL至关重要:令人惊讶的是,参数共享、GAE和PopArt等标准实践可能会损害鲁棒性,而提前停止、高评论家学习率和Leaky ReLU始终有所帮助。通过仅优化超参数,我们观察到所有MARL骨干网络在合作、鲁棒性和韧性方面都有显著提高,这种现象也推广到这些骨干网络上的鲁棒MARL方法。
🔬 方法详解
问题定义:现有的合作多智能体强化学习方法通常在理想化的模拟环境中进行训练和优化,忽略了真实世界中普遍存在的不确定性。这导致训练出的策略在实际部署时,面对各种扰动和干扰,鲁棒性和韧性较差,难以保证稳定的合作性能。现有方法缺乏对鲁棒性和韧性的系统性研究和优化,使得MARL系统难以信任和应用。
核心思路:该论文的核心思路是通过大规模的实证研究,系统性地评估不同因素(包括环境、不确定性类型、算法和超参数)对MARL系统鲁棒性和韧性的影响。通过分析实验结果,揭示影响鲁棒性和韧性的关键因素,并探索如何通过优化超参数来提升MARL系统的鲁棒性和韧性。
技术框架:该研究的技术框架主要包括以下几个部分:1)选择4个真实世界的合作环境;2)定义13种不同类型的不确定性,涵盖动作噪声、观察噪声、通信干扰等;3)选择多个主流的MARL算法作为基线;4)设计大规模的实验,系统性地评估不同算法在不同环境和不确定性下的合作性能、鲁棒性和韧性;5)分析实验结果,揭示影响鲁棒性和韧性的关键因素,并探索如何通过优化超参数来提升MARL系统的鲁棒性和韧性。
关键创新:该论文最重要的技术创新点在于其大规模的实证研究方法,以及对MARL系统鲁棒性和韧性的系统性评估。该研究首次在如此大规模的实验中,系统性地研究了不同因素对MARL系统鲁棒性和韧性的影响,揭示了一些重要的规律和结论,例如,鲁棒性和韧性不能跨不确定性模式或智能体范围泛化,以及超参数调整对鲁棒性和韧性的重要性。
关键设计:该研究的关键设计包括:1)选择具有代表性的真实世界环境,以保证研究结果的实际意义;2)定义多样化的不确定性类型,以全面评估MARL系统的鲁棒性和韧性;3)选择多个主流的MARL算法作为基线,以保证研究结果的通用性;4)设计大规模的实验,并进行充分的统计分析,以保证研究结果的可靠性;5)通过优化超参数,验证提升鲁棒性和韧性的有效性。例如,发现提前停止、高评论家学习率和Leaky ReLU等超参数设置可以显著提升MARL系统的鲁棒性和韧性。
🖼️ 关键图片
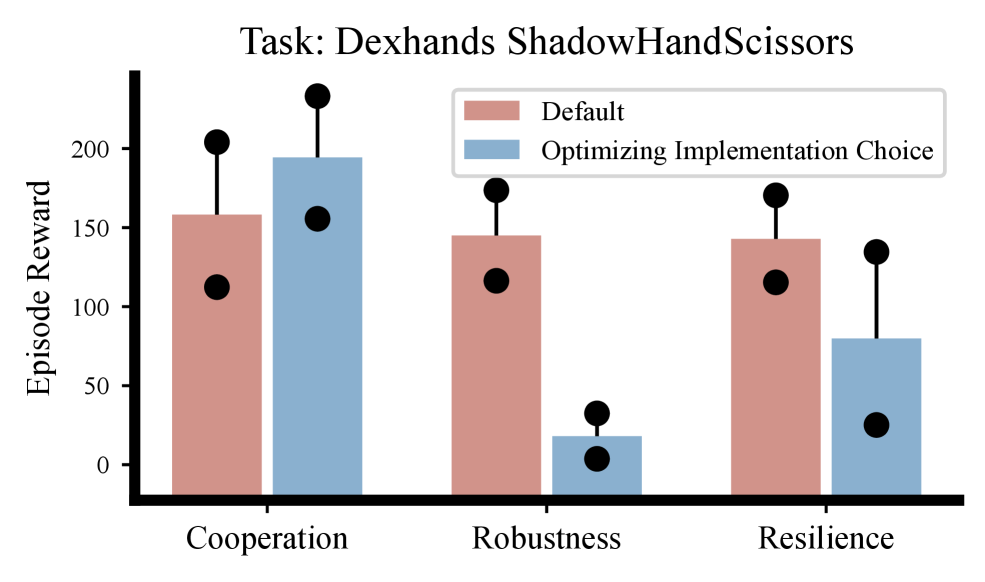


📊 实验亮点
该研究通过超过82,620个实验发现,在轻微不确定性下,优化合作能提升鲁棒性和韧性,但随着扰动增强,此联系减弱。鲁棒性和韧性不具备跨不确定性或智能体泛化能力。超参数调整至关重要,例如,参数共享等标准实践可能损害鲁棒性,而提前停止、高评论家学习率和Leaky ReLU则有帮助。通过优化超参数,所有MARL骨干网络在合作、鲁棒性和韧性方面均有显著提升。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作且环境存在不确定性的实际场景,例如自动驾驶、机器人协同、智能交通、资源分配等。通过提升MARL系统的鲁棒性和韧性,可以使其在真实世界中更加可靠和稳定,从而提高系统的效率和安全性,并降低部署和维护成本。
📄 摘要(原文)
In cooperative Multi-Agent Reinforcement Learning (MARL), it is a common practice to tune hyperparameters in ideal simulated environments to maximize cooperative performance. However, policies tuned for cooperation often fail to maintain robustness and resilience under real-world uncertainties. Building trustworthy MARL systems requires a deep understanding of robustness, which ensures stability under uncertainties, and resilience, the ability to recover from disruptions--a concept extensively studied in control systems but largely overlooked in MARL. In this paper, we present a large-scale empirical study comprising over 82,620 experiments to evaluate cooperation, robustness, and resilience in MARL across 4 real-world environments, 13 uncertainty types, and 15 hyperparameters. Our key findings are: (1) Under mild uncertainty, optimizing cooperation improves robustness and resilience, but this link weakens as perturbations intensify. Robustness and resilience also varies by algorithm and uncertainty type. (2) Robustness and resilience do not generalize across uncertainty modalities or agent scopes: policies robust to action noise for all agents may fail under observation noise on a single agent. (3) Hyperparameter tuning is critical for trustworthy MARL: surprisingly, standard practices like parameter sharing, GAE, and PopArt can hurt robustness, while early stopping, high critic learning rates, and Leaky ReLU consistently help. By optimizing hyperparameters only, we observe substantial improvement in cooperation, robustness and resilience across all MARL backbones, with the phenomenon also generalizing to robust MARL methods across these backbones. Code and results available at https://github.com/BUAA-TrustworthyMARL/adv_marl_benchmark .