Beyond Consensus: Mitigating the Agreeableness Bias in LLM Judge Evaluations
作者: Suryaansh Jain, Umair Z. Ahmed, Shubham Sahai, Ben Leong
分类: cs.AI
发布日期: 2025-10-13 (更新: 2025-12-24)
💡 一句话要点
提出少数否决与回归模型,缓解LLM评判中的一致性偏差,提升代码评估精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评判 一致性偏差 少数否决 回归模型 代码评估 偏差建模
📋 核心要点
- 现有LLM评判方法存在严重的一致性偏差,难以准确识别无效输出,导致评估结果虚高。
- 提出最优少数否决策略和回归模型,前者通过否决机制降低偏差,后者直接建模并校正偏差。
- 实验表明,在代码评估任务中,回归模型将最大绝对误差降低至1.2%,显著优于现有集成方法。
📝 摘要(中文)
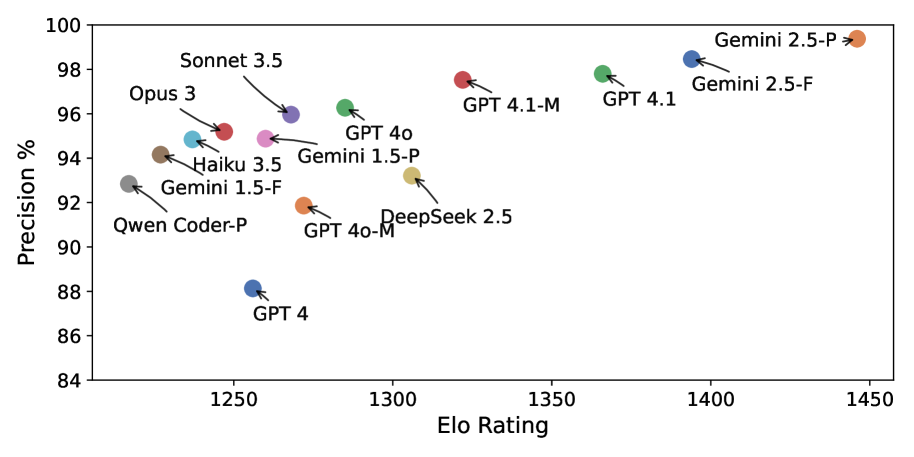
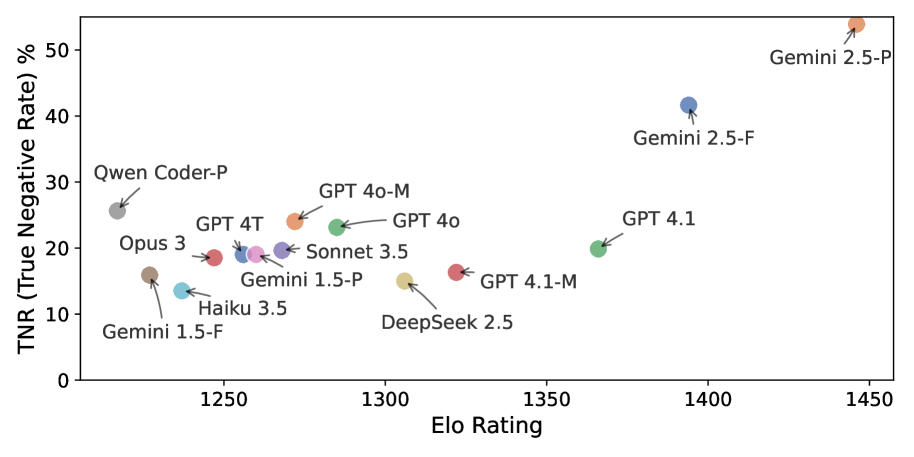
新的大型语言模型(LLMs)不断涌现,应用开发者面临着是否切换到新模型的艰巨任务。虽然人工评估仍然是黄金标准,但成本高昂且难以扩展。目前最先进的方法是使用LLMs作为评估者(LLM-as-a-judge),但这种方法存在一个关键缺陷:LLMs表现出很强的积极偏差。我们提供的经验证据表明,虽然LLMs可以高精度地识别有效输出(即,真阳性率96%),但它们在识别无效输出方面非常差(即,真阴性率<25%)。这种系统性偏差,加上类别不平衡,通常会导致虚高的可靠性评分。虽然像多数投票这样的集成方法有所帮助,但我们表明它们还不够好。我们引入了一种最优的少数否决策略,该策略能够应对数据缺失并很大程度上缓解这种偏差。对于需要更高精度的场景,我们提出了一种新颖的基于回归的框架,该框架使用一小部分人工标注的ground truth数据直接对验证器的偏差进行建模。在一个具有挑战性的代码反馈任务中,针对366个高中Python程序,我们的回归方法将最大绝对误差降低到仅1.2%,比性能最佳的14个最先进LLM的集成方法提高了2倍。
🔬 方法详解
问题定义:论文旨在解决使用LLM作为评判器时,由于LLM固有的“一致性偏差”(Agreeableness Bias)而导致的评估不准确问题。现有方法,如多数投票,无法有效缓解这种偏差,尤其是在识别无效输出时表现较差,导致评估结果的可靠性降低。
核心思路:论文的核心思路是识别并缓解LLM评判中的一致性偏差。通过引入少数否决策略,利用LLM识别有效输出的高准确率,减少错误接受无效输出的情况。对于更高精度的需求,采用回归模型直接建模并校正LLM的偏差。
技术框架:论文提出了两种主要方法:1) 最优少数否决策略:通过设置否决阈值,当少数LLM评判为无效时,则整体判定为无效,从而降低假阳性率。该策略考虑了数据缺失的情况。2) 基于回归的偏差建模:使用少量人工标注数据作为ground truth,训练回归模型来预测LLM的偏差,并利用该模型校正LLM的评估结果。整体流程包括数据收集、LLM评判、偏差建模/少数否决、结果校正/判定。
关键创新:论文的关键创新在于:1) 提出了“一致性偏差”的概念,并对其进行了量化分析。2) 设计了最优少数否决策略,能够在数据缺失的情况下有效降低偏差。3) 构建了基于回归模型的偏差建模框架,能够直接学习并校正LLM的偏差,显著提高评估精度。
关键设计:在少数否决策略中,关键在于确定最优的否决阈值,这需要根据具体的LLM性能和数据分布进行调整。在回归模型中,关键在于选择合适的特征来描述LLM的偏差,例如LLM的类型、输入文本的特征等。损失函数可以选择均方误差或绝对误差,以最小化预测偏差与真实偏差之间的差异。回归模型的具体结构(如线性回归、神经网络等)可以根据数据的复杂程度进行选择。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在高中Python程序代码反馈任务中,基于回归的偏差建模方法将最大绝对误差降低至1.2%,相比于由14个最先进LLM组成的集成方法,性能提升了2倍。这表明该方法能够有效缓解LLM评判中的一致性偏差,显著提高评估精度。
🎯 应用场景
该研究成果可广泛应用于LLM的自动评估、代码生成质量评估、文本摘要质量评估等领域。通过降低LLM评判中的偏差,可以更准确地评估LLM的性能,从而指导LLM的开发和优化。此外,该方法还可以应用于其他需要自动评估的场景,例如机器翻译质量评估、图像生成质量评估等。
📄 摘要(原文)
New Large Language Models (LLMs) become available every few weeks, and modern application developers confronted with the unenviable task of having to decide if they should switch to a new model. While human evaluation remains the gold standard, it is costly and unscalable. The state-of-the-art approach is to use LLMs as evaluators ( LLM-as-a-judge), but this suffers from a critical flaw: LLMs exhibit a strong positive bias. We provide empirical evidence showing that while LLMs can identify valid outputs with high accuracy (i.e., True Positive Rate 96%), they are remarkably poor at identifying invalid ones (i.e., True Negative Rate <25%). This systematic bias, coupled with class imbalance, often leads to inflated reliability scores. While ensemble-based methods like majority voting can help, we show that they are not good enough. We introduce an optimal minority-veto strategy that is resilient to missing data and mitigates this bias to a large extent. For scenarios requiring even higher precision, we propose a novel regression-based framework that directly models the validator bias using a small set of human-annotated ground truth data. On a challenging code feedback task over 366 high-school Python programs, our regression approach reduces the maximum absolute error to just 1.2%, achieving a 2x improvement over the best-performing ensemble of 14 state-of-the-art LLMs.