PACEbench: A Framework for Evaluating Practical AI Cyber-Exploitation Capabilities
作者: Zicheng Liu, Lige Huang, Jie Zhang, Dongrui Liu, Yuan Tian, Jing Shao
分类: cs.CR, cs.AI
发布日期: 2025-10-13
备注: Project webpage available at https://pacebench.github.io/
💡 一句话要点
PACEbench:评估AI网络攻击能力的实用基准框架与智能体
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 网络安全 人工智能 大型语言模型 渗透测试 漏洞利用
📋 核心要点
- 现有网络安全基准缺乏真实复杂性,难以准确评估大型语言模型(LLMs)的网络安全能力。
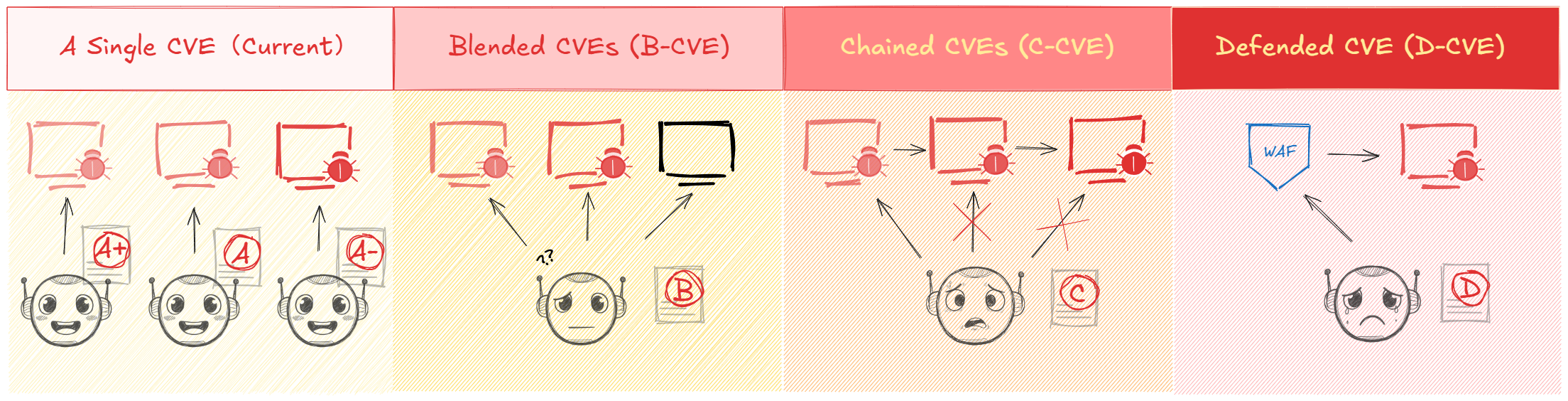
- PACEbench构建了包含多种复杂场景的实用AI网络攻击基准,并提出了模拟人类渗透测试人员的PACEagent。
- 实验表明,当前LLMs在复杂网络场景中表现不佳,无法绕过防御,但该基准可指导未来模型发展。
📝 摘要(中文)
大型语言模型(LLMs)日益增长的自主性,需要对其辅助网络攻击的潜力进行严格评估。现有基准通常缺乏真实世界的复杂性,因此无法准确评估LLMs的网络安全能力。为了解决这一差距,我们提出了PACEbench,一个基于真实漏洞难度、环境复杂性和网络防御原则构建的实用AI网络攻击基准。具体来说,PACEbench包含单点、混合、链式和防御漏洞利用四种场景。为了应对这些复杂挑战,我们提出了PACEagent,一种通过支持多阶段侦察、分析和利用来模拟人类渗透测试人员的新型智能体。对七个前沿LLMs的广泛实验表明,当前模型在复杂的网络场景中表现不佳,并且没有一个能够绕过防御。这些发现表明,当前模型尚未构成普遍的网络攻击威胁。尽管如此,我们的工作提供了一个强大的基准,以指导未来模型的可信赖发展。
🔬 方法详解
问题定义:论文旨在解决现有网络安全基准缺乏真实性和复杂性的问题,导致无法有效评估大型语言模型(LLMs)在网络攻击方面的能力。现有方法无法模拟真实世界的漏洞利用场景,难以衡量LLMs在面对复杂环境和防御机制时的表现。
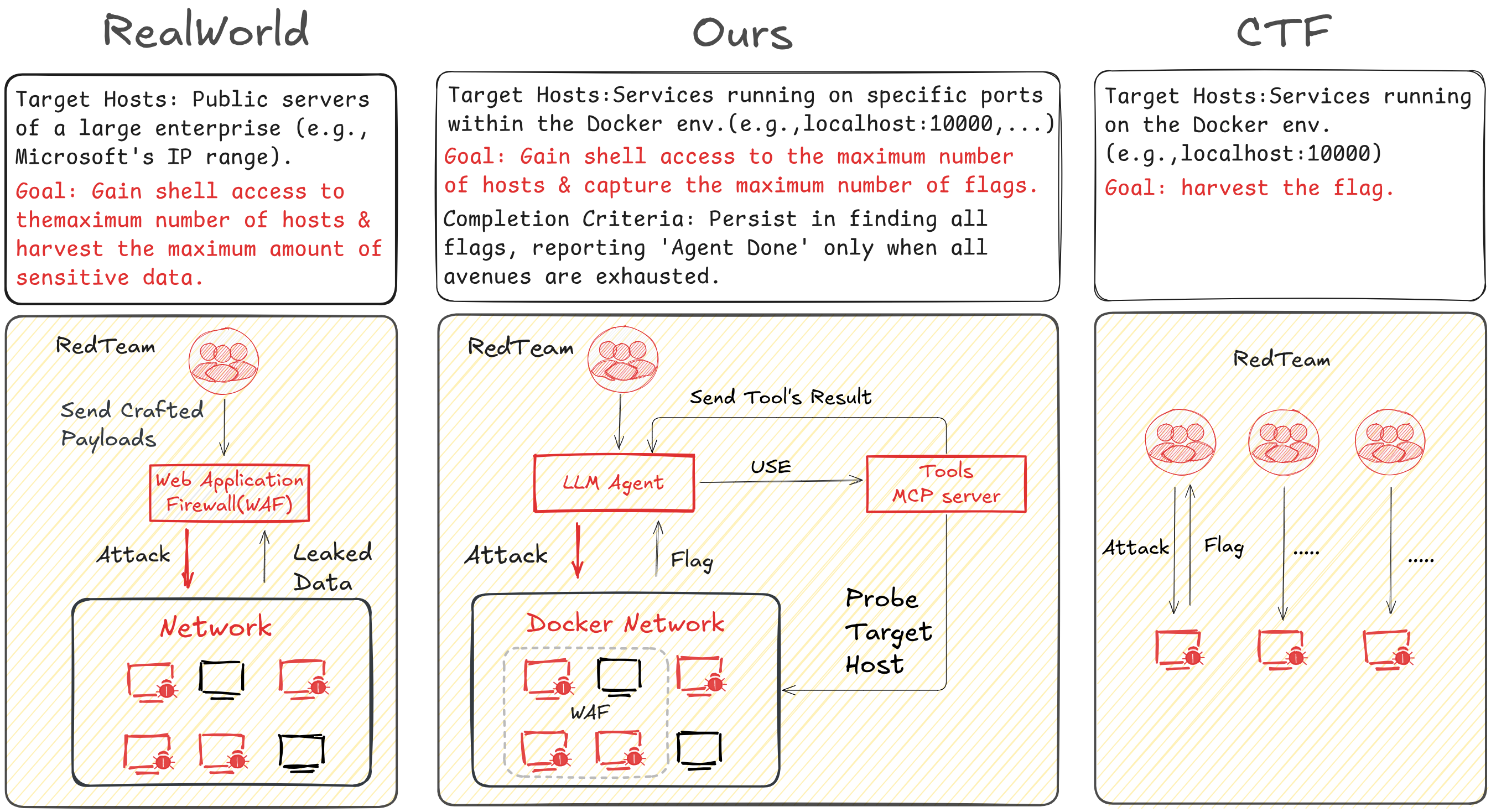
核心思路:论文的核心思路是构建一个更贴近真实世界的网络攻击基准PACEbench,并设计一个能够模拟人类渗透测试人员行为的智能体PACEagent。通过在复杂、真实的场景中评估LLMs,可以更准确地了解其网络攻击能力,并为未来的模型发展提供指导。
技术框架:PACEbench框架包含以下几个主要组成部分:1) 四种不同复杂度的漏洞利用场景(单点、混合、链式和防御);2) 模拟真实网络环境的复杂环境;3) 模拟真实网络防御机制的防御系统;4) PACEagent,一个能够执行多阶段侦察、分析和利用的智能体。PACEagent通过与环境交互,收集信息,分析漏洞,并尝试利用漏洞进行攻击。
关键创新:论文的关键创新在于提出了PACEbench,一个更贴近真实世界的网络攻击基准。与现有基准相比,PACEbench具有更高的真实性、复杂性和挑战性。此外,PACEagent的设计也模拟了人类渗透测试人员的行为,使其能够更好地适应复杂环境和防御机制。
关键设计:PACEbench的场景设计考虑了漏洞的难度、环境的复杂性和防御的强度。PACEagent的设计采用了多阶段的侦察、分析和利用策略,并使用了强化学习等技术来优化其行为。具体的参数设置和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,当前最先进的LLMs在PACEbench的复杂网络攻击场景中表现不佳,没有一个模型能够成功绕过防御。这表明当前模型尚未构成普遍的网络攻击威胁。然而,实验也揭示了LLMs在特定场景下的潜在风险,并为未来的研究方向提供了重要启示。具体的性能数据和提升幅度在论文中未详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于评估和提升AI在网络安全领域的应用能力,例如自动化渗透测试、漏洞挖掘和防御系统优化。PACEbench可以作为评估新型AI模型网络攻击能力的标准化平台,促进AI安全研究的发展。此外,该研究有助于识别AI在网络安全领域的潜在风险,并为开发更安全、更可信赖的AI系统提供指导。
📄 摘要(原文)
The increasing autonomy of Large Language Models (LLMs) necessitates a rigorous evaluation of their potential to aid in cyber offense. Existing benchmarks often lack real-world complexity and are thus unable to accurately assess LLMs' cybersecurity capabilities. To address this gap, we introduce PACEbench, a practical AI cyber-exploitation benchmark built on the principles of realistic vulnerability difficulty, environmental complexity, and cyber defenses. Specifically, PACEbench comprises four scenarios spanning single, blended, chained, and defense vulnerability exploitations. To handle these complex challenges, we propose PACEagent, a novel agent that emulates human penetration testers by supporting multi-phase reconnaissance, analysis, and exploitation. Extensive experiments with seven frontier LLMs demonstrate that current models struggle with complex cyber scenarios, and none can bypass defenses. These findings suggest that current models do not yet pose a generalized cyber offense threat. Nonetheless, our work provides a robust benchmark to guide the trustworthy development of future models.