A Flexible Multi-Agent Deep Reinforcement Learning Framework for Dynamic Routing and Scheduling of Latency-Critical Services
作者: Vincenzo Norman Vitale, Antonia Maria Tulino, Andreas F. Molisch, Jaime Llorca
分类: cs.NI, cs.AI
发布日期: 2025-10-13
💡 一句话要点
提出一种灵活的多智能体深度强化学习框架,用于延迟敏感服务的动态路由和调度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 动态路由 网络调度 延迟敏感服务 MADDPG
📋 核心要点
- 现有网络控制方案主要关注平均延迟性能,无法提供严格的端到端峰值延迟保证,难以满足延迟敏感型应用的需求。
- 提出一种基于集中式路由和分布式调度的多智能体深度强化学习框架,利用MADDPG算法动态优化路径分配和数据包调度。
- 实验结果表明,该框架优于传统的随机优化方法,并能有效平衡数据驱动智能体和规则策略,实现高效高性能的延迟关键服务控制。
📝 摘要(中文)
本文针对动态异构网络中延迟敏感信息传输问题,提出了一种基于多智能体深度强化学习(MA-DRL)的网络控制框架,旨在满足严格的端到端(E2E)峰值延迟保证。该框架解决了延迟约束最大吞吐量(DCMT)动态网络控制问题,并克服了现有解决方案的局限性。该框架采用集中式路由和分布式调度架构,利用多智能体深度确定性策略梯度(MADDPG)技术,根据数据包的生存时间动态分配路径和调度数据包传输,从而最大限度地提高准时数据包的交付。该框架的通用性允许集成数据驱动的深度强化学习(DRL)智能体和传统的基于规则的策略,以平衡性能和学习复杂性。实验结果表明,所提出的框架优于传统的基于随机优化的方法,并为数据驱动的DRL智能体和新的基于规则的策略在高效和高性能控制延迟关键服务中的作用和相互作用提供了关键见解。
🔬 方法详解
问题定义:论文旨在解决动态异构网络中延迟敏感型服务的动态路由和调度问题,目标是在满足端到端延迟约束的前提下最大化网络吞吐量。现有方法通常只关注平均延迟,无法保证严格的峰值延迟,导致无法满足工业自动化、自动驾驶、增强现实等应用的需求。
核心思路:论文的核心思路是利用多智能体深度强化学习(MA-DRL)来学习最优的路由和调度策略。通过将网络中的每个节点视为一个智能体,并使用MADDPG算法进行训练,使智能体能够协同工作,共同优化网络的性能。集中式路由负责全局路径规划,分布式调度则根据本地信息进行数据包传输调度,从而实现高效的资源利用和延迟控制。
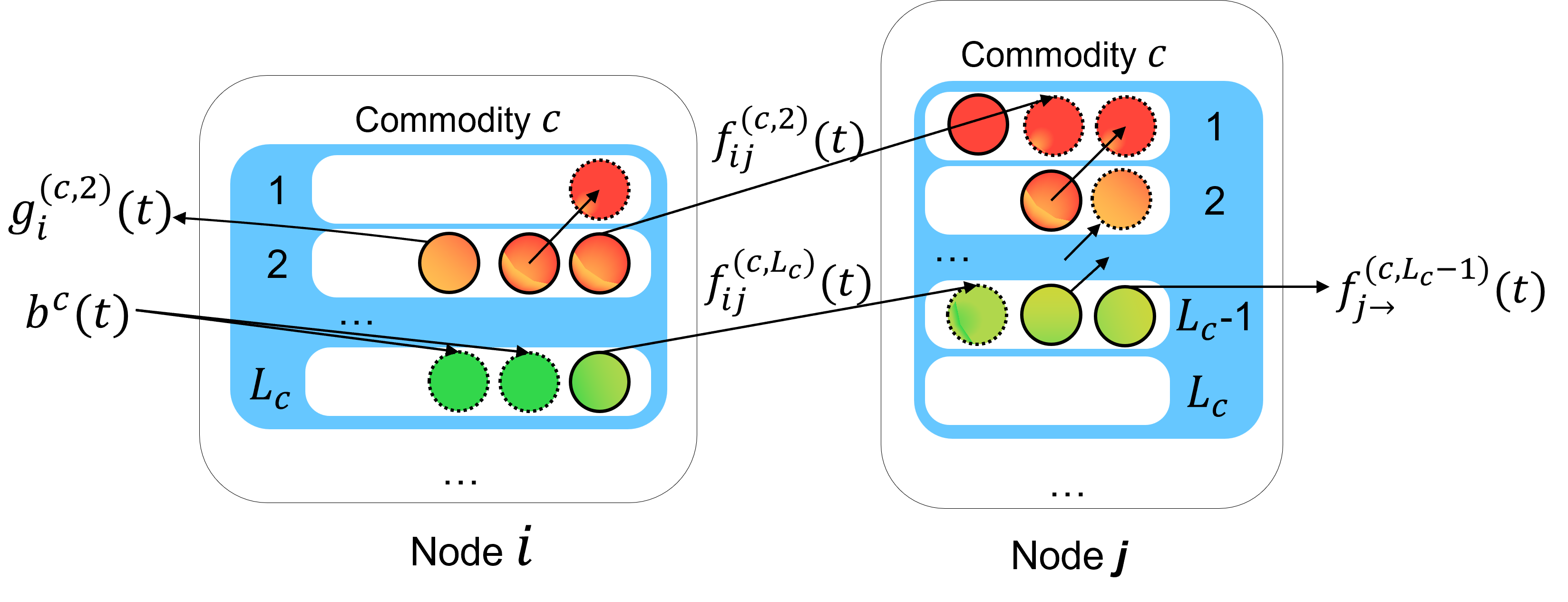
技术框架:该框架采用集中式路由和分布式调度相结合的架构。集中式路由模块负责根据全局网络状态信息,为每个数据包选择最优路径。分布式调度模块则位于每个网络节点,负责根据本地队列状态和数据包的生存时间,决定数据包的传输顺序。MA-DRL智能体通过与网络环境交互,不断学习和优化路由和调度策略。
关键创新:该论文的关键创新在于将MA-DRL应用于动态网络控制,并提出了一种集中式路由和分布式调度相结合的架构。这种架构能够充分利用全局和局部信息,实现高效的资源利用和延迟控制。此外,该框架还具有很强的灵活性,可以集成数据驱动的DRL智能体和传统的基于规则的策略,以平衡性能和学习复杂性。
关键设计:该框架使用MADDPG算法进行训练,每个智能体都有一个Actor网络和一个Critic网络。Actor网络负责输出路由或调度策略,Critic网络负责评估该策略的价值。损失函数包括延迟约束和吞吐量最大化两部分。网络结构方面,使用了多层感知机(MLP)来提取网络状态特征,并使用GRU(Gated Recurrent Unit)来处理时序信息。关键参数包括学习率、折扣因子、探索率等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的MA-DRL框架在延迟约束下能够显著提高网络吞吐量,优于传统的基于随机优化的方法。具体而言,在某些场景下,该框架可以将准时数据包的交付率提高10%-20%。此外,实验还验证了数据驱动的DRL智能体和基于规则的策略相结合的有效性,表明该框架具有很强的灵活性和适应性。
🎯 应用场景
该研究成果可应用于工业自动化、自动驾驶、增强现实等对延迟有严格要求的领域。通过优化网络路由和调度,可以保证关键数据的及时传输,提高系统的可靠性和性能。未来,该技术有望应用于更复杂的网络环境,例如无线传感器网络、边缘计算网络等,为各种新兴应用提供可靠的网络保障。
📄 摘要(原文)
Timely delivery of delay-sensitive information over dynamic, heterogeneous networks is increasingly essential for a range of interactive applications, such as industrial automation, self-driving vehicles, and augmented reality. However, most existing network control solutions target only average delay performance, falling short of providing strict End-to-End (E2E) peak latency guarantees. This paper addresses the challenge of reliably delivering packets within application-imposed deadlines by leveraging recent advancements in Multi-Agent Deep Reinforcement Learning (MA-DRL). After introducing the Delay-Constrained Maximum-Throughput (DCMT) dynamic network control problem, and highlighting the limitations of current solutions, we present a novel MA-DRL network control framework that leverages a centralized routing and distributed scheduling architecture. The proposed framework leverages critical networking domain knowledge for the design of effective MA-DRL strategies based on the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) technique, where centralized routing and distributed scheduling agents dynamically assign paths and schedule packet transmissions according to packet lifetimes, thereby maximizing on-time packet delivery. The generality of the proposed framework allows integrating both data-driven \blue{Deep Reinforcement Learning (DRL)} agents and traditional rule-based policies in order to strike the right balance between performance and learning complexity. Our results confirm the superiority of the proposed framework with respect to traditional stochastic optimization-based approaches and provide key insights into the role and interplay between data-driven DRL agents and new rule-based policies for both efficient and high-performance control of latency-critical services.