Diffusion-Link: Diffusion Probabilistic Model for Bridging the Audio-Text Modality Gap
作者: KiHyun Nam, Jongmin Choi, Hyeongkeun Lee, Jungwoo Heo, Joon Son Chung
分类: cs.SD, cs.AI, cs.CL, cs.LG, eess.AS
发布日期: 2025-10-13
备注: 5 pages. Submitted to IEEE ICASSP 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出Diffusion-Link,通过扩散模型弥合音频-文本模态鸿沟,提升音频自动描述性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 模态桥接 音频描述 多模态学习 音频-文本融合
📋 核心要点
- 现有对比音频-语言预训练方法受限于音频-文本模态鸿沟,阻碍了多模态编码器与大型语言模型的有效结合。
- Diffusion-Link通过扩散模型学习音频嵌入到文本嵌入的映射,从而弥合模态鸿沟,提升多模态融合效果。
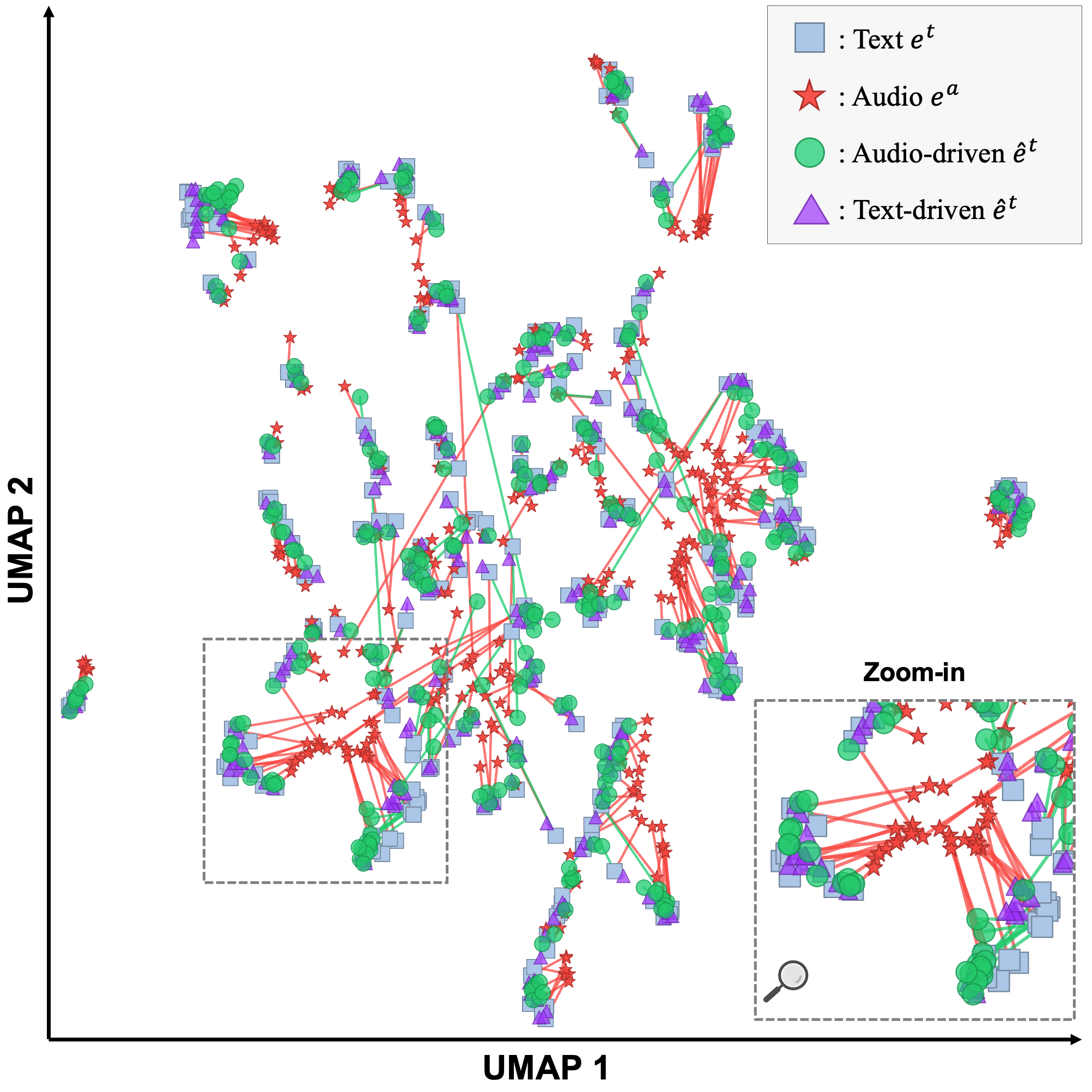
- 实验表明,Diffusion-Link在AudioCaps音频描述任务上取得了显著的性能提升,无需外部知识即可达到SOTA。
📝 摘要(中文)
对比音频-语言预训练能够产生强大的联合表示,但持续存在的音频-文本模态鸿沟限制了多模态编码器与大型语言模型(LLM)耦合的益处。我们提出了Diffusion-Link,一个基于扩散的模态桥接模块,它将音频嵌入生成式地映射到文本嵌入分布中。该模块在冻结的多模态编码器的输出嵌入上进行训练,并实现为一个轻量级网络,包含三个残差MLP块。为了评估Diffusion-Link对多模态编码器-LLM耦合的影响,我们在自动音频描述(AAC)任务上进行了评估;据我们所知,这是基于扩散的模态桥接在AAC中的首次应用。我们报告了两个结果。(1)模态鸿沟分析:在相似性和几何标准上,Diffusion-Link在先前的基于扩散的方法中减少模态鸿沟最多,并显示了音频嵌入向文本分布的集体迁移。(2)下游AAC:将Diffusion-Link附加到相同的多模态LLM基线上,在AudioCaps上实现了零样本和完全监督描述的最先进水平,在没有外部知识的情况下,分别获得了高达52.5%和7.5%的相对收益。这些发现表明,弥合模态鸿沟对于多模态编码器和LLM之间的有效耦合至关重要,并且基于扩散的模态桥接提供了一个超越以知识检索为中心的设计的有希望的方向。
🔬 方法详解
问题定义:论文旨在解决音频-文本多模态学习中,由于模态差异导致的特征空间不对齐问题。现有方法难以有效利用预训练的多模态编码器,限制了其与大型语言模型结合的潜力。这种模态鸿沟阻碍了音频信息向文本信息的有效迁移和融合。
核心思路:论文的核心思路是利用扩散概率模型学习音频嵌入到文本嵌入的映射关系,从而将音频特征转换到与文本特征更接近的分布空间。通过这种模态桥接,可以更好地利用预训练的多模态编码器,并提升下游任务的性能。
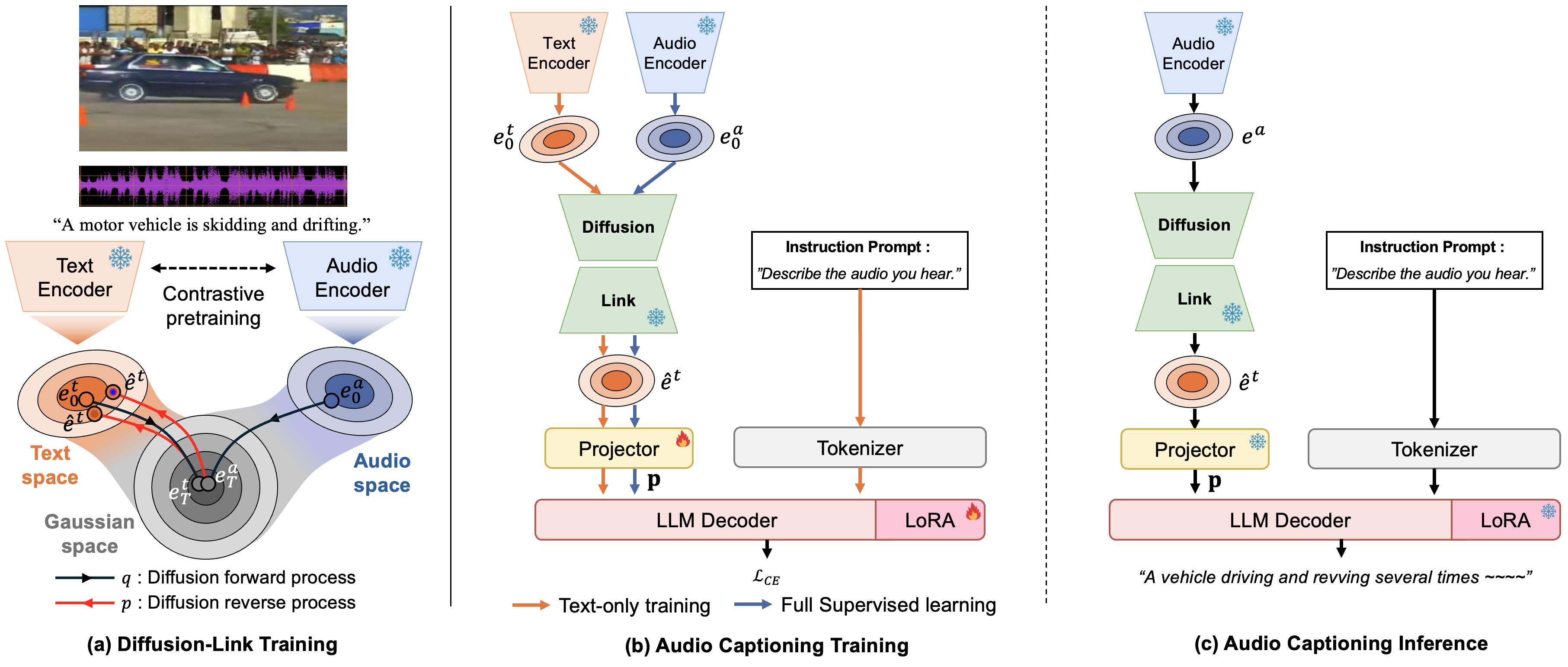
技术框架:Diffusion-Link模块位于冻结的多模态编码器之后,作为一个独立的模态桥接模块。整体流程如下:1) 音频输入通过多模态编码器得到音频嵌入;2) Diffusion-Link将音频嵌入映射到文本嵌入空间;3) 映射后的嵌入与文本嵌入一起输入到大型语言模型中进行下游任务。Diffusion-Link本身是一个轻量级网络,由三个残差MLP块组成。
关键创新:论文的关键创新在于将扩散模型应用于音频-文本模态桥接,通过生成式的方式学习模态间的映射关系。与传统的对比学习方法相比,扩散模型能够更灵活地捕捉模态间的复杂关系,从而更有效地弥合模态鸿沟。这是首次将扩散模型应用于自动音频描述任务。
关键设计:Diffusion-Link模块使用标准的扩散模型训练流程。具体来说,首先对音频嵌入添加高斯噪声,然后训练网络学习从噪声中恢复原始音频嵌入。训练目标是最小化噪声预测误差。网络结构采用三个残差MLP块,以保证模型的轻量性和表达能力。论文没有提供具体的参数设置细节,但强调了模块的轻量化设计。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Diffusion-Link在AudioCaps数据集上取得了显著的性能提升。在零样本音频描述任务中,相对提升高达52.5%;在完全监督的音频描述任务中,相对提升达到7.5%。这些结果表明,Diffusion-Link能够有效弥合音频-文本模态鸿沟,并提升多模态系统的性能,无需依赖外部知识。
🎯 应用场景
该研究成果可广泛应用于音频理解、语音识别、音乐生成等领域。通过弥合音频-文本模态鸿沟,可以提升多模态系统的性能和鲁棒性,例如改进语音助手、智能客服等应用。未来,该方法有望扩展到其他模态,如视频、图像等,实现更强大的多模态智能。
📄 摘要(原文)
Contrastive audio-language pretraining yields powerful joint representations, yet a persistent audio-text modality gap limits the benefits of coupling multimodal encoders with large language models (LLMs). We present Diffusion-Link, a diffusion-based modality-bridging module that generatively maps audio embeddings into the text-embedding distribution. The module is trained at the output embedding from the frozen multimodal encoder and implemented as a lightweight network with three residual MLP blocks. To assess the effect of Diffusion-Link on multimodal encoder-LLM coupling, we evaluate on Automatic Audio Captioning (AAC); to our knowledge, this is the first application of diffusion-based modality bridging to AAC. We report two results. (1) Modality-gap analysis: on similarity and geometric criteria, Diffusion-Link reduces the modality gap the most among prior diffusion-based methods and shows a collective migration of audio embeddings toward the text distribution. (2) Downstream AAC: attaching Diffusion-Link to the same multimodal LLM baseline achieves state-of-the-art on AudioCaps in both zero-shot and fully supervised captioning without external knowledge, with relative gains up to 52.5% and 7.5%, respectively. These findings show that closing the modality gap is pivotal for effective coupling between multimodal encoders and LLMs, and diffusion-based modality bridging offers a promising direction beyond knowledge-retrieval-centric designs. Code will be released upon acceptance https://github.com/DevKiHyun/Diffusion-Link