Large Language Models Are Effective Code Watermarkers
作者: Rui Xu, Jiawei Chen, Zhaoxia Yin, Cong Kong, Xinpeng Zhang
分类: cs.CR, cs.AI, cs.LG
发布日期: 2025-10-13
💡 一句话要点
提出 CodeMark-LLM,利用大语言模型实现高效的代码水印嵌入与提取。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码水印 大语言模型 源代码溯源 版权保护 语义保持转换
📋 核心要点
- 现有代码水印技术依赖手工规则或特定任务训练,泛化能力和鲁棒性不足,难以应对复杂的攻击。
- CodeMark-LLM利用LLM的跨语言能力,通过语义一致的转换嵌入水印,并通过差分比较提取水印信息。
- 实验证明,CodeMark-LLM在多种编程语言和攻击场景下表现出良好的鲁棒性、有效性和可扩展性。
📝 摘要(中文)
随着大型语言模型(LLM)和开源代码的广泛使用,源代码的发布和归属面临着道德和安全问题,包括未经授权的再分发、违反许可协议以及恶意使用代码。水印技术为源代码归属提供了一种有前景的解决方案,但现有技术严重依赖于手工设计的转换规则、抽象语法树(AST)操作或特定任务的训练,限制了它们在不同语言中的可扩展性和通用性,并且针对攻击的鲁棒性有限。为了解决这些局限性,我们提出了一种由LLM驱动的水印框架CodeMark-LLM,该框架将水印嵌入到源代码中,同时不影响其语义或可读性。CodeMark-LLM由两个核心组件组成:(i)语义一致嵌入模块,它应用功能保持转换来编码水印位;(ii)差分比较提取模块,它通过比较原始代码和带有水印的代码来识别所应用的转换。利用LLM的跨语言泛化能力,CodeMark-LLM避免了特定于语言的工程和训练流程。在各种编程语言和攻击场景下进行的大量实验证明了其鲁棒性、有效性和可扩展性。
🔬 方法详解
问题定义:现有的代码水印技术通常依赖于手工设计的规则或特定于任务的训练,这导致了两个主要问题:一是泛化能力差,难以适应不同的编程语言和代码风格;二是鲁棒性不足,容易受到各种攻击手段的干扰,导致水印失效。这些方法通常需要大量的领域知识和人工干预,难以扩展到大规模的代码库中。
核心思路:CodeMark-LLM的核心思路是利用大型语言模型(LLM)强大的代码理解和生成能力,通过语义保持的转换来嵌入水印。这种方法避免了手工设计规则的繁琐过程,并且可以利用LLM的跨语言泛化能力,实现对多种编程语言的支持。通过比较原始代码和带有水印的代码,可以提取出嵌入的水印信息。
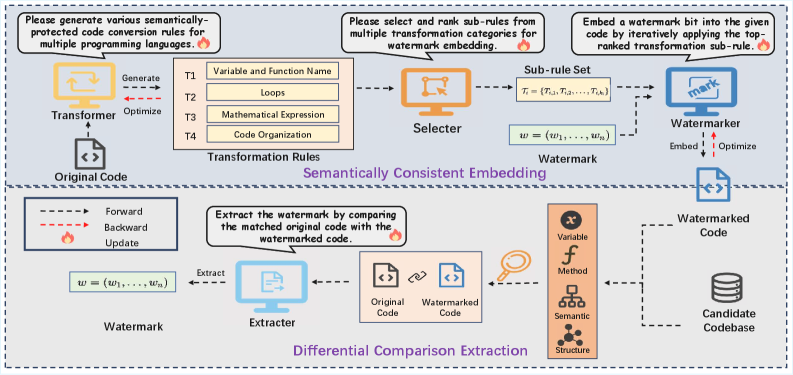
技术框架:CodeMark-LLM框架包含两个主要模块:语义一致嵌入模块和差分比较提取模块。语义一致嵌入模块负责将水印信息编码到源代码中,通过应用功能保持的转换,例如变量重命名、代码重排等,来嵌入水印位。差分比较提取模块则通过比较原始代码和带有水印的代码,识别出所应用的转换,从而提取出水印信息。整个流程无需特定于语言的训练或工程。
关键创新:CodeMark-LLM的关键创新在于利用LLM的跨语言泛化能力,避免了传统方法中对特定语言的依赖。通过语义一致的转换,可以在不影响代码功能和可读性的前提下嵌入水印。此外,差分比较提取模块的设计使得水印提取过程更加简单高效。
关键设计:在语义一致嵌入模块中,关键在于如何选择合适的转换方式,以保证代码的功能和可读性不受影响。这需要LLM具备良好的代码理解能力和生成能力。在差分比较提取模块中,关键在于如何准确地识别出所应用的转换,这需要对代码进行细致的分析和比较。具体的参数设置和网络结构取决于所使用的LLM模型。
🖼️ 关键图片

📊 实验亮点
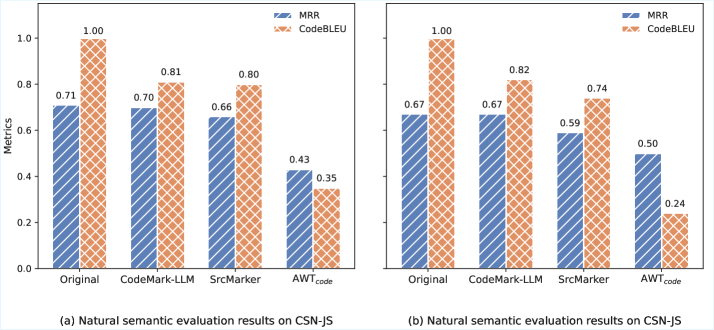
实验结果表明,CodeMark-LLM在多种编程语言(包括Python, Java, C++等)上都取得了良好的效果。在抵抗各种攻击(例如代码混淆、代码删除等)方面,CodeMark-LLM表现出较强的鲁棒性。与现有的水印技术相比,CodeMark-LLM在水印嵌入容量、提取准确率和抗攻击能力等方面都有显著提升。具体性能数据未知,但论文强调了其优越性。
🎯 应用场景
CodeMark-LLM可应用于软件版权保护、代码溯源、恶意代码检测等领域。通过在开源代码中嵌入水印,可以追踪代码的来源和使用情况,防止未经授权的复制和分发。此外,该技术还可以用于检测恶意代码,通过分析代码中的水印信息,判断代码是否被篡改或恶意使用。未来,该技术有望成为软件安全领域的重要组成部分。
📄 摘要(原文)
The widespread use of large language models (LLMs) and open-source code has raised ethical and security concerns regarding the distribution and attribution of source code, including unauthorized redistribution, license violations, and misuse of code for malicious purposes. Watermarking has emerged as a promising solution for source attribution, but existing techniques rely heavily on hand-crafted transformation rules, abstract syntax tree (AST) manipulation, or task-specific training, limiting their scalability and generality across languages. Moreover, their robustness against attacks remains limited. To address these limitations, we propose CodeMark-LLM, an LLM-driven watermarking framework that embeds watermark into source code without compromising its semantics or readability. CodeMark-LLM consists of two core components: (i) Semantically Consistent Embedding module that applies functionality-preserving transformations to encode watermark bits, and (ii) Differential Comparison Extraction module that identifies the applied transformations by comparing the original and watermarked code. Leveraging the cross-lingual generalization ability of LLM, CodeMark-LLM avoids language-specific engineering and training pipelines. Extensive experiments across diverse programming languages and attack scenarios demonstrate its robustness, effectiveness, and scalability.