Zero-Shot Large Language Model Agents for Fully Automated Radiotherapy Treatment Planning
作者: Dongrong Yang, Xin Wu, Yibo Xie, Xinyi Li, Qiuwen Wu, Jackie Wu, Yang Sheng
分类: physics.med-ph, cs.AI, cs.RO
发布日期: 2025-10-12
备注: Accepted for poster presentation at the NeurIPS 2025 Workshop on GenAI for Health: Potential, Trust, and Policy Compliance
💡 一句话要点
提出基于零样本大语言模型的全自动放射治疗计划方法,提升IMRT计划质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射治疗计划 大语言模型 零样本学习 自动计划 调强放射治疗 逆向优化 头颈癌
📋 核心要点
- 手动放射治疗计划耗时且依赖专家经验,难以满足日益增长的癌症治疗需求,自动化是必然趋势。
- 利用大语言模型作为智能体,直接与治疗计划系统交互,通过迭代优化约束条件,实现自动逆向治疗计划。
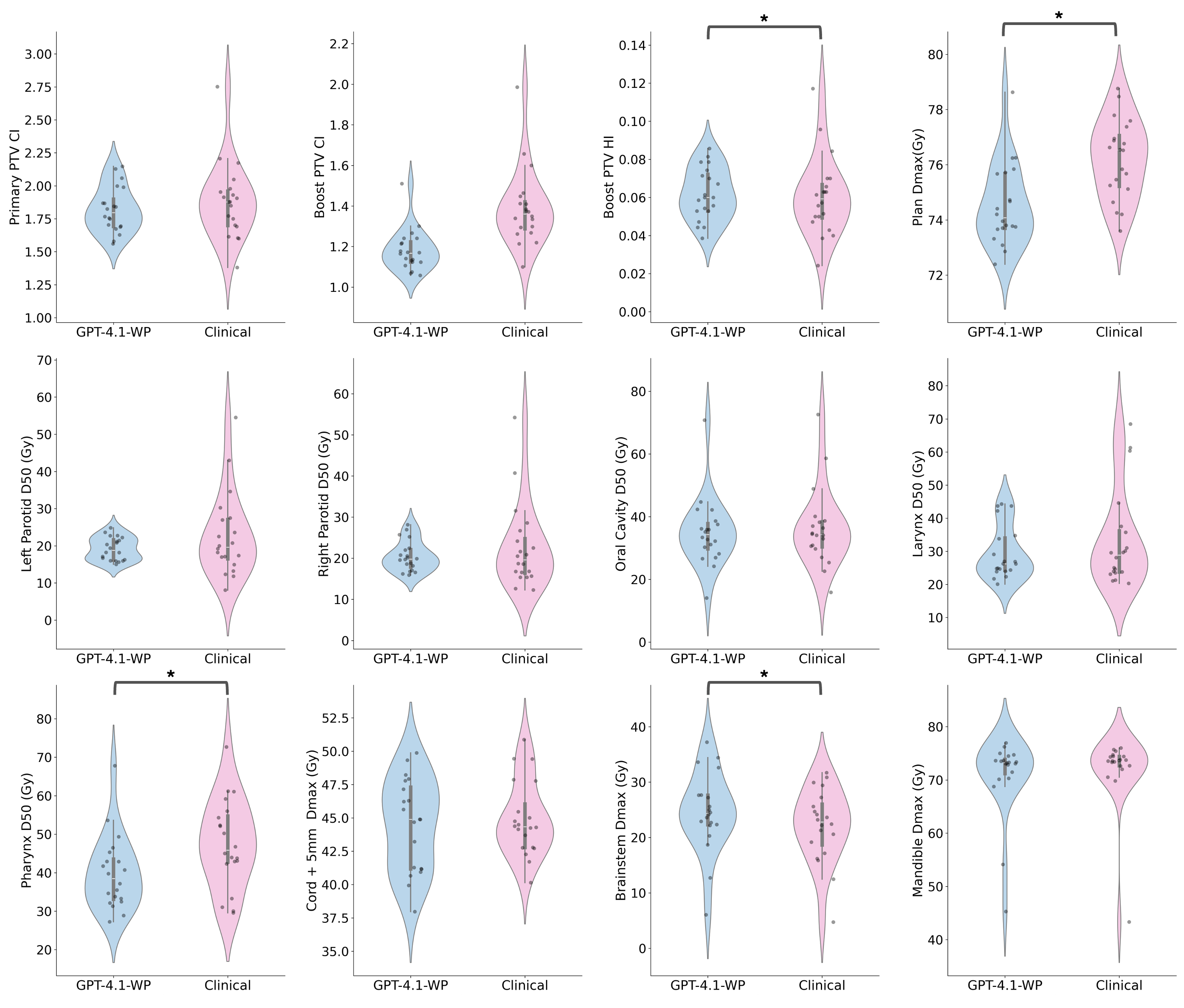
- 实验表明,该方法在头颈癌病例中,实现了与临床计划相当的危及器官保护,并改善了热点控制和适形性。
📝 摘要(中文)
放射治疗计划是一个迭代且依赖专业知识的过程,癌症病例的日益增加使得依赖手动计划变得难以为继,因此自动化需求迫切。本研究提出了一种利用基于大语言模型(LLM)的智能体来指导调强放射治疗(IMRT)逆向治疗计划的工作流程。该LLM智能体直接与临床治疗计划系统(TPS)交互,迭代地提取中间计划状态并提出新的约束值来指导逆向优化。智能体的决策过程基于当前的观察和之前的优化尝试及评估,从而实现动态的策略改进。计划过程在零样本推理设置中进行,LLM在没有事先接触手动生成的治疗计划的情况下运行,并且没有经过任何微调或特定于任务的训练。在二十个头颈癌病例中,LLM生成的计划与临床手动计划进行了评估,分析并报告了关键的剂量学终点。LLM生成的计划在实现与临床计划相当的危及器官(OAR)保护的同时,表现出更好的热点控制(Dmax:106.5% vs. 108.8%)和更高的适形性(boost PTV的适形指数:1.18 vs. 1.39;primary PTV的适形指数:1.82 vs. 1.88)。这项研究证明了在商业TPS中,零样本、LLM驱动的工作流程用于自动IMRT治疗计划的可行性。所提出的方法提供了一种通用且临床上适用的解决方案,可以减少计划的变异性,并支持更广泛地采用基于AI的计划策略。
🔬 方法详解
问题定义:放射治疗计划,特别是调强放射治疗(IMRT)的逆向计划,是一个复杂且迭代的过程,需要放射肿瘤学家和物理师的专业知识。手动计划耗时且容易受到人为因素的影响,导致计划质量的变异性。现有方法通常需要大量手动生成的训练数据或针对特定任务的微调,泛化能力有限。
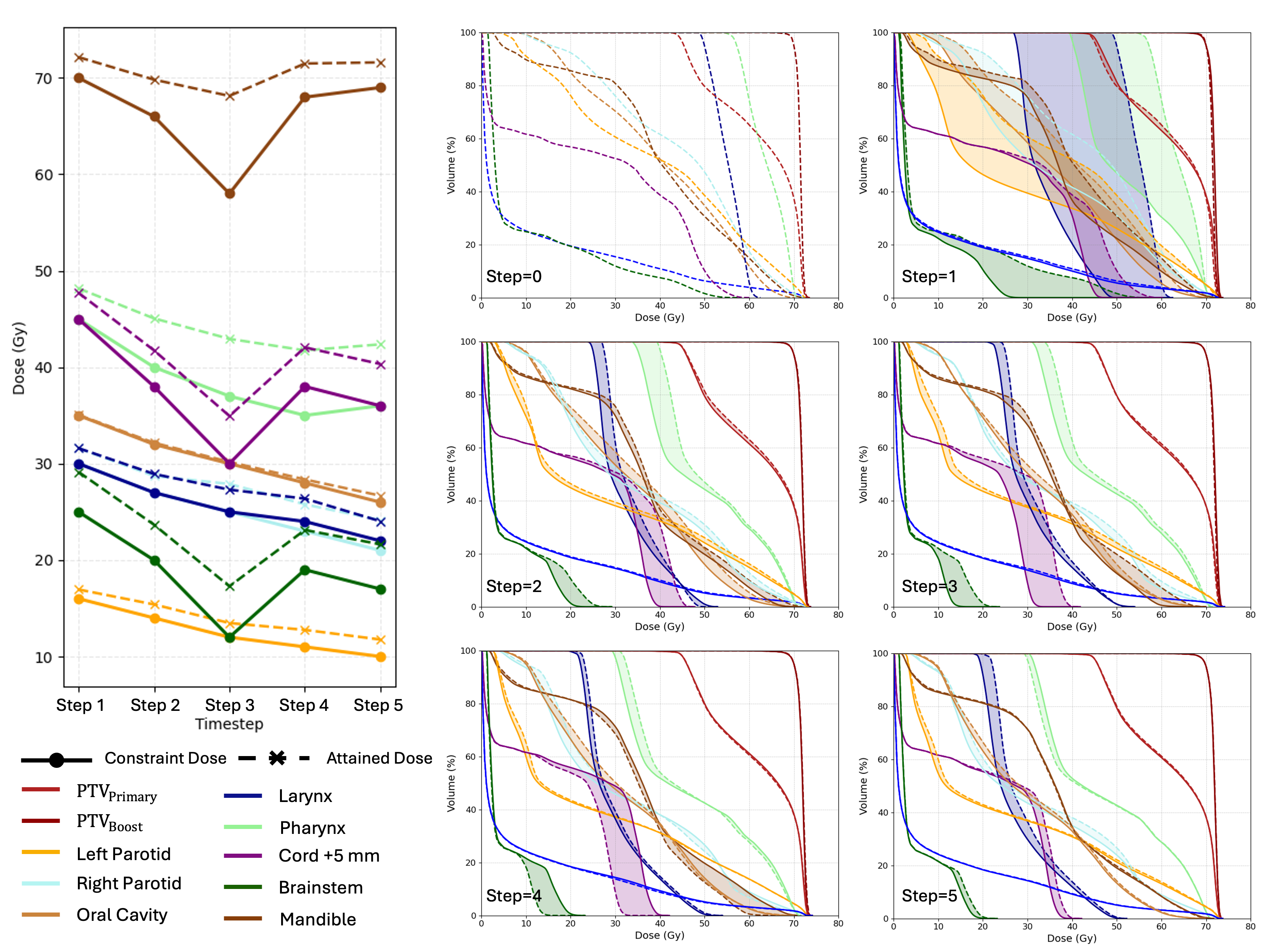
核心思路:利用大语言模型(LLM)的强大推理和决策能力,将其作为一个智能体,直接与临床治疗计划系统(TPS)交互。LLM通过观察当前的计划状态,并根据历史优化经验,动态地调整约束条件,指导逆向优化过程。这种方法无需预先训练或微调,即可实现零样本的自动计划。
技术框架:整体流程包括以下几个主要阶段:1)LLM智能体初始化,加载必要的知识和规则;2)智能体与TPS交互,提取当前计划状态(如剂量分布、DVH等);3)智能体根据当前状态和历史优化记录,生成新的约束条件建议;4)TPS根据智能体的建议进行逆向优化,生成新的计划;5)智能体评估新计划的质量,并更新优化策略;6)重复步骤2-5,直到满足预设的终止条件。
关键创新:该方法最重要的创新点在于利用零样本学习的方式,将LLM应用于放射治疗计划。与传统的监督学习方法不同,该方法无需大量手动生成的训练数据,即可实现自动计划。此外,该方法通过LLM的动态决策能力,实现了对优化过程的自适应调整,提高了计划的质量和效率。
关键设计:LLM的选择至关重要,需要选择具有较强推理和决策能力的LLM。约束条件的生成策略需要精心设计,以保证优化过程的稳定性和效率。此外,需要定义合适的奖励函数,以引导LLM朝着期望的方向优化计划。具体的参数设置和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于零样本LLM的自动计划方法在头颈癌病例中取得了与临床手动计划相当甚至更优的结果。具体而言,在危及器官保护方面,LLM生成的计划与临床计划相当;在热点控制方面,LLM计划的Dmax为106.5%,优于临床计划的108.8%;在适形性方面,LLM计划的boost PTV适形指数为1.18,优于临床计划的1.39,primary PTV适形指数为1.82,略优于临床计划的1.88。
🎯 应用场景
该研究成果可应用于临床放射治疗计划的自动化,减少计划时间和人为误差,提高计划质量和一致性。尤其是在资源有限的医疗机构,可以减轻放射肿瘤学家的工作负担,使更多患者受益于高质量的放射治疗。未来,该技术有望推广到其他类型的放射治疗计划,并与其他AI技术相结合,实现更智能化的治疗方案。
📄 摘要(原文)
Radiation therapy treatment planning is an iterative, expertise-dependent process, and the growing burden of cancer cases has made reliance on manual planning increasingly unsustainable, underscoring the need for automation. In this study, we propose a workflow that leverages a large language model (LLM)-based agent to navigate inverse treatment planning for intensity-modulated radiation therapy (IMRT). The LLM agent was implemented to directly interact with a clinical treatment planning system (TPS) to iteratively extract intermediate plan states and propose new constraint values to guide inverse optimization. The agent's decision-making process is informed by current observations and previous optimization attempts and evaluations, allowing for dynamic strategy refinement. The planning process was performed in a zero-shot inference setting, where the LLM operated without prior exposure to manually generated treatment plans and was utilized without any fine-tuning or task-specific training. The LLM-generated plans were evaluated on twenty head-and-neck cancer cases against clinical manual plans, with key dosimetric endpoints analyzed and reported. The LLM-generated plans achieved comparable organ-at-risk (OAR) sparing relative to clinical plans while demonstrating improved hot spot control (Dmax: 106.5% vs. 108.8%) and superior conformity (conformity index: 1.18 vs. 1.39 for boost PTV; 1.82 vs. 1.88 for primary PTV). This study demonstrates the feasibility of a zero-shot, LLM-driven workflow for automated IMRT treatment planning in a commercial TPS. The proposed approach provides a generalizable and clinically applicable solution that could reduce planning variability and support broader adoption of AI-based planning strategies.