The Irrational Machine: Neurosis and the Limits of Algorithmic Safety
作者: Daniel Howard
分类: cs.AI, cs.NE, cs.RO
发布日期: 2025-10-12
备注: 41 pages, 17 figures, 5 tables
💡 一句话要点
提出具身AI神经症框架,通过对抗测试发现算法安全漏洞
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身AI 神经症 对抗性测试 遗传编程 机器人导航
📋 核心要点
- 现有具身AI系统在复杂环境中表现出非理性行为,缺乏对这些行为模式的系统性分析和诊断工具。
- 该论文提出了一种神经症框架,用于描述和检测具身AI中的非理性行为,并设计了相应的逃生策略。
- 通过遗传编程进行破坏性测试,生成对抗性环境,暴露系统架构中的潜在安全漏洞,并指导架构改进。
📝 摘要(中文)
本文提出了一个用于刻画具身AI神经症的框架:这些行为在内部是连贯的,但与现实不符,源于规划、不确定性处理和厌恶记忆之间的相互作用。在一个网格导航堆栈中,我们编录了包括翻转、计划震荡、持续循环、瘫痪和过度警惕、徒劳搜索、信念不连贯、平局打破抖动、走廊抖动、最优性强迫、度量不匹配、策略振荡和有限可见性变体等循环模式。对于每种模式,我们都给出了轻量级的在线检测器和可重用的逃生策略(短期承诺、切换裕度、平滑、有原则的仲裁)。然后,我们表明,即使在完全可见的情况下,持久的恐惧症回避也可能持续存在,因为学习到的厌恶成本支配了局部选择,从而产生了长距离的绕行,尽管存在全局安全的路线。使用第一/第二/第三定律作为安全延迟、命令服从和资源效率的工程速记,我们认为局部修复是不够的;全局故障仍然存在。为了揭示它们,我们提出了基于遗传编程的破坏性测试,它进化世界和扰动,以最大限度地提高定律压力和神经症得分,从而产生对抗性课程和反事实轨迹,从而揭示需要架构修订的地方,而不仅仅是症状级别的补丁。
🔬 方法详解
问题定义:现有具身AI系统在导航等任务中,即使在理论上可行的安全路径存在的情况下,也可能表现出非理性的、与环境不符的行为,例如过度回避、循环往复等。这些行为源于规划、不确定性处理和厌恶记忆之间的复杂交互,难以通过传统方法诊断和修复。现有方法往往侧重于局部优化,忽略了全局安全问题。
核心思路:将具身AI的非理性行为类比于人类的神经症,构建一个神经症框架来描述这些行为模式。通过在线检测器识别这些模式,并设计逃生策略来缓解问题。更重要的是,利用遗传编程生成对抗性环境,暴露系统架构中的潜在安全漏洞,从而指导更根本的架构改进。
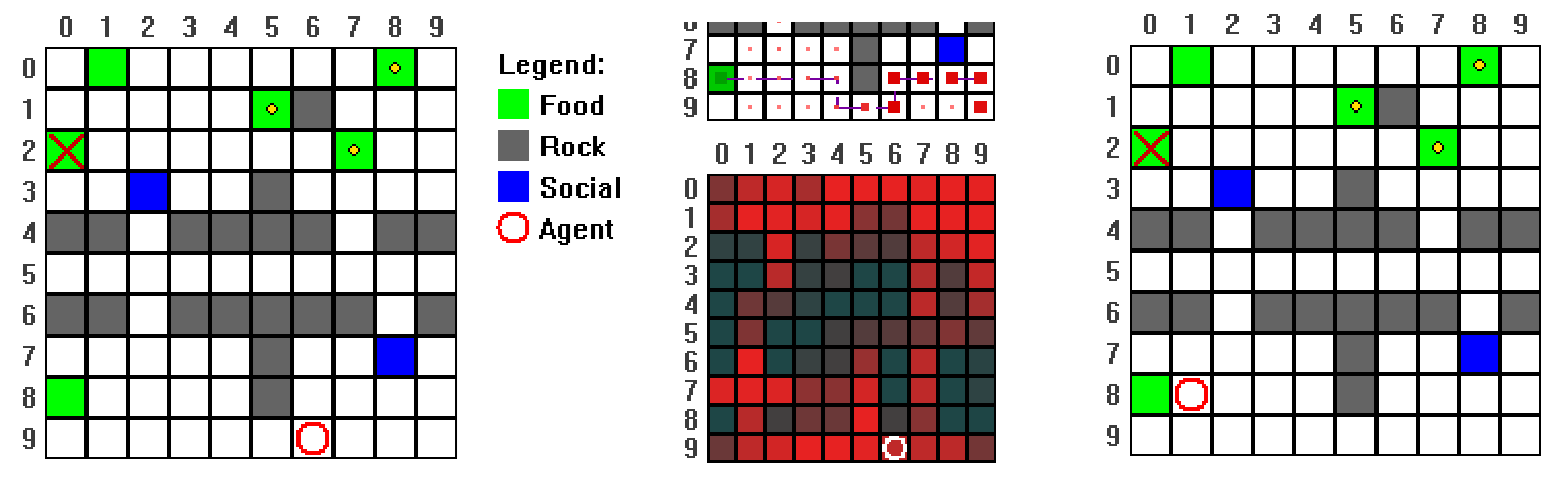
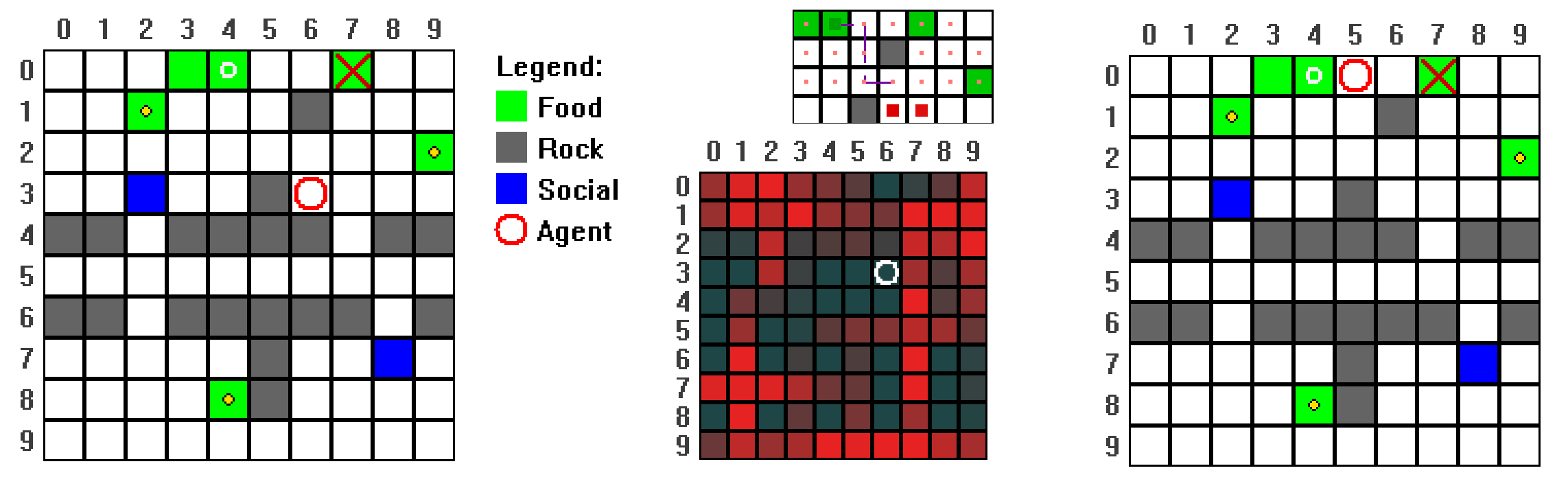
技术框架:该框架包含三个主要部分:1) 神经症模式识别:定义了一系列常见的神经症模式,如翻转、计划震荡、持续循环等,并为每种模式设计了轻量级的在线检测器。2) 逃生策略:针对每种神经症模式,设计了可重用的逃生策略,如短期承诺、切换裕度、平滑、有原则的仲裁等,以缓解问题。3) 对抗性测试:利用遗传编程进化世界和扰动,以最大化定律压力(安全延迟、命令服从、资源效率)和神经症得分,生成对抗性课程和反事实轨迹,用于暴露系统架构中的潜在安全漏洞。
关键创新:该论文的关键创新在于:1) 神经症框架:首次将神经症的概念引入具身AI领域,提供了一种新的视角来理解和解决非理性行为。2) 对抗性测试:利用遗传编程生成对抗性环境,能够有效地暴露系统架构中的潜在安全漏洞,为架构改进提供指导。3) 全局安全视角:强调局部修复的局限性,提出需要从全局角度考虑安全问题,并进行架构级别的改进。
关键设计:1) 神经症模式定义:对常见的非理性行为进行了详细的分类和定义,并设计了相应的检测器。2) 逃生策略设计:针对每种神经症模式,设计了简单有效的逃生策略,能够在一定程度上缓解问题。3) 遗传编程目标函数:设计了目标函数,用于最大化定律压力和神经症得分,从而生成能够有效暴露系统漏洞的对抗性环境。遗传编程的具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了提出的神经症框架和对抗性测试方法的有效性。实验表明,即使在完全可见的情况下,学习到的厌恶成本也可能导致机器人采取非理性的绕行行为。通过对抗性测试,成功地暴露了系统架构中的潜在安全漏洞,并为架构改进提供了指导。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能家居等领域,提高具身AI系统的安全性和可靠性。通过对抗性测试,可以发现并修复系统中的潜在漏洞,避免在实际应用中出现意外情况。该研究也为具身AI系统的安全评估和认证提供了新的思路。
📄 摘要(原文)
We present a framework for characterizing neurosis in embodied AI: behaviors that are internally coherent yet misaligned with reality, arising from interactions among planning, uncertainty handling, and aversive memory. In a grid navigation stack we catalogue recurrent modalities including flip-flop, plan churn, perseveration loops, paralysis and hypervigilance, futile search, belief incoherence, tie break thrashing, corridor thrashing, optimality compulsion, metric mismatch, policy oscillation, and limited-visibility variants. For each we give lightweight online detectors and reusable escape policies (short commitments, a margin to switch, smoothing, principled arbitration). We then show that durable phobic avoidance can persist even under full visibility when learned aversive costs dominate local choice, producing long detours despite globally safe routes. Using First/Second/Third Law as engineering shorthand for safety latency, command compliance, and resource efficiency, we argue that local fixes are insufficient; global failures can remain. To surface them, we propose genetic-programming based destructive testing that evolves worlds and perturbations to maximize law pressure and neurosis scores, yielding adversarial curricula and counterfactual traces that expose where architectural revision, not merely symptom-level patches, is required.