DRIFT: Decompose, Retrieve, Illustrate, then Formalize Theorems
作者: Meiru Zhang, Philipp Borchert, Milan Gritta, Gerasimos Lampouras
分类: cs.AI, cs.CL, cs.IR, cs.SC
发布日期: 2025-10-12 (更新: 2025-10-20)
💡 一句话要点
DRIFT:通过分解、检索、示例和形式化定理,提升LLM的自动形式化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动形式化 定理证明 大型语言模型 知识检索 数学推理
📋 核心要点
- 现有方法直接使用复杂非形式化数学陈述检索,忽略了语句复杂性和上下文不足的问题。
- DRIFT框架将非形式化数学陈述分解为子组件,并检索相关示例定理,从而实现更精确的检索。
- 实验表明,DRIFT在多个基准测试中显著提升了前提检索的F1得分和形式化性能,尤其是在分布外数据上。
📝 摘要(中文)
大型语言模型(LLM)在自动形式化数学陈述以进行定理证明方面仍然面临重大挑战。LLM难以识别和利用必要的数学知识及其在Lean等语言中的形式化表示。现有的检索增强自动形式化方法直接使用非形式化陈述查询外部库,但忽略了一个根本限制:非形式化数学陈述通常很复杂,并且对底层数学概念提供的上下文有限。为了解决这个问题,我们引入了DRIFT,这是一个新颖的框架,它使LLM能够将非形式化数学陈述分解为更小、更易于处理的“子组件”。这有助于有针对性地从Mathlib等数学库中检索前提。此外,DRIFT检索说明性定理,以帮助模型更有效地在形式化任务中使用前提。我们在不同的基准测试(ProofNet、ConNF和MiniF2F-test)中评估了DRIFT,发现它始终改进前提检索,与ProofNet上的DPR基线相比,F1得分几乎翻了一番。值得注意的是,DRIFT在分布外的ConNF基准测试中表现出强大的性能,使用GPT-4.1和DeepSeek-V3.1分别实现了37.14%和42.25%的BEq+@10改进。我们的分析表明,数学自动形式化中的检索有效性在很大程度上取决于模型特定的知识边界,突出了对与每个模型的能力相一致的自适应检索策略的需求。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在数学定理自动形式化过程中,由于非形式化数学陈述的复杂性和缺乏上下文信息,导致检索相关数学知识困难的问题。现有方法直接使用原始语句进行检索,效果不佳。
核心思路:DRIFT的核心思路是将复杂的非形式化数学陈述分解为更小、更易于理解的子组件,然后针对这些子组件进行检索。此外,DRIFT还检索与子组件相关的示例定理,以帮助模型更好地理解和利用检索到的知识。这种分解和示例引导的检索策略旨在提高检索的准确性和有效性。
技术框架:DRIFT框架包含以下主要阶段:1) 分解(Decompose):将非形式化数学陈述分解为更小的子组件。2) 检索(Retrieve):使用分解后的子组件查询数学库(如Mathlib)以检索相关的前提和定理。3) 示例(Illustrate):检索与子组件相关的示例定理,为模型提供更直观的理解。4) 形式化(Formalize):利用检索到的前提和示例定理,将原始的非形式化陈述形式化为Lean等形式化语言。
关键创新:DRIFT的关键创新在于其分解和示例引导的检索策略。与直接使用原始语句进行检索的方法相比,DRIFT能够更精确地定位相关的数学知识。通过分解,模型可以专注于语句的各个组成部分,从而更好地理解其含义。示例定理的引入则为模型提供了更直观的理解,帮助其更好地利用检索到的知识。
关键设计:论文中没有明确提及具体的参数设置、损失函数或网络结构等技术细节。但是,分解策略的选择(如何将原始语句分解为子组件)以及示例定理的检索策略(如何选择与子组件相关的示例定理)是DRIFT框架中的关键设计选择。这些策略的选择会直接影响检索的准确性和有效性。
🖼️ 关键图片
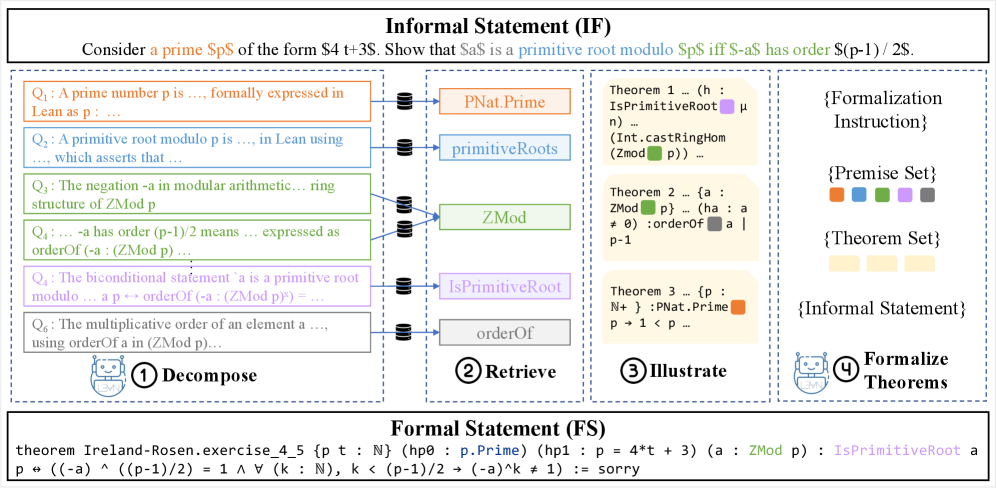
📊 实验亮点
DRIFT在ProofNet基准测试中,前提检索的F1得分几乎是DPR基线的两倍。在分布外的ConNF基准测试中,使用GPT-4.1和DeepSeek-V3.1分别实现了37.14%和42.25%的BEq+@10改进。这些结果表明,DRIFT能够显著提高数学自动形式化的性能,尤其是在处理复杂和分布外数据时。
🎯 应用场景
DRIFT框架可应用于自动化定理证明、数学知识库构建、数学教育等领域。通过提高自动形式化的准确性和效率,可以加速数学研究的进程,并降低数学学习的门槛。该方法还有潜力应用于其他需要知识检索和推理的领域。
📄 摘要(原文)
Automating the formalization of mathematical statements for theorem proving remains a major challenge for Large Language Models (LLMs). LLMs struggle to identify and utilize the prerequisite mathematical knowledge and its corresponding formal representation in languages like Lean. Current retrieval-augmented autoformalization methods query external libraries using the informal statement directly, but overlook a fundamental limitation: informal mathematical statements are often complex and offer limited context on the underlying math concepts. To address this, we introduce DRIFT, a novel framework that enables LLMs to decompose informal mathematical statements into smaller, more tractable ''sub-components''. This facilitates targeted retrieval of premises from mathematical libraries such as Mathlib. Additionally, DRIFT retrieves illustrative theorems to help models use premises more effectively in formalization tasks. We evaluate DRIFT across diverse benchmarks (ProofNet, ConNF, and MiniF2F-test) and find that it consistently improves premise retrieval, nearly doubling the F1 score compared to the DPR baseline on ProofNet. Notably, DRIFT demonstrates strong performance on the out-of-distribution ConNF benchmark, with BEq+@10 improvements of 37.14% and 42.25% using GPT-4.1 and DeepSeek-V3.1, respectively. Our analysis shows that retrieval effectiveness in mathematical autoformalization depends heavily on model-specific knowledge boundaries, highlighting the need for adaptive retrieval strategies aligned with each model's capabilities.