RAG-IGBench: Innovative Evaluation for RAG-based Interleaved Generation in Open-domain Question Answering
作者: Rongyang Zhang, Yuqing Huang, Chengqiang Lu, Qimeng Wang, Yan Gao, Yi Wu, Yao Hu, Yin Xu, Wei Wang, Hao Wang, Enhong Chen
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-10-11
备注: 26 pages, 6 figures, NeurIPS 2025 D&B Track poster
🔗 代码/项目: GITHUB
💡 一句话要点
RAG-IGBench:用于开放域问答中基于RAG的交错生成任务的创新评估基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 交错生成 多模态学习 开放域问答 评估基准
📋 核心要点
- 现有方法在评估交错图像-文本生成任务时,缺乏能够充分评估组合模态复杂性的有效基准和评估指标。
- RAG-IGBench通过集成多模态大型语言模型与检索机制,利用社交平台内容,生成连贯的多模态交错内容。
- 实验表明,在RAG-IGBench上微调的模型在多个基准测试中表现出性能提升,验证了数据集的质量和实用性。
📝 摘要(中文)
在实际场景中,为用户查询提供视觉增强的响应可以显著提高理解和记忆力,突显了交错图像-文本生成的重要价值。尽管最近取得了进展,例如在单个Transformer架构中统一文本和图像处理的视觉自回归模型,但生成高质量的交错内容仍然具有挑战性。此外,对这些交错序列的评估在很大程度上仍未得到充分探索,现有的基准通常受到单模态指标的限制,无法充分评估组合图像-文本输出的复杂性。为了解决这些问题,我们提出了RAG-IGBench,这是一个专门用于评估开放域问答中基于检索增强生成(RAG-IG)的交错生成任务的综合基准。RAG-IG集成了多模态大型语言模型(MLLM)与检索机制,使模型能够访问外部图像-文本信息,以生成连贯的多模态内容。与以往的数据集不同,RAG-IGBench借鉴了社交平台上最新的公开内容,并引入了创新的评估指标,用于衡量文本和图像的质量以及它们的一致性。通过在RAG-IGBench上对最先进的MLLM(包括开源和专有模型)进行广泛的实验,我们提供了深入的分析,检验了这些模型的能力和局限性。此外,我们通过证明我们的评估指标与人类评估的高度相关性来验证它们。在RAG-IGBench的训练集上进行微调的模型在多个基准测试中表现出改进的性能,证实了我们数据集的质量和实用性。
🔬 方法详解
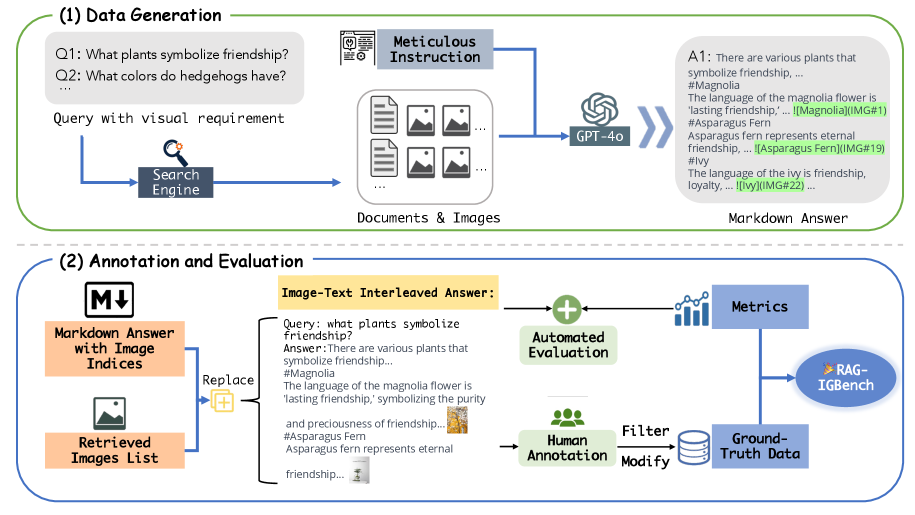
问题定义:论文旨在解决开放域问答中,如何有效评估基于检索增强生成(RAG)的交错图像-文本生成任务的问题。现有方法主要依赖于单模态指标,无法充分评估图像和文本之间的关联性、一致性以及整体质量,缺乏针对交错生成内容的综合评估基准。
核心思路:论文的核心思路是构建一个专门用于评估RAG-IG任务的基准数据集RAG-IGBench,并设计相应的评估指标,以更全面地衡量生成内容的质量。通过集成多模态大型语言模型(MLLM)和检索机制,模型可以访问外部图像-文本信息,从而生成更连贯、更丰富的多模态内容。
技术框架:RAG-IGBench的整体框架包含以下几个关键部分:1) 数据收集:从社交平台收集最新的公开图像-文本数据,构建数据集。2) 模型集成:将多模态大型语言模型(MLLM)与检索机制相结合,实现RAG-IG。3) 内容生成:利用RAG-IG模型生成交错的图像-文本内容。4) 评估指标设计:设计新的评估指标,用于衡量文本和图像的质量以及它们之间的一致性。5) 实验评估:在RAG-IGBench上对不同的MLLM进行实验评估,分析其性能和局限性。
关键创新:论文的关键创新在于:1) 提出了RAG-IGBench,一个专门用于评估RAG-IG任务的基准数据集。2) 设计了创新的评估指标,能够更全面地衡量交错图像-文本内容的质量和一致性。3) 将多模态大型语言模型与检索机制相结合,实现了更有效的RAG-IG。与现有方法的本质区别在于,RAG-IGBench关注于交错生成内容的综合评估,而不仅仅是单模态的评估。
关键设计:RAG-IGBench的关键设计包括:1) 数据集的构建:从社交平台收集数据,保证了数据的多样性和时效性。2) 评估指标的设计:综合考虑了文本质量、图像质量以及图像-文本一致性,设计了多个评估指标。3) 模型选择:选择了多个最先进的MLLM进行实验评估,包括开源和专有模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在RAG-IGBench上微调的模型在多个基准测试中表现出性能提升,验证了数据集的质量和实用性。此外,论文还验证了评估指标与人类评估的高度相关性,证明了评估指标的有效性。通过对多个最先进的MLLM进行实验评估,论文深入分析了这些模型在RAG-IG任务中的能力和局限性。
🎯 应用场景
该研究成果可应用于多种场景,例如智能客服、教育辅助、社交媒体内容生成等。通过生成高质量的交错图像-文本内容,可以提升用户理解和记忆,改善用户体验。未来,该研究可以进一步扩展到其他多模态生成任务,例如视频-文本生成、音频-文本生成等,具有广阔的应用前景。
📄 摘要(原文)
In real-world scenarios, providing user queries with visually enhanced responses can considerably benefit understanding and memory, underscoring the great value of interleaved image-text generation. Despite recent progress, like the visual autoregressive model that unifies text and image processing in a single transformer architecture, generating high-quality interleaved content remains challenging. Moreover, evaluations of these interleaved sequences largely remain underexplored, with existing benchmarks often limited by unimodal metrics that inadequately assess the intricacies of combined image-text outputs. To address these issues, we present RAG-IGBench, a thorough benchmark designed specifically to evaluate the task of Interleaved Generation based on Retrieval-Augmented Generation (RAG-IG) in open-domain question answering. RAG-IG integrates multimodal large language models (MLLMs) with retrieval mechanisms, enabling the models to access external image-text information for generating coherent multimodal content. Distinct from previous datasets, RAG-IGBench draws on the latest publicly available content from social platforms and introduces innovative evaluation metrics that measure the quality of text and images, as well as their consistency. Through extensive experiments with state-of-the-art MLLMs (both open-source and proprietary) on RAG-IGBench, we provide an in-depth analysis examining the capabilities and limitations of these models. Additionally, we validate our evaluation metrics by demonstrating their high correlation with human assessments. Models fine-tuned on RAG-IGBench's training set exhibit improved performance across multiple benchmarks, confirming both the quality and practical utility of our dataset. Our benchmark is available at https://github.com/USTC-StarTeam/RAG-IGBench.