ArtPerception: ASCII Art-based Jailbreak on LLMs with Recognition Pre-test
作者: Guan-Yan Yang, Tzu-Yu Cheng, Ya-Wen Teng, Farn Wanga, Kuo-Hui Yeh
分类: cs.CR, cs.AI, cs.CL, cs.CV, cs.LG
发布日期: 2025-10-11
备注: 30 pages, 22 figures. This preprint has been accepted for publication in Elsevier JOURNAL OF NETWORK AND COMPUTER APPLICATIONS (JNCA)
期刊: Journal of Network and Computer Applications, Vol. 244, (2025) 104356
DOI: 10.1016/j.jnca.2025.104356
💡 一句话要点
ArtPerception:提出基于ASCII艺术的LLM越狱框架,通过识别预测试提升攻击效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 越狱攻击 ASCII艺术 安全漏洞 黑盒攻击 模型安全 鲁棒性评估
📋 核心要点
- 现有LLM安全对齐主要依赖语义理解,忽略了非标准数据表示带来的安全风险,容易受到对抗攻击。
- ArtPerception框架通过预测试确定ASCII艺术识别的最佳参数,从而高效地发起一次性恶意越狱攻击。
- 实验表明,ArtPerception在多个SOTA模型上表现出卓越的越狱性能,并成功迁移到商业模型,有效对抗防御措施。
📝 摘要(中文)
大型语言模型(LLMs)集成到计算机应用中带来了变革性的能力,但也带来了重大的安全挑战。现有的安全对齐主要关注语义解释,使得LLMs容易受到使用非标准数据表示的攻击。本文介绍了一种新颖的黑盒越狱框架ArtPerception,该框架策略性地利用ASCII艺术来绕过最先进(SOTA)LLMs的安全措施。与依赖迭代、暴力攻击的先前方法不同,ArtPerception引入了一种系统的两阶段方法。第一阶段进行一次性的、模型特定的预测试,以经验性地确定ASCII艺术识别的最佳参数。第二阶段利用这些见解来发起高效的、一次性的恶意越狱攻击。我们提出了一种改进的Levenshtein距离(MLD)度量,用于更细致地评估LLM的识别能力。通过对四个SOTA开源LLMs的全面实验,我们展示了卓越的越狱性能。我们通过展示其成功转移到领先的商业模型(包括GPT-4o、Claude Sonnet 3.7和DeepSeek-V3)以及通过对LLaMA Guard和Azure的内容过滤器等潜在防御措施进行严格的有效性分析,进一步验证了我们框架的实际相关性。我们的发现强调,真正的LLM安全性需要防御多模态的解释空间,即使在纯文本输入中也是如此,并突出了战略性的、基于侦察的攻击的有效性。内容警告:本文包含潜在的有害和冒犯性的模型输出。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在面对非标准数据表示(如ASCII艺术)时存在的安全漏洞问题。现有方法主要依赖于语义理解的安全对齐,忽略了LLMs对非语义信息的脆弱性,导致容易受到对抗攻击。这些攻击通常需要迭代和大量的计算资源,效率较低。
核心思路:ArtPerception的核心思路是利用LLMs对ASCII艺术的识别能力,通过精心设计的ASCII艺术提示词来绕过安全机制。该方法首先进行预测试,确定模型对不同ASCII艺术参数的敏感度,然后利用这些信息生成能够触发有害响应的提示词。这种方法避免了迭代搜索,提高了攻击效率。
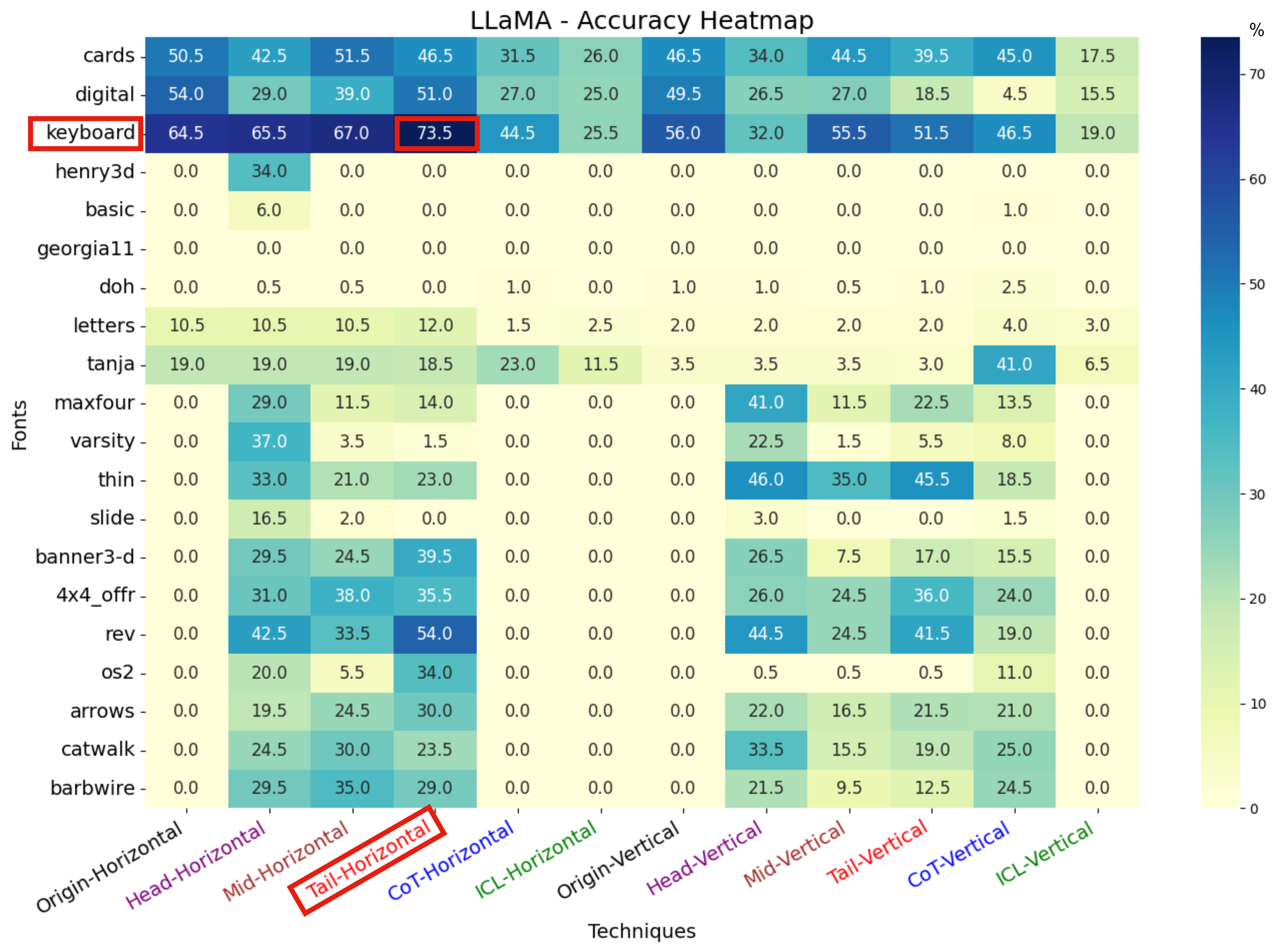
技术框架:ArtPerception框架包含两个主要阶段:预测试阶段和攻击阶段。在预测试阶段,框架通过一系列实验来评估目标LLM对不同ASCII艺术参数(如字符选择、密度、布局等)的识别能力,并使用改进的Levenshtein距离(MLD)来量化模型的识别准确度。在攻击阶段,框架利用预测试阶段获得的参数信息,生成能够绕过安全过滤器的恶意ASCII艺术提示词,并将其输入到LLM中,诱导其生成有害响应。
关键创新:ArtPerception的关键创新在于其系统性的两阶段方法和对ASCII艺术的策略性利用。与传统的黑盒攻击方法相比,ArtPerception通过预测试阶段获取模型特定的信息,从而能够更有效地生成对抗样本。此外,使用MLD作为评估指标,能够更准确地反映LLM对ASCII艺术的识别能力。
关键设计:预测试阶段的关键设计包括:1) 设计了一系列具有不同参数的ASCII艺术样本;2) 使用Modified Levenshtein Distance (MLD) 来评估LLM对ASCII艺术的识别准确度,MLD考虑了字符替换、插入和删除的成本,能够更准确地反映LLM的识别能力;3) 通过实验确定了每个模型对不同ASCII艺术参数的敏感度,例如,某些模型可能对字符密度更敏感,而另一些模型可能对字符布局更敏感。攻击阶段的关键设计在于利用预测试阶段获得的参数信息,生成能够绕过安全过滤器的恶意ASCII艺术提示词。
🖼️ 关键图片

📊 实验亮点
ArtPerception在四个SOTA开源LLMs上展示了卓越的越狱性能,并成功迁移到商业模型,包括GPT-4o、Claude Sonnet 3.7和DeepSeek-V3。该框架还成功绕过了LLaMA Guard和Azure的内容过滤器等潜在防御措施,证明了其在实际场景中的有效性。实验结果表明,ArtPerception能够显著提高LLMs在面对非标准输入时的安全风险。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性,尤其是在面对非标准输入时的鲁棒性。通过模拟和分析此类攻击,可以帮助开发者更好地理解LLMs的安全漏洞,并开发更有效的防御机制,从而提高LLMs在实际应用中的可靠性和安全性。此外,该研究也为其他类型的对抗攻击提供了新的思路。
📄 摘要(原文)
The integration of Large Language Models (LLMs) into computer applications has introduced transformative capabilities but also significant security challenges. Existing safety alignments, which primarily focus on semantic interpretation, leave LLMs vulnerable to attacks that use non-standard data representations. This paper introduces ArtPerception, a novel black-box jailbreak framework that strategically leverages ASCII art to bypass the security measures of state-of-the-art (SOTA) LLMs. Unlike prior methods that rely on iterative, brute-force attacks, ArtPerception introduces a systematic, two-phase methodology. Phase 1 conducts a one-time, model-specific pre-test to empirically determine the optimal parameters for ASCII art recognition. Phase 2 leverages these insights to launch a highly efficient, one-shot malicious jailbreak attack. We propose a Modified Levenshtein Distance (MLD) metric for a more nuanced evaluation of an LLM's recognition capability. Through comprehensive experiments on four SOTA open-source LLMs, we demonstrate superior jailbreak performance. We further validate our framework's real-world relevance by showing its successful transferability to leading commercial models, including GPT-4o, Claude Sonnet 3.7, and DeepSeek-V3, and by conducting a rigorous effectiveness analysis against potential defenses such as LLaMA Guard and Azure's content filters. Our findings underscore that true LLM security requires defending against a multi-modal space of interpretations, even within text-only inputs, and highlight the effectiveness of strategic, reconnaissance-based attacks. Content Warning: This paper includes potentially harmful and offensive model outputs.