When to Reason: Semantic Router for vLLM
作者: Chen Wang, Xunzhuo Liu, Yuhan Liu, Yue Zhu, Xiangxi Mo, Junchen Jiang, Huamin Chen
分类: cs.ET, cs.AI, cs.CL, eess.SY
发布日期: 2025-10-09
备注: 5 pages, excluding references and appendix. To be appeared at Workshop on ML for Systems at NeurIPS 2025, December 6, 2025 https://mlforsystems.org/
💡 一句话要点
提出基于语义路由的vLLM优化方案,提升推理效率与精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语义路由 推理优化 vLLM 效率提升
📋 核心要点
- 现有LLM推理方法对所有查询应用统一的推理模式,忽略了简单查询的需求,导致不必要的计算开销和延迟。
- 论文提出一种语义路由器,根据查询的语义内容判断是否需要复杂的推理模式,从而选择性地应用推理。
- 实验结果表明,该方法在保证精度的前提下,显著降低了推理延迟和token消耗,提升了LLM服务效率。
📝 摘要(中文)
大型语言模型(LLMs)通过思维链和推理时缩放等推理模式,在准确性方面取得了显著提高。然而,推理也带来了推理延迟和token使用方面的巨大成本,对环境和财务产生影响,而这对于许多简单的提示是不必要的。我们提出了一种语义路由器,它根据查询的推理需求对其进行分类,并仅在有益时才选择性地应用推理。我们的方法在MMLU-Pro基准测试中实现了10.2个百分点的准确率提升,同时与使用vLLM的直接推理相比,响应延迟降低了47.1%,token消耗降低了48.5%。这些结果表明,语义路由为在开源LLM服务系统中平衡准确性和效率提供了一种有效的机制。
🔬 方法详解
问题定义:现有的大型语言模型服务通常对所有输入查询采用相同的推理策略,即使对于简单的查询,也会进行复杂的推理过程,导致不必要的计算资源浪费和延迟增加。这对于资源受限的部署环境,例如边缘设备或高并发场景,是一个显著的痛点。
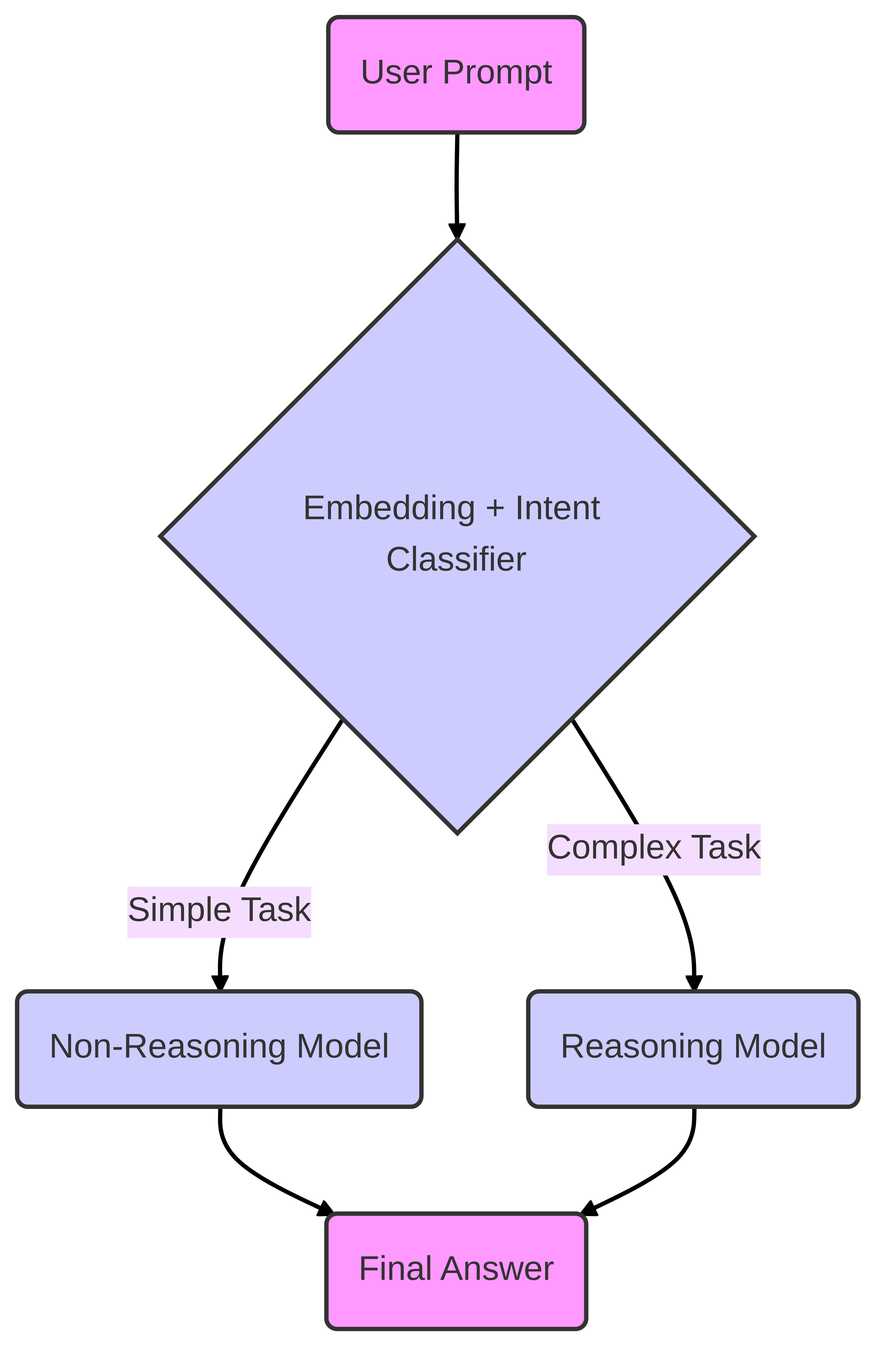
核心思路:论文的核心思路是引入一个语义路由器,该路由器能够根据输入查询的语义内容,判断是否需要进行复杂的推理过程。对于简单的查询,直接进行快速推理;对于需要复杂推理的查询,则采用更精细的推理策略。这样可以避免对所有查询都进行高成本的推理,从而提高整体的推理效率。
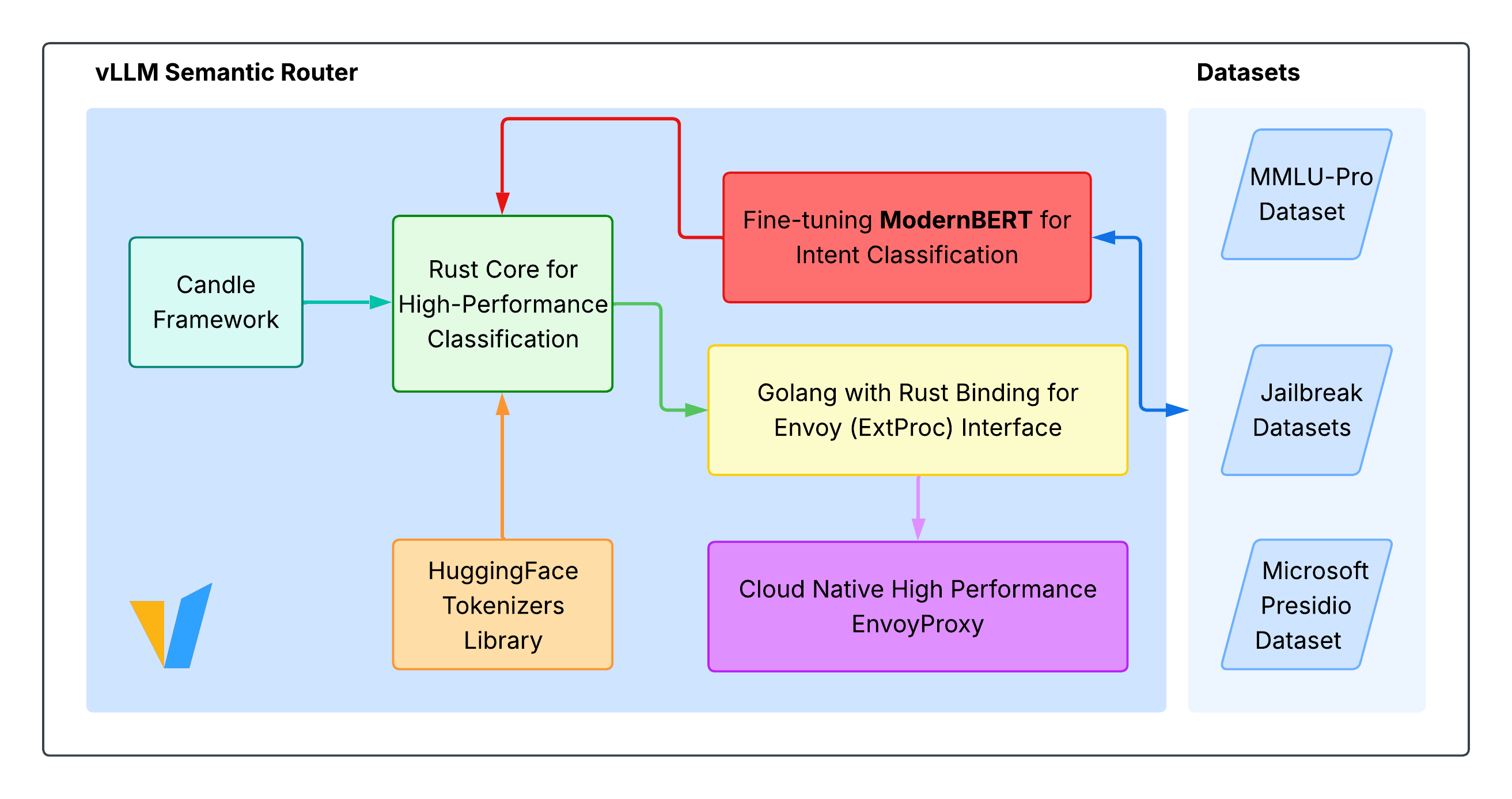
技术框架:整体框架包含两个主要模块:语义路由器和LLM推理引擎。语义路由器负责分析输入查询的语义信息,并根据预定义的规则或模型,判断是否需要进行复杂的推理。如果需要,则将查询传递给LLM推理引擎,采用如思维链等推理策略;否则,直接进行快速推理。整个流程旨在根据查询的复杂程度,动态地选择合适的推理路径。
关键创新:该论文的关键创新在于语义路由器的设计和应用。传统的LLM服务通常采用静态的推理策略,而该论文提出的语义路由器能够根据输入查询的语义信息,动态地选择合适的推理策略。这种动态选择机制能够有效地平衡推理精度和效率,从而提高整体的LLM服务性能。
关键设计:语义路由器的具体实现可以采用多种方法,例如基于规则的方法、基于机器学习的方法等。基于规则的方法需要人工定义一系列规则,用于判断查询的复杂程度。基于机器学习的方法则可以训练一个分类器,用于自动判断查询是否需要复杂的推理。此外,还可以采用一些优化技术,例如缓存机制,用于加速语义路由器的判断过程。
🖼️ 关键图片
📊 实验亮点
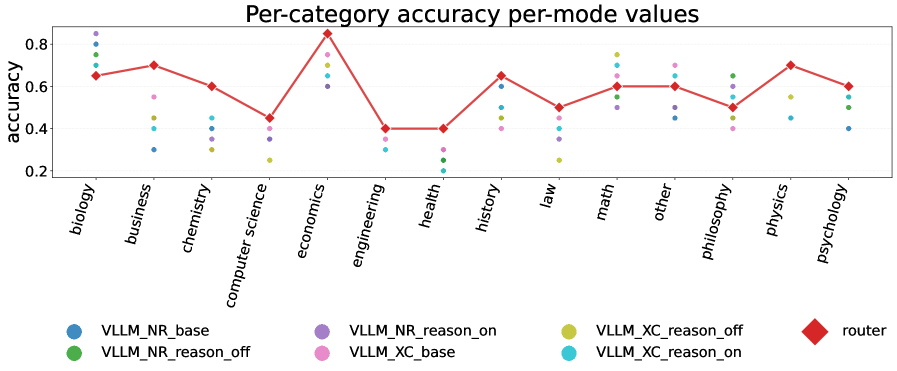
实验结果表明,该方法在MMLU-Pro基准测试中实现了10.2个百分点的准确率提升,同时与使用vLLM的直接推理相比,响应延迟降低了47.1%,token消耗降低了48.5%。这些数据充分证明了语义路由在平衡准确性和效率方面的有效性。
🎯 应用场景
该研究成果可广泛应用于各种需要高效LLM服务的场景,例如智能客服、搜索引擎、文本摘要等。通过语义路由,可以显著降低推理延迟和计算成本,提高用户体验,并降低部署和维护成本。未来,该技术还可以扩展到其他类型的AI模型,实现更智能化的资源管理和任务调度。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate substantial accuracy gains when augmented with reasoning modes such as chain-of-thought and inference-time scaling. However, reasoning also incurs significant costs in inference latency and token usage, with environmental and financial impacts, which are unnecessary for many simple prompts. We present a semantic router that classifies queries based on their reasoning requirements and selectively applies reasoning only when beneficial. Our approach achieves a 10.2 percentage point improvement in accuracy on the MMLU-Pro benchmark while reducing response latency by 47.1% and token consumption by 48.5% compared to direct inference with vLLM. These results demonstrate that semantic routing offers an effective mechanism for striking a balance between accuracy and efficiency in open-source LLM serving systems