Reading Between the Lines: Towards Reliable Black-box LLM Fingerprinting via Zeroth-order Gradient Estimation
作者: Shuo Shao, Yiming Li, Hongwei Yao, Yifei Chen, Yuchen Yang, Zhan Qin
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-10-08 (更新: 2026-01-21)
备注: This paper is accepeted by the ACM Web Conference (WWW) 2026
💡 一句话要点
提出ZeroPrint,通过零阶梯度估计实现可靠的黑盒LLM指纹识别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM指纹识别 黑盒攻击 零阶梯度估计 费舍尔信息理论 知识产权保护
📋 核心要点
- 现有黑盒LLM指纹识别方法依赖模型输出,丢失了模型参数的关键信息,导致指纹区分度不高。
- ZeroPrint通过零阶估计在黑盒环境中近似模型输入的梯度,利用费舍尔信息理论证明梯度包含更多指纹信息。
- ZeroPrint通过语义保留的词语替换模拟输入扰动,估计雅可比矩阵作为指纹,实验表明其优于现有方法。
📝 摘要(中文)
大型语言模型(LLM)的开发需要大量投资,使其成为有价值的知识产权,版权保护问题日益突出。LLM指纹识别技术应运而生,旨在通过提取模型固有的、独特的签名(即“指纹”),并将其与源模型的指纹进行比较,从而验证模型的来源,识别非法副本。然而,现有的黑盒指纹识别方法通常无法生成独特的LLM指纹。这种无效性源于黑盒方法通常依赖于模型输出,由于非线性函数的使用,模型输出会丢失关于模型独特参数的关键信息。为了解决这个问题,我们首先利用费舍尔信息理论正式证明,模型输入的梯度是比输出更具信息量的指纹识别特征。基于这一洞察,我们提出了一种名为ZeroPrint的新方法,该方法使用零阶估计在黑盒设置中近似这些信息丰富的梯度。ZeroPrint通过模拟语义保留的词语替换来模拟输入扰动,从而克服了将其应用于离散文本的挑战。此操作允许ZeroPrint将模型的雅可比矩阵估计为唯一的指纹。在标准基准上的实验表明,ZeroPrint实现了最先进的有效性和鲁棒性,显著优于现有的黑盒方法。
🔬 方法详解
问题定义:论文旨在解决黑盒场景下大型语言模型(LLM)的指纹识别问题。现有黑盒方法主要依赖模型输出,但由于非线性激活函数等操作,模型参数的独特性在输出中被弱化,导致指纹区分度不高,难以有效识别非法复制的模型。
核心思路:论文的核心思路是利用模型输入的梯度信息进行指纹识别。作者基于费舍尔信息理论证明,相比模型输出,模型输入的梯度包含了更多关于模型参数的独特信息。因此,通过估计模型输入的梯度,可以提取更具区分性的指纹。
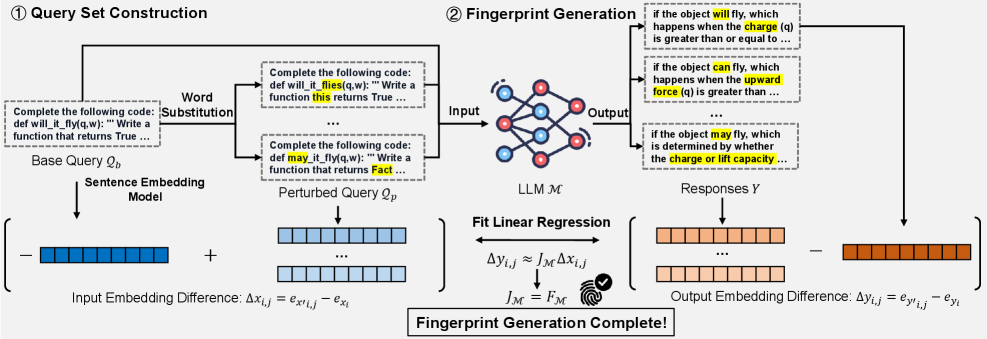
技术框架:ZeroPrint方法的整体框架如下: 1. 输入扰动:对输入文本进行语义保留的词语替换,生成多个扰动后的输入样本。 2. 零阶梯度估计:利用扰动后的输入样本和原始输入样本的模型输出,通过零阶估计方法近似计算模型输入的梯度(雅可比矩阵)。 3. 指纹提取:将估计得到的雅可比矩阵作为模型的指纹。 4. 指纹匹配:通过比较两个模型的指纹(雅可比矩阵)的相似度,判断是否存在模型复制关系。
关键创新:ZeroPrint的关键创新在于: 1. 利用梯度信息:首次将模型输入的梯度信息应用于黑盒LLM指纹识别,并从理论上证明了其有效性。 2. 零阶梯度估计:提出了一种基于语义保留词语替换的零阶梯度估计方法,解决了在离散文本输入下梯度计算的难题。
关键设计:ZeroPrint的关键设计包括: 1. 语义保留词语替换:使用同义词替换等方法,保证扰动后的输入样本在语义上与原始样本一致,避免影响模型输出的语义信息。 2. 扰动幅度控制:需要仔细控制词语替换的比例和幅度,以保证梯度估计的准确性和稳定性。 3. 相似度度量:选择合适的相似度度量方法(例如余弦相似度)来比较雅可比矩阵,以提高指纹匹配的准确性。
🖼️ 关键图片
📊 实验亮点
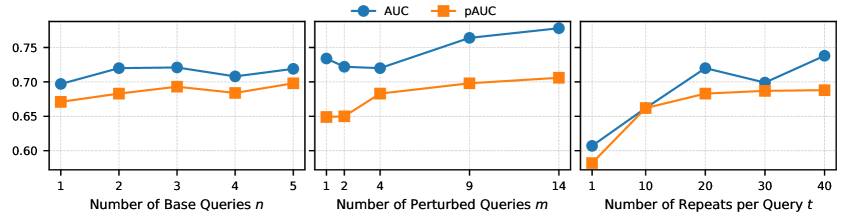
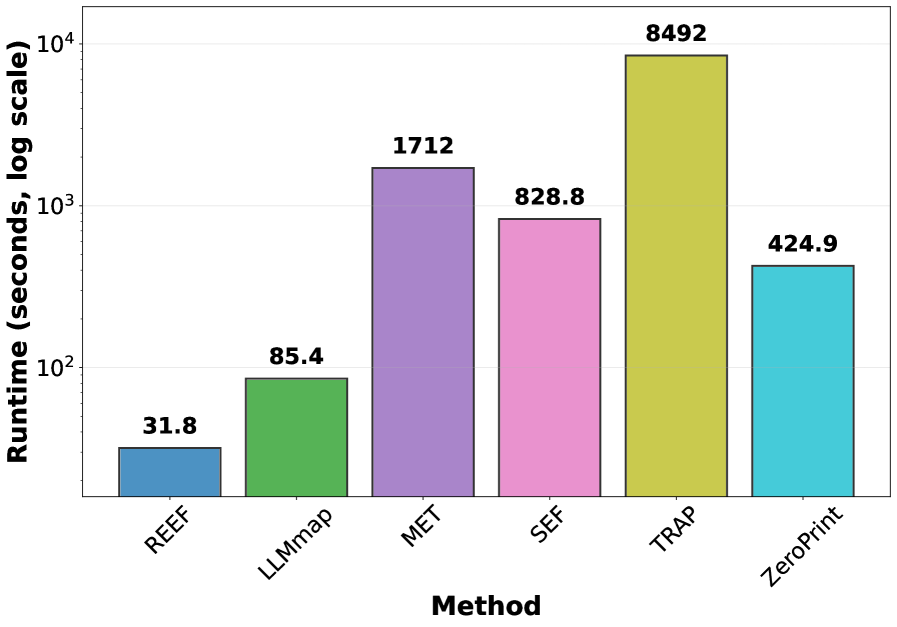
实验结果表明,ZeroPrint在LLM指纹识别任务上取得了显著的性能提升,优于现有的黑盒方法。在标准基准测试中,ZeroPrint在有效性和鲁棒性方面均达到了最先进水平,能够有效抵抗各种攻击手段,例如模型微调和参数裁剪。具体性能数据在论文中给出,相较于基线方法有显著提升。
🎯 应用场景
该研究成果可应用于保护大型语言模型的知识产权,防止模型被非法复制和滥用。通过指纹识别技术,可以追踪模型的来源,明确责任归属,维护LLM开发者的合法权益。此外,该技术还可以用于评估不同模型的相似性,分析模型的训练数据和算法,促进LLM技术的健康发展。
📄 摘要(原文)
The substantial investment required to develop Large Language Models (LLMs) makes them valuable intellectual property, raising significant concerns about copyright protection. LLM fingerprinting has emerged as a key technique to address this, which aims to verify a model's origin by extracting an intrinsic, unique signature (a "fingerprint") and comparing it to that of a source model to identify illicit copies. However, existing black-box fingerprinting methods often fail to generate distinctive LLM fingerprints. This ineffectiveness arises because black-box methods typically rely on model outputs, which lose critical information about the model's unique parameters due to the usage of non-linear functions. To address this, we first leverage Fisher Information Theory to formally demonstrate that the gradient of the model's input is a more informative feature for fingerprinting than the output. Based on this insight, we propose ZeroPrint, a novel method that approximates these information-rich gradients in a black-box setting using zeroth-order estimation. ZeroPrint overcomes the challenge of applying this to discrete text by simulating input perturbations via semantic-preserving word substitutions. This operation allows ZeroPrint to estimate the model's Jacobian matrix as a unique fingerprint. Experiments on the standard benchmark show ZeroPrint achieves a state-of-the-art effectiveness and robustness, significantly outperforming existing black-box methods.