Mitigating Surgical Data Imbalance with Dual-Prediction Video Diffusion Model
作者: Danush Kumar Venkatesh, Adam Schmidt, Muhammad Abdullah Jamal, Omid Mohareri
分类: q-bio.QM, cs.AI, eess.IV
发布日期: 2025-10-07
备注: 29 pages, 16 figures
💡 一句话要点
提出SurgiFlowVid,利用双预测视频扩散模型缓解手术视频数据不平衡问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 手术视频理解 数据不平衡 视频扩散模型 双预测 光流 数据增强 条件生成
📋 核心要点
- 手术视频数据集中罕见事件的匮乏限制了模型性能,尤其是在动作识别和工具检测等任务中。
- SurgiFlowVid通过双预测扩散模型,联合生成RGB帧和光流,并利用稀疏视觉编码器实现可控的视频生成。
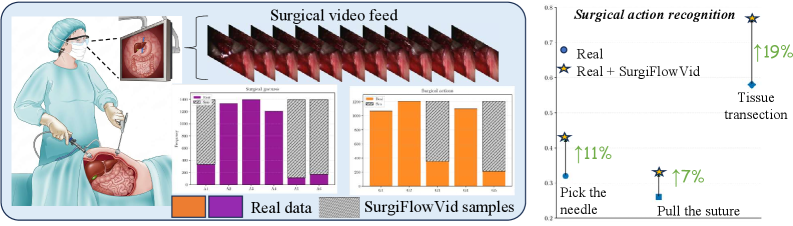
- 实验表明,使用SurgiFlowVid生成的合成数据能显著提升现有模型在多个手术视频理解任务上的性能,提升幅度达10-20%。
📝 摘要(中文)
手术视频数据集对于场景理解至关重要,能够支持手术过程建模和术中辅助。然而,这些数据集通常严重不平衡,罕见动作和工具的代表性不足,限制了下游模型的鲁棒性。本文提出了SurgiFlowVid,一个稀疏且可控的视频扩散框架,用于生成代表性不足类别的手术视频。该方法引入了一个双预测扩散模块,联合去噪RGB帧和光流,提供时间归纳偏置,从而改进有限样本的运动建模。此外,一个稀疏视觉编码器根据轻量级信号(例如,稀疏分割掩码或RGB帧)调节生成过程,实现可控性而无需密集标注。在三个手术数据集上验证了该方法在动作识别、工具存在检测和腹腔镜运动预测等任务上的有效性。由该方法生成的合成数据相对于竞争基线始终获得10-20%的增益,证明SurgiFlowVid是一种有前景的策略,可以缓解数据不平衡并推进手术视频理解方法。
🔬 方法详解
问题定义:手术视频数据集普遍存在数据不平衡问题,即某些关键动作或工具的出现频率远低于其他常见情况。这种不平衡导致模型在识别罕见事件时表现不佳,严重影响了手术场景理解的准确性和可靠性。现有方法通常依赖于数据增强或重采样,但这些方法难以有效生成高质量的、具有时间一致性的手术视频。
核心思路:SurgiFlowVid的核心思路是利用视频扩散模型生成高质量的合成手术视频,从而扩充数据集中代表性不足的类别。通过控制生成过程,可以针对性地增加特定动作或工具的样本数量,缓解数据不平衡问题。双预测模块的设计旨在更好地捕捉视频中的时间信息,提高生成视频的真实感。
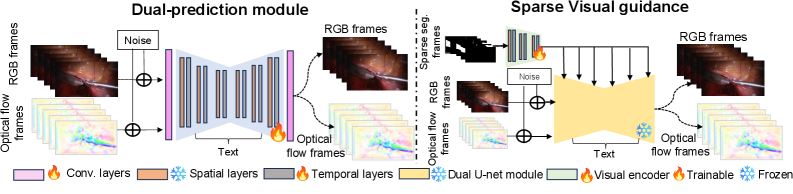
技术框架:SurgiFlowVid框架主要包含以下几个模块:1) 稀疏视觉编码器:用于提取输入信号(如稀疏分割掩码或RGB帧)的特征表示;2) 双预测扩散模块:核心生成模块,同时预测RGB帧和光流,以增强时间一致性;3) 噪声预测器:用于估计并去除视频中的噪声,逐步生成清晰的视频帧。整个流程通过条件扩散模型实现,允许用户控制生成视频的内容。
关键创新:SurgiFlowVid的关键创新在于双预测扩散模块,它同时预测RGB帧和光流。这种联合预测方式能够更好地捕捉视频中的运动信息,从而生成更逼真、时间一致性更强的合成视频。此外,稀疏视觉编码器的使用降低了对密集标注的依赖,使得该方法更易于应用到实际场景中。
关键设计:双预测扩散模块采用U-Net结构,分别对RGB帧和光流进行去噪。损失函数包括RGB重建损失、光流重建损失以及对抗损失,以保证生成视频的质量和真实感。稀疏视觉编码器使用卷积神经网络提取输入信号的特征,并将其融入到扩散模型的噪声预测过程中。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用SurgiFlowVid生成的合成数据能够显著提升现有模型在动作识别、工具存在检测和腹腔镜运动预测等任务上的性能。在三个手术数据集上,相对于竞争基线,性能提升幅度达到10-20%。这表明SurgiFlowVid是一种有效的缓解手术视频数据不平衡问题的方法。
🎯 应用场景
SurgiFlowVid在手术机器人、术中导航和手术技能评估等领域具有广泛的应用前景。通过生成更多样化的手术视频数据,可以提高相关AI模型的鲁棒性和泛化能力,从而改善手术效果,降低医疗风险。此外,该方法还可以用于生成教学视频,帮助医学生更好地学习手术技能。
📄 摘要(原文)
Surgical video datasets are essential for scene understanding, enabling procedural modeling and intra-operative support. However, these datasets are often heavily imbalanced, with rare actions and tools under-represented, which limits the robustness of downstream models. We address this challenge with $SurgiFlowVid$, a sparse and controllable video diffusion framework for generating surgical videos of under-represented classes. Our approach introduces a dual-prediction diffusion module that jointly denoises RGB frames and optical flow, providing temporal inductive biases to improve motion modeling from limited samples. In addition, a sparse visual encoder conditions the generation process on lightweight signals (e.g., sparse segmentation masks or RGB frames), enabling controllability without dense annotations. We validate our approach on three surgical datasets across tasks including action recognition, tool presence detection, and laparoscope motion prediction. Synthetic data generated by our method yields consistent gains of 10-20% over competitive baselines, establishing $SurgiFlowVid$ as a promising strategy to mitigate data imbalance and advance surgical video understanding methods.