Optimizing for Persuasion Improves LLM Generalization: Evidence from Quality-Diversity Evolution of Debate Strategies
作者: Aksel Joonas Reedi, Corentin Léger, Julien Pourcel, Loris Gaven, Perrine Charriau, Guillaume Pourcel
分类: cs.AI
发布日期: 2025-10-07 (更新: 2025-10-18)
备注: Open-source code available at https://github.com/flowersteam/llm_persuasion
💡 一句话要点
DebateQD:基于说服力优化的LLM提升泛化能力,解决过拟合问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 泛化能力 说服力优化 质量-多样性 进化算法 辩论策略 提示工程
📋 核心要点
- 现有LLM在追求真理时易过拟合,推理能力受限,泛化性差,难以适应新场景。
- 论文提出DebateQD,利用质量-多样性进化算法,通过辩论竞争优化LLM的说服能力。
- 实验表明,基于说服力优化的LLM在泛化能力上优于基于真理优化的LLM,差距高达13.94%。
📝 摘要(中文)
大型语言模型(LLMs)在优化以输出真实答案时,常常出现过拟合现象,导致推理能力脆弱且泛化失败。虽然基于说服力的优化在辩论环境中展现出潜力,但尚未与主流的基于真相的方法进行系统比较。我们引入DebateQD,这是一个最小化的质量-多样性(QD)进化算法,通过锦标赛式的竞争来进化不同类别(理性、权威、情感诉求等)的辩论策略,其中两个LLM进行辩论,第三个LLM作为评判者。与之前需要LLM群体的的方法不同,我们的方法通过单个LLM架构内的基于提示的策略来维持对手的多样性,从而更容易进行实验,同时保留了基于群体的优化的关键优势。与先前的工作相比,我们通过固定辩论协议并仅交换适应度函数来明确隔离优化目标的作用:说服力奖励说服评判者的策略,而不管真相如何,而真相奖励协作的正确性。在QuALITY基准测试的三个模型规模(7B、32B、72B参数)和多个数据集大小上,说服力优化的策略实现了高达13.94%的更小的训练-测试泛化差距,同时匹配或超过了真相优化的测试性能。这些结果提供了第一个受控证据,表明说服的竞争压力,而不是协作地寻求真相,可以培养更具可转移性的推理技能,为提高LLM的泛化能力提供了一条有希望的途径。
🔬 方法详解
问题定义:现有的大型语言模型在追求输出真实答案时,容易出现过拟合现象,导致模型在训练数据上表现良好,但在未见过的数据上表现不佳,泛化能力较差。现有的基于真理的优化方法难以有效提升LLM的泛化能力。
核心思路:论文的核心思路是通过优化LLM的说服能力来提升其泛化能力。作者认为,在辩论环境中,为了说服评判者,LLM需要学习更具鲁棒性和适应性的推理策略,从而提高其泛化能力。这种竞争性的环境能够促使模型学习更广泛的知识和推理模式。
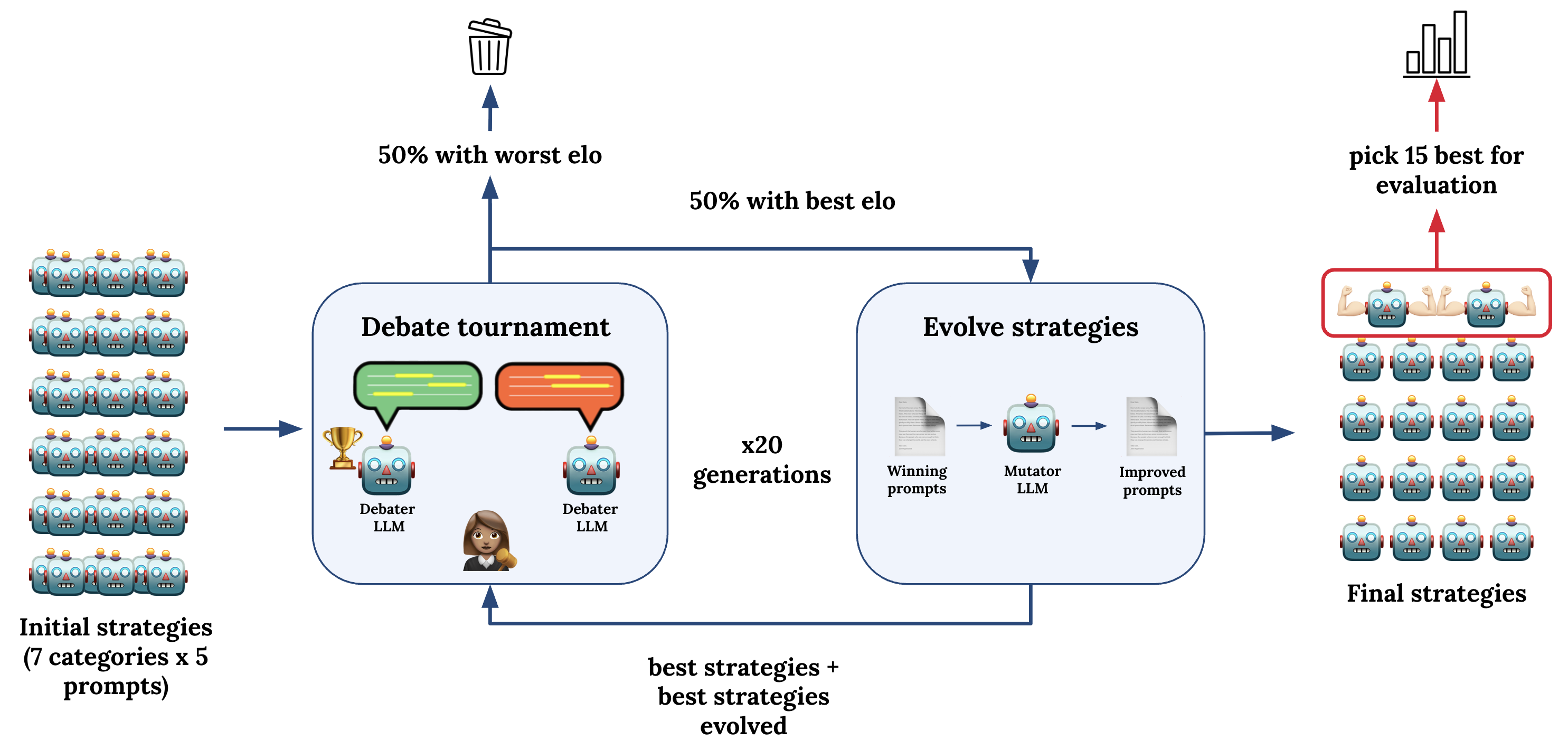
技术框架:DebateQD框架包含以下几个主要模块:1) 辩论策略生成:利用提示工程在单个LLM中生成多样化的辩论策略,包括理性、权威、情感诉求等。2) 辩论环境:构建一个三方辩论环境,其中两个LLM分别扮演正反方进行辩论,第三个LLM作为评判者。3) 质量-多样性(QD)进化算法:使用QD算法来进化辩论策略,目标是找到既具有高质量(说服力强)又具有多样性的策略。4) 适应度函数:设计适应度函数来评估辩论策略的优劣,包括基于说服力的适应度函数和基于真理的适应度函数。
关键创新:论文的关键创新在于:1) 提出了一种基于说服力优化的LLM泛化方法,与传统的基于真理的优化方法不同。2) 引入了DebateQD框架,利用QD进化算法在辩论环境中优化LLM的辩论策略。3) 通过提示工程在单个LLM中实现多样化的辩论策略,降低了实验成本。
关键设计:1) 辩论策略的提示设计:设计不同的提示模板,引导LLM生成不同类型的辩论策略。2) 适应度函数的选择:分别使用基于说服力的适应度函数和基于真理的适应度函数,进行对比实验。3) QD算法的参数设置:选择合适的QD算法(例如MAP-Elites)和参数,以保证策略的多样性和质量。4) 评判者的选择:使用LLM作为评判者,并对其进行微调,以提高评判的准确性和公正性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在QuALITY基准测试中,基于说服力优化的LLM在三个模型规模(7B、32B、72B参数)和多个数据集大小上,实现了高达13.94%的更小的训练-测试泛化差距,同时匹配或超过了基于真理优化的测试性能。这表明,说服力优化能够有效提升LLM的泛化能力。
🎯 应用场景
该研究成果可应用于提升LLM在各种需要推理和决策的场景中的性能,例如智能客服、自动驾驶、医疗诊断等。通过优化LLM的说服能力,可以使其更好地理解用户需求,做出更合理的决策,并提供更有效的解决方案。此外,该研究也为LLM的泛化能力提升提供了新的思路。
📄 摘要(原文)
Large Language Models (LLMs) optimized to output truthful answers often overfit, producing brittle reasoning that fails to generalize. While persuasion-based optimization has shown promise in debate settings, it has not been systematically compared against mainstream truth-based approaches. We introduce DebateQD, a minimal Quality-Diversity (QD) evolutionary algorithm that evolves diverse debate strategies across different categories (rationality, authority, emotional appeal, etc.) through tournament-style competitions where two LLMs debate while a third judges. Unlike previously proposed methods that require a population of LLMs, our approach maintains diversity of opponents through prompt-based strategies within a single LLM architecture, making it more accessible for experiments while preserving the key benefits of population-based optimization. In contrast to prior work, we explicitly isolate the role of the optimization objective by fixing the debate protocol and swapping only the fitness function: persuasion rewards strategies that convince the judge irrespective of truth, whereas truth rewards collaborative correctness. Across three model scales (7B, 32B, 72B parameters) and multiple dataset sizes from the QuALITY benchmark, persuasion-optimized strategies achieve up to 13.94% smaller train-test generalization gaps, while matching or exceeding truth optimization's test performance. These results provide the first controlled evidence that competitive pressure to persuade, rather than seek the truth collaboratively, fosters more transferable reasoning skills, offering a promising path for improving LLM generalization.