Early Multimodal Prediction of Cross-Lingual Meme Virality on Reddit: A Time-Window Analysis
作者: Sedat Dogan, Nina Dethlefs, Debarati Chakraborty
分类: cs.AI, cs.CL
发布日期: 2025-10-07
备注: Preprint work in progress. Main body: 9 pages. Total: 15 pages including references and appendix. 16 figures and 12 tables
💡 一句话要点
提出一种基于时间窗口分析的跨语言Meme早期流行度多模态预测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Meme流行度预测 跨语言分析 多模态融合 时间序列分析 早期预测
📋 核心要点
- 现有方法难以准确预测文化复杂、快速演变的Meme的早期流行度。
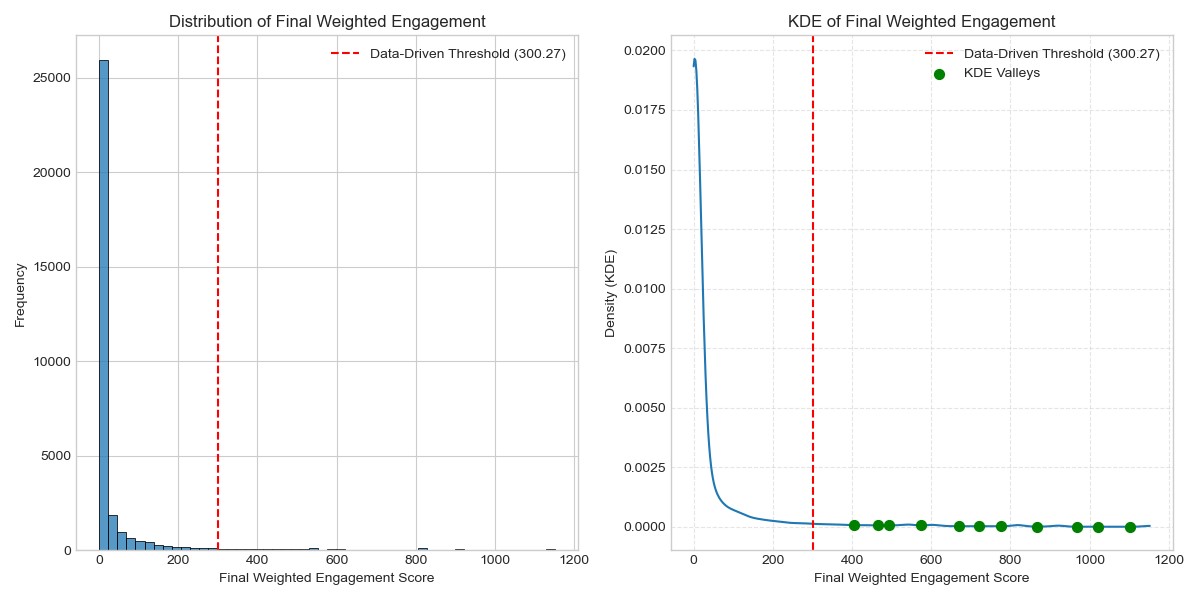
- 提出一种数据驱动的流行度定义方法,并结合多模态特征和时间窗口分析进行早期预测。
- 实验表明,仅需30分钟即可实现较好的预测效果,并揭示了特征重要性的动态变化。
📝 摘要(中文)
在线内容流行度的预测仍然具有挑战性,特别是对于文化复杂且快速发展的Meme。本研究调查了使用来自25个不同Reddit社区的大规模跨语言数据集,对Meme早期流行度进行预测的可行性。我们提出了一种稳健的、数据驱动的方法来定义流行度,该方法基于混合参与度得分,并从按时间顺序保留的训练集中学习基于百分位数的阈值,以防止数据泄露。我们评估了一系列模型,包括Logistic Regression、XGBoost和多层感知器(MLP),以及跨越增加的时间窗口(30-420分钟)的综合多模态特征集。至关重要的是,有用的信号很快就会出现:我们表现最佳的模型XGBoost在短短30分钟内就实现了PR-AUC > 0.52。我们的分析揭示了一个清晰的“证据转换”,其中特征的重要性随着Meme获得关注而从静态上下文动态地转移到时间动态。这项工作为在无法获得完整扩散级联数据的情况下,早期流行度预测建立了一个稳健、可解释且实用的基准,贡献了一个新颖的跨语言数据集和一个方法论上健全的流行度定义。据我们所知,这项研究是第一个将时间序列数据与静态内容和网络特征相结合来预测早期Meme流行度的研究。
🔬 方法详解
问题定义:论文旨在解决Reddit等在线社区中跨语言Meme的早期流行度预测问题。现有方法在处理Meme这种文化属性强、演变迅速的内容时,难以捕捉其流行趋势,且缺乏对早期信号的有效利用。此外,跨语言环境下的流行度预测更具挑战性。
核心思路:论文的核心思路是结合Meme的静态内容、网络特征和时间序列数据,通过多模态融合的方式,在早期阶段预测其流行度。通过定义一种基于混合参与度得分的流行度指标,并采用时间窗口分析方法,捕捉Meme流行过程中的动态变化。
技术框架:整体框架包括数据收集与预处理、特征提取、流行度定义、模型训练与评估四个主要阶段。首先,从Reddit收集跨语言Meme数据,并进行清洗和标注。然后,提取Meme的文本、图像、网络结构等多种模态的特征。接着,基于混合参与度得分定义Meme的流行度,并使用时间窗口分析方法。最后,训练和评估包括Logistic Regression、XGBoost和MLP在内的多种机器学习模型。
关键创新:该研究的关键创新在于:1) 提出了一个稳健的、数据驱动的流行度定义方法,避免了数据泄露;2) 结合了静态内容、网络特征和时间序列数据进行多模态融合,提高了早期预测的准确性;3) 揭示了Meme流行过程中特征重要性的动态变化,即“证据转换”现象。
关键设计:论文采用基于百分位数的阈值来定义流行度,该阈值从按时间顺序保留的训练集中学习得到,以防止数据泄露。时间窗口大小从30分钟到420分钟不等,以研究不同时间窗口下的预测性能。模型方面,选择了Logistic Regression、XGBoost和MLP等经典机器学习模型,并使用PR-AUC作为评估指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,XGBoost模型在短短30分钟内即可实现PR-AUC > 0.52的预测性能,优于其他模型。此外,研究还发现,随着Meme流行时间的推移,特征的重要性会从静态上下文转移到时间动态,揭示了Meme流行过程中的“证据转换”现象。
🎯 应用场景
该研究成果可应用于在线内容推荐、舆情监控、病毒式营销等领域。通过早期预测Meme的流行度,可以帮助平台更好地推荐热门内容,引导用户参与,并及时发现和控制不良信息传播。此外,该方法还可以扩展到其他类型的在线内容,如新闻、视频等。
📄 摘要(原文)
Predicting the virality of online content remains challenging, especially for culturally complex, fast-evolving memes. This study investigates the feasibility of early prediction of meme virality using a large-scale, cross-lingual dataset from 25 diverse Reddit communities. We propose a robust, data-driven method to define virality based on a hybrid engagement score, learning a percentile-based threshold from a chronologically held-out training set to prevent data leakage. We evaluated a suite of models, including Logistic Regression, XGBoost, and a Multi-layer Perceptron (MLP), with a comprehensive, multimodal feature set across increasing time windows (30-420 min). Crucially, useful signals emerge quickly: our best-performing model, XGBoost, achieves a PR-AUC $>$ 0.52 in just 30 minutes. Our analysis reveals a clear "evidentiary transition," in which the importance of the feature dynamically shifts from the static context to the temporal dynamics as a meme gains traction. This work establishes a robust, interpretable, and practical benchmark for early virality prediction in scenarios where full diffusion cascade data is unavailable, contributing a novel cross-lingual dataset and a methodologically sound definition of virality. To our knowledge, this study is the first to combine time series data with static content and network features to predict early meme virality.