Uncovering Representation Bias for Investment Decisions in Open-Source Large Language Models
作者: Fabrizio Dimino, Krati Saxena, Bhaskarjit Sarmah, Stefano Pasquali
分类: q-fin.CP, cs.AI
发布日期: 2025-10-07 (更新: 2025-11-03)
💡 一句话要点
揭示开源大语言模型在投资决策中的表征偏差,关注Qwen模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 金融应用 表征偏差 投资决策 Qwen模型 置信度评分 公平性
📋 核心要点
- 现有研究较少关注大语言模型在金融应用中存在的偏差,特别是与公司规模、行业和财务特征相关的偏差,这会影响投资决策。
- 论文提出一种平衡轮询提示方法,结合约束解码和token-logit聚合,为公司生成财务背景下的置信度评分,以此评估模型的表征偏差。
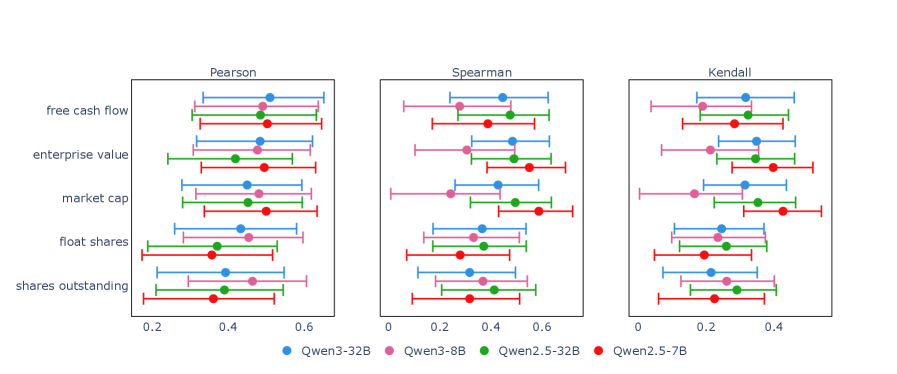
- 实验表明,公司规模和估值会提高模型置信度,风险因素降低置信度,科技行业的置信度变异性最大,模型对基本面数据的置信度最高。
📝 摘要(中文)
大型语言模型越来越多地被应用于金融领域,以支持投资工作流程。然而,以往的研究很少考察这些模型如何反映与公司规模、行业或财务特征相关的偏差,而这些偏差可能会严重影响决策。本文着重研究开源Qwen模型中的表征偏差,以填补这一空白。我们提出了一种针对约150家美国股票的平衡轮询提示方法,应用约束解码和token-logit聚合来获得公司层面的财务背景置信度评分。通过统计测试和方差分析,我们发现公司规模和估值始终会提高模型置信度,而风险因素往往会降低置信度。不同行业的置信度差异显著,其中科技行业的变异性最大。当模型被提示特定财务类别时,它们的置信度排名与基本面数据最吻合,与技术信号中等吻合,与增长指标最不吻合。这些结果突出了Qwen模型中的表征偏差,并激发了针对安全和公平的金融LLM部署的行业感知校准和类别条件评估协议。
🔬 方法详解
问题定义:现有的大语言模型在金融投资决策中被广泛应用,但它们可能存在与公司规模、行业、财务特征相关的偏差,这些偏差会影响投资决策的公平性和准确性。以往的研究对这些偏差关注不足,缺乏系统性的评估方法。
核心思路:论文的核心思路是通过设计一种平衡的提示方法,并结合约束解码和置信度评分机制,来量化大语言模型在不同财务背景下对不同公司的置信度。通过分析置信度与公司特征之间的关系,从而揭示模型存在的表征偏差。
技术框架:整体框架包含以下几个主要阶段: 1. 数据准备:选取约150家美国上市公司的财务数据和公司信息。 2. 提示工程:设计平衡轮询提示策略,确保每个公司在不同财务背景下都被公平地评估。 3. 模型推理:使用Qwen模型进行推理,并应用约束解码,限制模型的输出范围。 4. 置信度评分:通过token-logit聚合方法,计算公司层面的置信度评分。 5. 偏差分析:使用统计测试和方差分析,分析置信度与公司特征(如规模、行业、估值、风险)之间的关系,从而揭示表征偏差。
关键创新:论文的关键创新在于提出了一种系统性的方法来量化大语言模型在金融领域的表征偏差。该方法结合了平衡轮询提示、约束解码和token-logit聚合,能够有效地评估模型对不同公司和财务背景的置信度。与以往的研究相比,该方法更加全面和深入,能够揭示模型中隐藏的偏差。
关键设计: * 平衡轮询提示:确保每个公司在不同财务背景下都被公平地评估,避免因提示方式不同而引入偏差。 * 约束解码:限制模型的输出范围,提高输出的可控性和准确性。 * Token-logit聚合:使用token-logit聚合方法计算置信度评分,能够更准确地反映模型对不同公司的置信程度。 * 统计测试和方差分析:使用统计测试和方差分析方法,分析置信度与公司特征之间的关系,从而揭示表征偏差。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Qwen模型在金融领域存在显著的表征偏差。具体来说,公司规模和估值会提高模型置信度,而风险因素会降低置信度。不同行业的置信度差异显著,科技行业的变异性最大。模型对基本面数据的置信度最高,对技术信号的置信度中等,对增长指标的置信度最低。这些发现为金融大语言模型的安全和公平部署提供了重要的参考。
🎯 应用场景
该研究成果可应用于金融领域,帮助投资者和金融机构更好地理解和评估大语言模型在投资决策中的潜在偏差。通过对模型进行校准和调整,可以提高投资决策的公平性和准确性,降低投资风险。未来的研究可以进一步探索如何减轻或消除这些偏差,并开发更可靠的金融大语言模型。
📄 摘要(原文)
Large Language Models are increasingly adopted in financial applications to support investment workflows. However, prior studies have seldom examined how these models reflect biases related to firm size, sector, or financial characteristics, which can significantly impact decision-making. This paper addresses this gap by focusing on representation bias in open-source Qwen models. We propose a balanced round-robin prompting method over approximately 150 U.S. equities, applying constrained decoding and token-logit aggregation to derive firm-level confidence scores across financial contexts. Using statistical tests and variance analysis, we find that firm size and valuation consistently increase model confidence, while risk factors tend to decrease it. Confidence varies significantly across sectors, with the Technology sector showing the greatest variability. When models are prompted for specific financial categories, their confidence rankings best align with fundamental data, moderately with technical signals, and least with growth indicators. These results highlight representation bias in Qwen models and motivate sector-aware calibration and category-conditioned evaluation protocols for safe and fair financial LLM deployment.