D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI
作者: Suhwan Choi, Jaeyoon Jung, Haebin Seong, Minchan Kim, Minyeong Kim, Yongjun Cho, Yoonshik Kim, Yubeen Park, Youngjae Yu, Yunsung Lee
分类: cs.AI, cs.CV, cs.RO
发布日期: 2025-10-07 (更新: 2025-12-17)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
D2E框架:利用桌面数据预训练提升具身智能机器人性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 预训练 桌面数据 迁移学习 机器人 逆动力学模型 伪标签
📋 核心要点
- 具身智能受限于物理轨迹数据收集的高昂成本,而桌面环境提供大规模、结构化的观察-动作耦合数据,但缺乏有效利用方法。
- D2E框架通过OWA工具包统一桌面交互数据格式,利用Generalist-IDM生成伪标签,并使用VAPT将预训练表示迁移到机器人任务。
- 实验表明,D2E框架在LIBERO操作和CANVAS导航基准上取得了显著成功,验证了桌面预训练在具身智能中的有效性。
📝 摘要(中文)
本文提出D2E(Desktop to Embodied AI)框架,旨在利用桌面环境(特别是游戏)中丰富的传感器交互数据,作为具身智能机器人任务的有效预训练基底。D2E包含三个核心组件:OWA Toolkit,用于将各种桌面交互统一为标准化格式并实现152倍压缩;Generalist-IDM,通过基于时间戳的事件预测实现跨未见游戏的零样本泛化,从而支持互联网规模的伪标签生成;VAPT,将桌面预训练的表示迁移到物理操作和导航任务中。实验结果表明,使用1.3K+小时的数据(259小时的人工演示和1K+小时的伪标签游戏数据),在LIBERO操作基准上实现了96.6%的成功率,在CANVAS导航基准上实现了83.3%的成功率。这验证了数字交互中的传感器运动原语具有足够的不变性,可以有效地迁移到物理具身任务中,从而确立了桌面预训练作为机器人技术的一种实用范例。
🔬 方法详解
问题定义:现有具身智能方法依赖于昂贵的物理环境数据收集,限制了模型规模和泛化能力。虽然桌面环境(如游戏)提供了丰富的交互数据,但缺乏统一的数据格式和有效的迁移方法,难以直接应用于机器人任务。此外,如何利用大规模无标注的桌面数据进行预训练也是一个挑战。
核心思路:D2E的核心思路是将桌面环境视为具身智能的预训练平台,利用桌面环境中低成本、大规模的交互数据学习通用的传感器运动原语,然后将这些知识迁移到物理机器人任务中。通过统一数据格式、生成伪标签和设计迁移学习策略,克服了桌面环境与物理环境之间的差异。
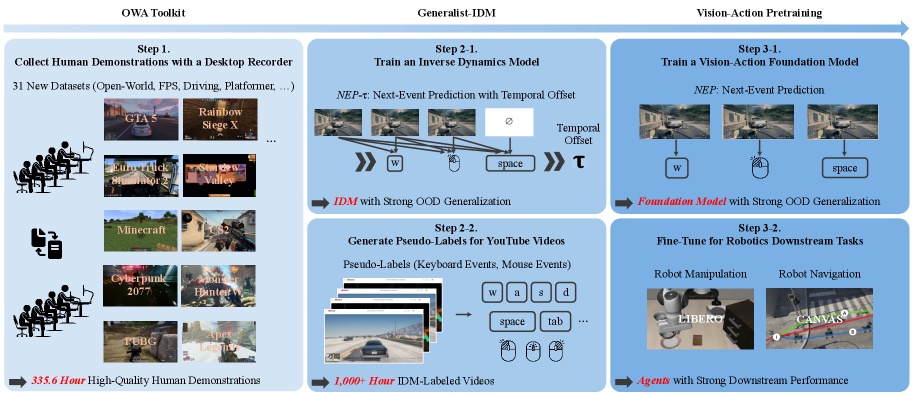
技术框架:D2E框架包含三个主要组件:1) OWA Toolkit:用于统一各种桌面交互数据格式,并进行高效压缩。2) Generalist-IDM:一个通用的逆动力学模型,用于预测游戏事件,从而生成大规模伪标签数据。3) VAPT:一个视觉-动作预训练模型,利用桌面数据进行预训练,然后通过微调迁移到物理机器人任务中。整体流程是先利用OWA Toolkit收集和处理桌面数据,然后使用Generalist-IDM生成伪标签,最后使用VAPT进行预训练和迁移。
关键创新:D2E的关键创新在于建立了一个完整的、可扩展的桌面预训练框架,并验证了其在具身智能中的有效性。具体包括:1) OWA Toolkit:统一了不同桌面环境的数据格式,简化了数据收集和处理流程。2) Generalist-IDM:实现了跨游戏的零样本泛化,能够生成大规模的伪标签数据。3) VAPT:设计了一种有效的迁移学习策略,将桌面预训练的知识迁移到物理机器人任务中。
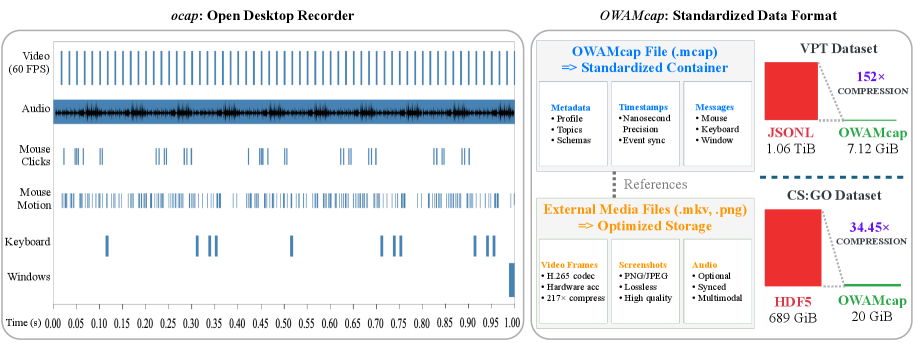
关键设计:OWA Toolkit采用了高效的压缩算法,实现了152倍的数据压缩。Generalist-IDM基于时间戳预测游戏事件,并使用对比学习进行训练。VAPT模型采用了Transformer架构,并使用行为克隆损失进行预训练,然后通过微调适应不同的机器人任务。
🖼️ 关键图片
📊 实验亮点
D2E框架在LIBERO操作基准上实现了96.6%的成功率,在CANVAS导航基准上实现了83.3%的成功率。相比于直接在物理环境训练,D2E显著提升了机器人的性能,验证了桌面预训练的有效性。此外,该研究开源了OWA Toolkit、数据集和预训练模型,为后续研究提供了便利。
🎯 应用场景
D2E框架具有广泛的应用前景,可用于提升机器人在操作、导航等任务中的性能。通过利用大规模桌面数据进行预训练,可以降低机器人学习的成本,提高其泛化能力和适应性。该研究为具身智能的发展提供了一种新的思路,有望推动机器人在家庭服务、工业自动化等领域的应用。
📄 摘要(原文)
Large language models leverage internet-scale text data, yet embodied AI remains constrained by the prohibitive costs of physical trajectory collection. Desktop environments -- particularly gaming -- offer a compelling alternative: they provide rich sensorimotor interactions at scale while maintaining the structured observation-action coupling essential for embodied learning. We present D2E (Desktop to Embodied AI), a framework that demonstrates desktop interactions can serve as an effective pretraining substrate for robotics embodied AI tasks. Unlike prior work that remained domain-specific (e.g., VPT for Minecraft) or kept data proprietary (e.g., SIMA), D2E establishes a complete pipeline from scalable desktop data collection to verified transfer in embodied domains. Our framework comprises three components: (1) the OWA Toolkit that unifies diverse desktop interactions into a standardized format with 152x compression, (2) the Generalist-IDM that achieves strong zero-shot generalization across unseen games through timestamp-based event prediction, enabling internet-scale pseudo-labeling, and (3) VAPT that transfers desktop-pretrained representations to physical manipulation and navigation. Using 1.3K+ hours of data (259 hours of human demonstrations, and 1K+ hours of pseudo-labeled gameplay), we achieve a total of 96.6% success rate on LIBERO manipulation and 83.3% on CANVAS navigation benchmarks. This validates that sensorimotor primitives in digital interactions exhibit sufficient invariance to transfer meaningfully to physical embodied tasks, establishing desktop pretraining as a practical paradigm for robotics. We will make all our work public, including the OWA toolkit, datasets of human-collected and pseudo-labeled, and VAPT-trained models available at https://worv-ai.github.io/d2e/