In-the-Flow Agentic System Optimization for Effective Planning and Tool Use
作者: Zhuofeng Li, Haoxiang Zhang, Seungju Han, Sheng Liu, Jianwen Xie, Yu Zhang, Yejin Choi, James Zou, Pan Lu
分类: cs.AI, cs.CL, cs.LG, cs.MA
发布日期: 2025-10-07
备注: 45 pages, 12 figures. Project website: https://agentflow.stanford.edu/
💡 一句话要点
提出AgentFlow,通过在流程中优化Agent系统,有效提升规划能力和工具使用效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent系统 流程优化 强化学习 长程规划 工具使用 在线学习 多轮交互
📋 核心要点
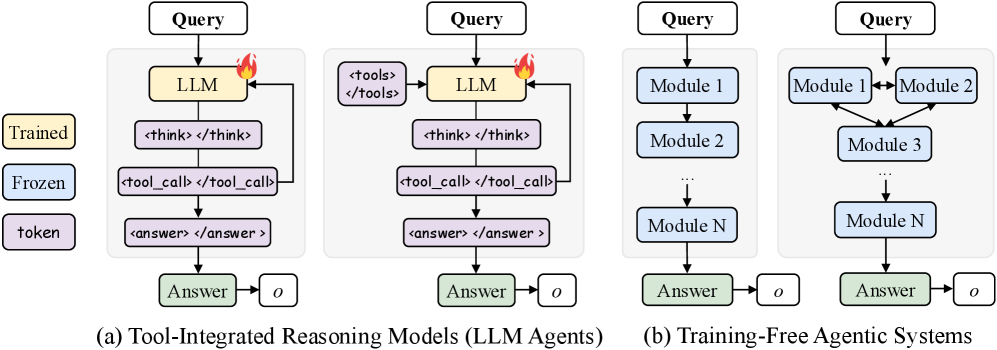
- 现有工具增强的大语言模型方法采用单体策略,难以处理长程任务和多样工具,泛化能力弱。
- AgentFlow通过可训练的模块化Agent系统,在多轮交互中直接优化规划器,提升决策质量。
- Flow-GRPO方法解决了长程稀疏奖励问题,实验表明AgentFlow在多个任务上显著优于现有方法。
📝 摘要(中文)
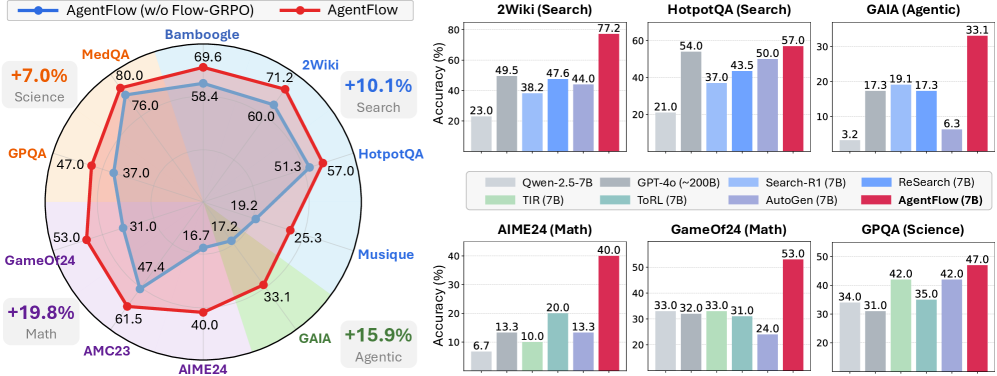
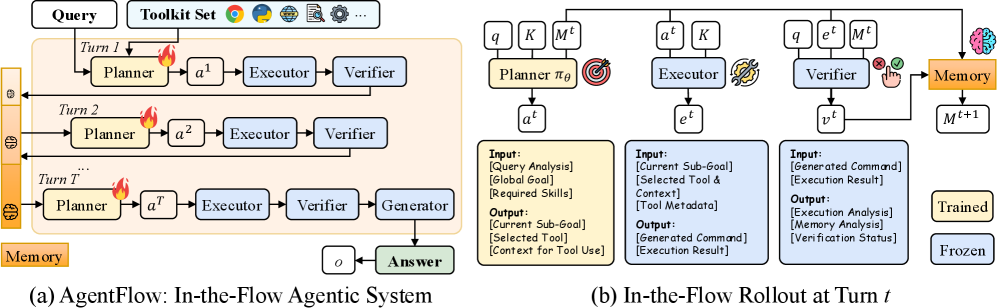
本文提出了一种可训练的、流程中的Agent系统框架AgentFlow,它通过不断演进的记忆协调四个模块(规划器、执行器、验证器、生成器),并在多轮交互循环中直接优化其规划器。为了在实时环境中进行在线策略训练,本文提出了基于流的组精炼策略优化(Flow-GRPO),该方法通过将多轮优化转换为一系列易于处理的单轮策略更新,解决了长程、稀疏奖励下的信用分配问题。它将单个可验证的轨迹级结果广播到每一轮,使局部规划器决策与全局成功对齐,并通过组归一化优势函数稳定学习。在十个基准测试中,AgentFlow的7B规模模型优于最佳基线,在搜索、Agent系统、数学和科学任务上的平均准确率分别提高了14.9%、14.0%、14.5%和4.1%,甚至超过了GPT-4o等更大的专有模型。进一步的分析证实了流程中优化的好处,表明规划能力得到改善,工具调用可靠性增强,并且随着模型大小和推理轮数的增加而呈现积极的扩展性。
🔬 方法详解
问题定义:现有基于结果驱动的强化学习方法在大型语言模型(LLMs)中取得了进展,但主流的工具增强方法训练的是一个单一的、单体的策略,该策略在完整上下文中交织了思想和工具调用;这在长视野和多样化工具的情况下扩展性较差,并且对新场景的泛化能力较弱。现有Agent系统虽然有潜力,但大多是免训练的,或者依赖于与多轮交互的实时动态解耦的离线训练。
核心思路:AgentFlow的核心思路是将Agent系统设计成一个可训练的流程,通过在多轮交互的“流程中”直接优化规划器,来提升其长期规划能力和工具使用效率。这种“流程中”的优化方式能够更好地利用实时环境的反馈,从而克服离线训练的局限性。
技术框架:AgentFlow框架包含四个主要模块:规划器(Planner)、执行器(Executor)、验证器(Verifier)和生成器(Generator)。规划器负责制定任务执行计划,执行器负责调用工具并执行计划,验证器评估执行结果,生成器负责生成最终输出。这些模块通过一个不断演进的记忆(Memory)进行协调。Flow-GRPO算法用于在线策略训练,将多轮优化分解为一系列单轮策略更新。
关键创新:AgentFlow的关键创新在于其“流程中”的优化方式和Flow-GRPO算法。传统的Agent系统要么是免训练的,要么是离线训练的,无法充分利用实时环境的反馈。AgentFlow通过在多轮交互的流程中直接优化规划器,能够更好地适应环境变化,提升长期规划能力。Flow-GRPO算法通过将多轮优化分解为单轮优化,并引入组归一化优势函数,解决了长程稀疏奖励问题,稳定了学习过程。
关键设计:Flow-GRPO算法的关键设计包括:1) 将轨迹级别的结果广播到每一轮,使局部规划器决策与全局成功对齐;2) 使用组归一化优势函数来稳定学习,避免梯度爆炸或消失;3) 将多轮优化问题转化为一系列易于处理的单轮策略更新问题。具体参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
AgentFlow在十个基准测试中表现出色,平均准确率显著优于现有方法。在搜索任务上提升14.9%,在Agent系统任务上提升14.0%,在数学任务上提升14.5%,在科学任务上提升4.1%。值得注意的是,AgentFlow甚至超越了GPT-4o等更大的专有模型,证明了其在规划和工具使用方面的卓越能力。
🎯 应用场景
AgentFlow具有广泛的应用前景,可应用于智能助手、自动化流程、科学研究等领域。例如,可以用于构建更智能的对话系统,帮助用户完成复杂的任务;可以用于优化自动化流程,提高生产效率;还可以用于辅助科学家进行科学研究,例如设计实验、分析数据等。该研究的实际价值在于提升Agent系统的智能化水平和应用范围,未来有望推动人工智能技术在各行各业的广泛应用。
📄 摘要(原文)
Outcome-driven reinforcement learning has advanced reasoning in large language models (LLMs), but prevailing tool-augmented approaches train a single, monolithic policy that interleaves thoughts and tool calls under full context; this scales poorly with long horizons and diverse tools and generalizes weakly to new scenarios. Agentic systems offer a promising alternative by decomposing work across specialized modules, yet most remain training-free or rely on offline training decoupled from the live dynamics of multi-turn interaction. We introduce AgentFlow, a trainable, in-the-flow agentic framework that coordinates four modules (planner, executor, verifier, generator) through an evolving memory and directly optimizes its planner inside the multi-turn loop. To train on-policy in live environments, we propose Flow-based Group Refined Policy Optimization (Flow-GRPO), which tackles long-horizon, sparse-reward credit assignment by converting multi-turn optimization into a sequence of tractable single-turn policy updates. It broadcasts a single, verifiable trajectory-level outcome to every turn to align local planner decisions with global success and stabilizes learning with group-normalized advantages. Across ten benchmarks, AgentFlow with a 7B-scale backbone outperforms top-performing baselines with average accuracy gains of 14.9% on search, 14.0% on agentic, 14.5% on mathematical, and 4.1% on scientific tasks, even surpassing larger proprietary models like GPT-4o. Further analyses confirm the benefits of in-the-flow optimization, showing improved planning, enhanced tool-calling reliability, and positive scaling with model size and reasoning turns.