Orders in Chaos: Enhancing Large-Scale MoE LLM Serving with Data Movement Forecasting
作者: Zhongkai Yu, Yue Guan, Zihao Yu, Chenyang Zhou, Zhengding Hu, Shuyi Pei, Yangwook Kang, Yufei Ding, Po-An Tsai
分类: cs.DC, cs.AI, cs.AR, cs.LG
发布日期: 2025-10-07 (更新: 2025-12-05)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
通过数据移动预测增强大规模MoE LLM Serving性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 大语言模型 模型服务 数据移动优化 性能分析 GPU加速 模型部署
📋 核心要点
- 大规模MoE模型serving面临数据移动瓶颈,随机专家选择导致显著的通信开销,严重影响系统性能。
- 通过对MoE模型的数据移动模式进行深入分析,提取关键见解,指导serving系统设计,优化数据传输。
- 通过架构修改,在晶圆级GPU上验证了该方法的有效性,实现了DeepSeek V3和Qwen3的显著加速。
📝 摘要(中文)
大规模混合专家(MoE)大语言模型(LLM)已成为前沿的开源权重模型,其模型能力与专有模型相似。然而,其随机专家选择机制引入了显著的数据移动开销,这成为多单元LLM serving系统中的主要瓶颈。为了理解这种数据移动背后的模式,我们对2025年发布的四种最先进的大规模MoE模型(200B-1000B)进行了全面的数据移动中心分析,使用了超过24,000个跨越不同工作负载的请求。我们从时间和空间角度进行了系统分析,并提炼出六个关键见解,以指导未来多样化serving系统的设计。我们以晶圆级GPU为例,展示了如何利用这些见解来改进架构,并表明通过微小的架构修改,可以实现显著的性能提升,在DeepSeek V3和Qwen3上分别实现了5.3倍和3.1倍的平均加速。我们的工作首次对大规模MoE模型进行了全面的数据中心分析,并使用学习到的经验进行了具体的设计研究,分析追踪和模拟框架已开源,下载量超过1000次。我们的追踪和结果可在https://huggingface.co/datasets/core12345/MoE_expert_selection_trace公开获取。
🔬 方法详解
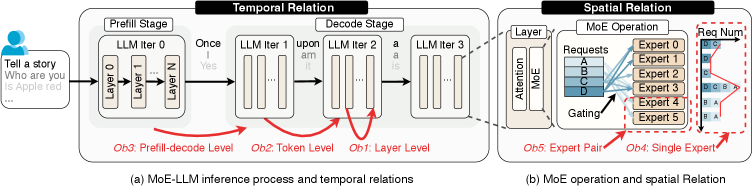
问题定义:大规模MoE LLM serving的关键瓶颈在于随机专家选择导致的大量数据移动。现有方法未能充分利用数据移动的内在模式,导致资源利用率低下和性能瓶颈。需要解决的问题是如何减少数据移动开销,提高serving效率。
核心思路:论文的核心思路是通过对MoE模型的数据移动模式进行深入分析和预测,从而优化数据传输和资源调度。通过理解数据移动的时空特性,可以设计更高效的serving系统,减少不必要的数据传输,提高系统吞吐量。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 对大规模MoE模型进行数据移动分析,收集详细的专家选择追踪数据。2) 从时间和空间角度对数据进行系统分析,提取关键见解。3) 基于这些见解,提出serving系统优化方案,例如针对晶圆级GPU的架构修改。4) 通过实验验证优化方案的有效性。
关键创新:该论文最重要的技术创新点在于首次对大规模MoE模型进行了全面的数据中心分析,并提取了六个关键见解,这些见解可以指导未来serving系统的设计。此外,论文还展示了如何将这些见解应用于实际的硬件架构优化,并取得了显著的性能提升。
关键设计:论文的关键设计在于对数据移动模式的深入分析,包括专家选择的频率、数据传输量、以及专家之间的依赖关系。基于这些分析,可以设计更智能的数据预取策略、更高效的通信拓扑、以及更优化的资源调度算法。针对晶圆级GPU的架构修改可能包括增加片上缓存、优化数据传输路径、以及实现更高效的专家选择机制。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过利用数据移动预测的见解,对晶圆级GPU进行微小的架构修改,可以显著提高MoE模型的serving性能。在DeepSeek V3和Qwen3上分别实现了5.3倍和3.1倍的平均加速。这些结果验证了该方法的有效性,并表明通过优化数据移动可以显著提高大规模MoE模型的serving效率。
🎯 应用场景
该研究成果可广泛应用于大规模MoE模型的部署和serving,尤其是在资源受限的环境下,如边缘计算设备或低功耗服务器。通过优化数据移动,可以显著提高模型推理速度,降低能耗,并支持更大规模的模型部署。该研究对于推动MoE模型在实际应用中的普及具有重要意义。
📄 摘要(原文)
Large-scale Mixture of Experts (MoE) Large Language Models (LLMs) have recently become the frontier open weight models, achieving remarkable model capability similar to proprietary ones. But their random expert selection mechanism introduces significant data movement overhead that becomes the dominant bottleneck in multi-unit LLM serving systems. To understand the patterns underlying this data movement, we conduct comprehensive data-movement-centric profiling across four state-of-the-art large-scale MoE models released in 2025 (200B-1000B) using over 24,000 requests spanning diverse workloads. We perform systematic analysis from both temporal and spatial perspectives and distill six key insights to guide the design of diverse future serving systems. With our insights, we then demonstrate how to improve wafer-scale GPUs as a case study, and show that minor architectural modifications leveraging the insights achieve substantial performance gains, delivering 5.3x and 3.1x average speedups on DeepSeek V3 and Qwen3, respectively. Our work presents the first comprehensive data-centric analysis of large-scale MoE models and a concrete design study using the learned lessons, with profiling traces and simulation framework already open-sourced with $>$1k downloads. Our traces and results are publicly available at https://huggingface.co/datasets/core12345/MoE_expert_selection_trace