Vul-R2: A Reasoning LLM for Automated Vulnerability Repair
作者: Xin-Cheng Wen, Zirui Lin, Yijun Yang, Cuiyun Gao, Deheng Ye
分类: cs.AI, cs.SE
发布日期: 2025-10-07
备注: 13 pages, 8 figures. This paper is accepted by ASE 2025
💡 一句话要点
Vul-R2:一种用于自动漏洞修复的推理LLM
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动漏洞修复 大型语言模型 软件安全 推理模型 漏洞分析
📋 核心要点
- 现有AVR方法依赖通用编程知识,缺乏漏洞相关推理数据,难以捕捉多样化的修复模式。
- Vul-R2旨在通过推理LLM,提升模型在漏洞修复任务中的性能和可靠性。
- 由于缺乏中间可验证的反馈,漏洞修复过程中的模型训练面临额外的挑战。
📝 摘要(中文)
软件漏洞的指数级增长迫切需要自动漏洞修复(AVR)解决方案。最近的研究将AVR定义为序列生成问题,并利用大型语言模型(LLM)来解决这个问题。通常,这些方法提示或微调LLM以直接生成漏洞修复。尽管这些方法表现出最先进的性能,但它们面临以下挑战:(1)缺乏高质量的、与漏洞相关的推理数据。当前的方法主要依赖于主要编码通用编程知识的基础模型。如果没有与漏洞相关的推理数据,它们往往无法捕捉到多样化的漏洞修复模式。(2)难以验证LLM训练期间的中间漏洞修复过程。现有的强化学习方法通常利用来自环境的中间执行反馈(例如,基于沙箱的执行结果)来指导强化学习训练。相比之下,漏洞修复过程通常缺乏这种中间的、可验证的反馈,这给模型训练带来了额外的挑战。
🔬 方法详解
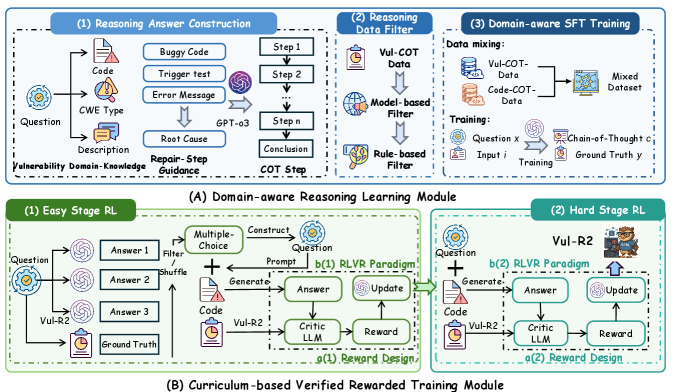
问题定义:论文旨在解决自动漏洞修复(AVR)问题,现有方法主要依赖于大型语言模型(LLM),但缺乏高质量的漏洞相关推理数据,导致无法有效捕捉多样化的漏洞修复模式。此外,漏洞修复过程缺乏中间可验证的反馈,使得模型训练更加困难。
核心思路:论文的核心思路是构建一个推理LLM(Vul-R2),通过引入漏洞相关的推理能力,提升模型在AVR任务中的性能。该模型旨在更好地理解漏洞的本质,并生成更准确、更有效的修复方案。
技术框架:论文未详细描述Vul-R2的具体架构或流程,但可以推断其可能包含以下模块/阶段:1) 漏洞分析模块:用于理解漏洞的类型、位置和影响;2) 推理模块:利用漏洞相关知识和推理规则,生成修复方案;3) 代码生成模块:将修复方案转化为可执行的代码;4) 验证模块(可能):验证修复方案的有效性。
关键创新:论文的关键创新在于提出了一个专门用于漏洞修复的推理LLM。与现有方法相比,Vul-R2更加注重漏洞相关的推理能力,而不是仅仅依赖于通用编程知识。这种方法有望更好地捕捉漏洞的本质,并生成更有效的修复方案。
关键设计:由于论文摘要中没有提供关于Vul-R2的具体技术细节,例如参数设置、损失函数、网络结构等,因此这部分信息未知。未来的研究可能需要进一步探索这些技术细节,以优化Vul-R2的性能。
🖼️ 关键图片


📊 实验亮点
摘要中未提供具体的实验结果和性能数据,因此无法总结实验亮点。未来的论文全文应该包含实验部分,并提供具体的性能指标,例如修复成功率、修复时间等,以便与其他AVR方法进行比较。
🎯 应用场景
该研究成果可应用于软件安全领域,实现自动化的漏洞修复,降低人工修复成本,提高软件安全性。潜在的应用场景包括:安全漏洞扫描后的自动修复、软件开发过程中的实时漏洞修复建议、以及针对特定类型漏洞的批量修复等。该研究的未来影响在于推动AVR技术的发展,构建更安全可靠的软件系统。
📄 摘要(原文)
The exponential increase in software vulnerabilities has created an urgent need for automatic vulnerability repair (AVR) solutions. Recent research has formulated AVR as a sequence generation problem and has leveraged large language models (LLMs) to address this problem. Typically, these approaches prompt or fine-tune LLMs to generate repairs for vulnerabilities directly. Although these methods show state-of-the-art performance, they face the following challenges: (1) Lack of high-quality, vulnerability-related reasoning data. Current approaches primarily rely on foundation models that mainly encode general programming knowledge. Without vulnerability-related reasoning data, they tend to fail to capture the diverse vulnerability repair patterns. (2) Hard to verify the intermediate vulnerability repair process during LLM training. Existing reinforcement learning methods often leverage intermediate execution feedback from the environment (e.g., sandbox-based execution results) to guide reinforcement learning training. In contrast, the vulnerability repair process generally lacks such intermediate, verifiable feedback, which poses additional challenges for model training.