AutoDAN-Reasoning: Enhancing Strategies Exploration based Jailbreak Attacks with Test-Time Scaling
作者: Xiaogeng Liu, Chaowei Xiao
分类: cs.CR, cs.AI
发布日期: 2025-10-06 (更新: 2025-10-08)
备注: Technical report. Code is available at https://github.com/SaFoLab-WISC/AutoDAN-Reasoning
💡 一句话要点
AutoDAN-Reasoning:通过测试时缩放增强基于策略探索的LLM越狱攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 对抗性攻击 测试时缩放 策略探索
📋 核心要点
- 现有AutoDAN-Turbo等方法在测试时仅采样单个策略生成攻击提示,未能充分挖掘策略库的潜力。
- 论文提出测试时缩放方法,包括Best-of-N和Beam Search,以探索更有效的攻击提示。
- 实验表明,提出的方法显著提升了攻击成功率,尤其是在对抗鲁棒模型时效果显著。
📝 摘要(中文)
最近,诸如AutoDAN-Turbo等大型语言模型(LLM)越狱技术的进步,展示了自动化策略发现的强大能力。AutoDAN-Turbo采用终身学习代理,从头开始构建丰富的攻击策略库。虽然非常有效,但其测试时生成过程涉及采样一个策略并生成单个相应的攻击提示,这可能无法充分利用已学习策略库的潜力。在本文中,我们提出通过测试时缩放来进一步提高AutoDAN-Turbo的攻击性能。我们引入了两种不同的缩放方法:Best-of-N和Beam Search。Best-of-N方法从采样的策略生成N个候选攻击提示,并根据评分器模型选择最有效的提示。Beam Search方法通过探索策略库中策略的组合来进行更详尽的搜索,以发现更强大和协同的攻击向量。实验表明,所提出的方法显著提高了性能,其中Beam Search在Llama-3.1-70B-Instruct上的攻击成功率提高了高达15.6个百分点,并且与原始方法相比,针对高度鲁棒的GPT-o4-mini实现了近60%的相对改进。
🔬 方法详解
问题定义:论文旨在解决AutoDAN-Turbo等现有越狱攻击方法在测试时策略利用不足的问题。现有方法仅从策略库中采样单个策略生成攻击提示,忽略了策略库中可能存在的更优策略组合,导致攻击效果受限。
核心思路:论文的核心思路是通过测试时缩放,即在测试阶段生成多个候选攻击提示,并从中选择最优的提示。通过增加提示的多样性,更充分地利用已学习的策略库,从而提高攻击成功率。
技术框架:论文主要包含两个测试时缩放方法:Best-of-N和Beam Search。Best-of-N方法首先从策略库中采样一个策略,然后基于该策略生成N个候选攻击提示,并使用评分器模型对这些提示进行评估,选择得分最高的提示作为最终的攻击提示。Beam Search方法则采用更详尽的搜索策略,通过探索策略库中策略的组合,生成多个攻击向量,并使用评分器模型进行评估,选择最优的攻击向量。
关键创新:论文的关键创新在于提出了测试时缩放的概念,并将其应用于LLM越狱攻击。与现有方法仅使用单个攻击提示不同,论文提出的方法能够生成多个候选提示,并从中选择最优的提示,从而更充分地利用已学习的策略库。Beam Search方法通过探索策略组合,进一步提升了攻击效果。
关键设计:Best-of-N方法中,N的选择是一个关键参数,需要根据计算资源和攻击效果进行权衡。评分器模型用于评估候选攻击提示的有效性,其性能直接影响最终的攻击效果。Beam Search方法中,beam size的选择决定了搜索空间的大小,需要根据计算资源和攻击效果进行调整。论文中没有明确给出损失函数和网络结构的具体细节,这部分信息未知。
🖼️ 关键图片


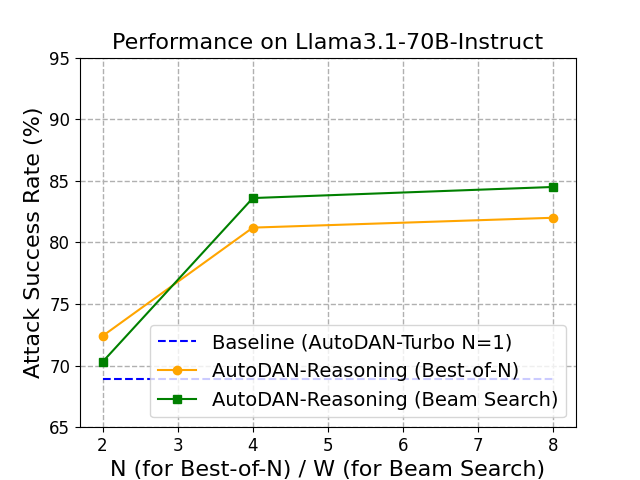
📊 实验亮点
实验结果表明,提出的Best-of-N和Beam Search方法显著提升了LLM的越狱攻击成功率。Beam Search在Llama-3.1-70B-Instruct上的攻击成功率提高了15.6个百分点。针对高度鲁棒的GPT-o4-mini,与原始方法相比,实现了近60%的相对改进。这些结果表明,测试时缩放是一种有效的LLM越狱攻击增强方法。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性,帮助开发者发现模型潜在的漏洞并进行修复。此外,该技术也可用于构建更强大的对抗性防御机制,提高模型在恶意攻击下的鲁棒性。该研究对于保障LLM的可靠性和安全性具有重要意义。
📄 摘要(原文)
Recent advancements in jailbreaking large language models (LLMs), such as AutoDAN-Turbo, have demonstrated the power of automated strategy discovery. AutoDAN-Turbo employs a lifelong learning agent to build a rich library of attack strategies from scratch. While highly effective, its test-time generation process involves sampling a strategy and generating a single corresponding attack prompt, which may not fully exploit the potential of the learned strategy library. In this paper, we propose to further improve the attack performance of AutoDAN-Turbo through test-time scaling. We introduce two distinct scaling methods: Best-of-N and Beam Search. The Best-of-N method generates N candidate attack prompts from a sampled strategy and selects the most effective one based on a scorer model. The Beam Search method conducts a more exhaustive search by exploring combinations of strategies from the library to discover more potent and synergistic attack vectors. According to the experiments, the proposed methods significantly boost performance, with Beam Search increasing the attack success rate by up to 15.6 percentage points on Llama-3.1-70B-Instruct and achieving a nearly 60% relative improvement against the highly robust GPT-o4-mini compared to the vanilla method.