Efficient Prediction of Pass@k Scaling in Large Language Models
作者: Joshua Kazdan, Rylan Schaeffer, Youssef Allouah, Colin Sullivan, Kyssen Yu, Noam Levi, Sanmi Koyejo
分类: cs.AI, cs.LG, stat.AP, stat.ML
发布日期: 2025-10-06
💡 一句话要点
提出基于Beta-Binomial分布的Pass@k预测方法,提升大语言模型能力与风险评估效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 Pass@k 能力评估 风险预测 Beta-Binomial分布 动态采样 模型安全
📋 核心要点
- 现有Pass@k scaling预测方法在数据量有限时存在统计缺陷,导致预测精度下降,无法准确评估模型能力和风险。
- 论文提出基于Beta-Binomial分布的鲁棒估计框架,并结合动态采样策略,提升有限数据下的预测准确性和效率。
- 实验表明,该方法能以更低的计算成本,更可靠地预测大语言模型在大量尝试下的能力和风险。
📝 摘要(中文)
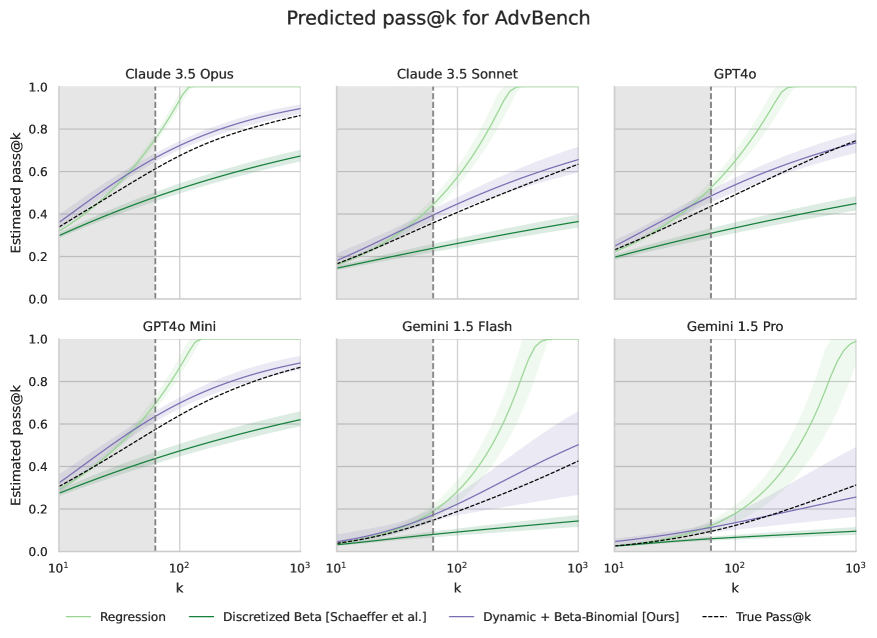
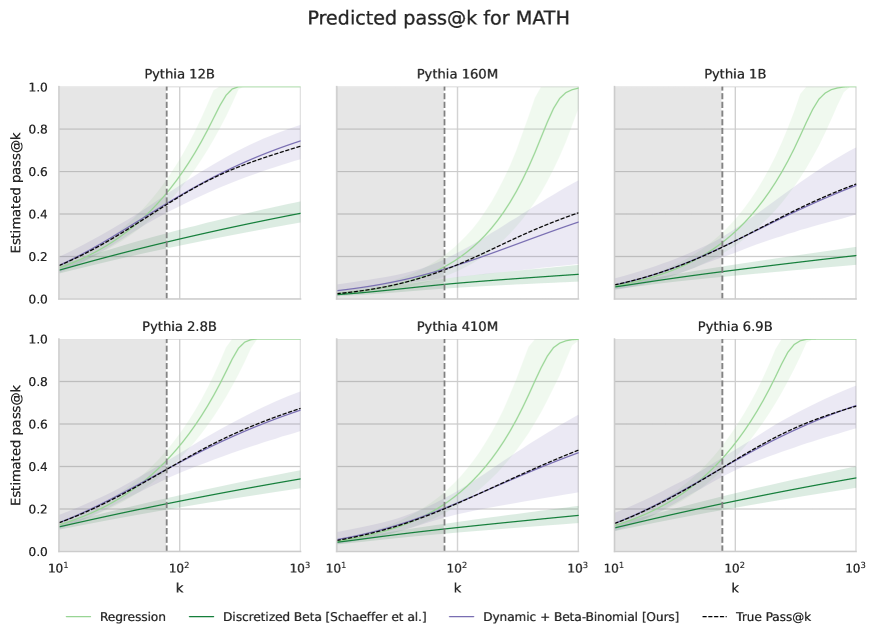
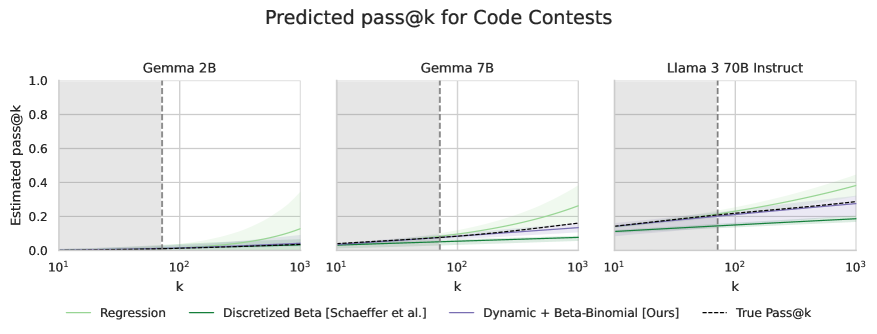
评估前沿AI系统的能力和风险是一个关键的研究领域,而重复采样已被证明可以显著提高模型的能力和潜在危害。例如,重复采样可以提高模型解决复杂数学和编码问题的能力,但也可能增加模型被破解的风险。因此,如何用远小于实际部署的采样预算,准确预测模型在大量尝试下的行为,对于能力和安全预测至关重要。本文提出了三个贡献:首先,发现标准方法在拟合Pass@k scaling时存在统计缺陷,尤其是在数据有限的情况下会降低预测精度。其次,通过引入一个鲁棒的估计框架来弥补这些缺陷,该框架使用beta-binomial分布,从有限的数据中生成更准确的预测。第三,提出了一种动态采样策略,将更多的预算分配给更难的问题。总而言之,这些创新能够以一小部分的计算成本更可靠地预测罕见的风险和能力。
🔬 方法详解
问题定义:论文旨在解决如何高效预测大型语言模型在多次尝试(Pass@k)下的表现,尤其是在计算资源有限的情况下。现有方法,例如直接拟合幂律曲线,在数据量不足时容易出现过拟合,导致预测结果不准确,无法有效评估模型的能力和潜在风险。
核心思路:论文的核心思路是利用Beta-Binomial分布对Pass@k的成功概率进行建模,并结合动态采样策略,从而在有限的采样预算下获得更准确的预测结果。Beta-Binomial分布能够更好地捕捉成功概率的不确定性,降低过拟合风险。动态采样策略则将更多的计算资源分配给更难的问题,提高采样效率。
技术框架:整体框架包含以下几个主要阶段:1) 数据收集:对语言模型进行少量采样,记录每个问题在不同尝试次数下的成功与失败情况。2) 模型拟合:使用Beta-Binomial分布对每个问题的成功概率进行建模,并利用收集到的数据进行参数估计。3) 预测:基于拟合的Beta-Binomial分布,预测模型在更大尝试次数下的Pass@k值。4) 动态采样:根据已有的预测结果,动态调整采样策略,将更多的计算资源分配给预测难度较高的问题。
关键创新:最重要的技术创新点在于使用Beta-Binomial分布对Pass@k的成功概率进行建模。与传统的直接拟合方法相比,Beta-Binomial分布能够更好地处理数据量有限的情况,降低过拟合风险,并提供更准确的预测结果。此外,动态采样策略也提高了采样效率,降低了计算成本。
关键设计:Beta-Binomial分布的参数估计采用最大似然估计方法。动态采样策略根据问题的预测难度(例如,预测Pass@k值的方差)来分配采样预算。具体而言,对于预测难度较高的问题,分配更多的采样次数,以提高预测精度。损失函数采用负对数似然函数,用于优化Beta-Binomial分布的参数。
🖼️ 关键图片
📊 实验亮点
论文提出的方法在有限数据下显著提升了Pass@k scaling的预测精度。实验结果表明,与传统方法相比,该方法能够更准确地预测模型在大量尝试下的表现,尤其是在数据量较少的情况下。此外,动态采样策略有效地降低了计算成本,使得在有限的计算资源下进行大规模模型评估成为可能。
🎯 应用场景
该研究成果可应用于大语言模型的安全评估、能力预测和资源优化。模型提供商可以利用该方法更高效地评估模型的风险,政府监管机构可以更好地预测模型的潜在危害,从而制定更有效的监管策略。此外,该方法还可以用于优化模型的训练过程,提高模型的性能。
📄 摘要(原文)
Assessing the capabilities and risks of frontier AI systems is a critical area of research, and recent work has shown that repeated sampling from models can dramatically increase both. For instance, repeated sampling has been shown to increase their capabilities, such as solving difficult math and coding problems, but it has also been shown to increase their potential for harm, such as being jailbroken. Such results raise a crucial question for both capability and safety forecasting: how can one accurately predict a model's behavior when scaled to a massive number of attempts, given a vastly smaller sampling budget? This question is directly relevant to model providers, who serve hundreds of millions of users daily, and to governmental regulators, who seek to prevent harms. To answer this questions, we make three contributions. First, we find that standard methods for fitting these laws suffer from statistical shortcomings that hinder predictive accuracy, especially in data-limited scenarios. Second, we remedy these shortcomings by introducing a robust estimation framework, which uses a beta-binomial distribution to generate more accurate predictions from limited data. Third, we propose a dynamic sampling strategy that allocates a greater budget to harder problems. Combined, these innovations enable more reliable prediction of rare risks and capabilities at a fraction of the computational cost.